标签:
一、大数据hadoop的学习框架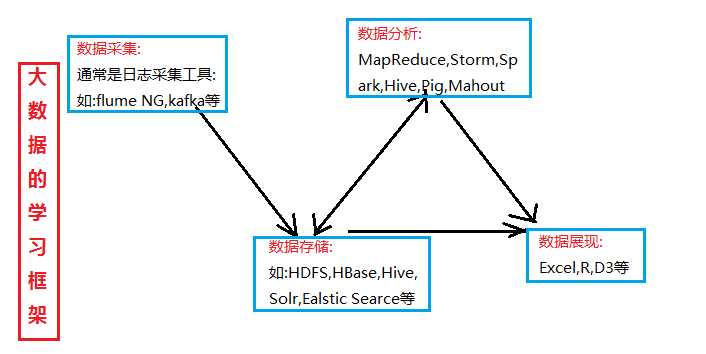
二、云计算与大数据
云计算的架构
问题一、为了解决企业中的业务问题,我们开发人员处于第二层。
问题二、云计算与大数据的关系与区别(待解决)
三、大数据与机器学习
模式识别源于工业界
数据挖掘:工具+存储
统计学习:偏数学方面多
计算机视觉:图像识别+机器学习
语音识别:语音识别+机器学习
自然语言处理:文字识别+机器学习
随着大数据的发展,运算处理能力随着随着加强。从而让,机器学习的发展也越来越快了。
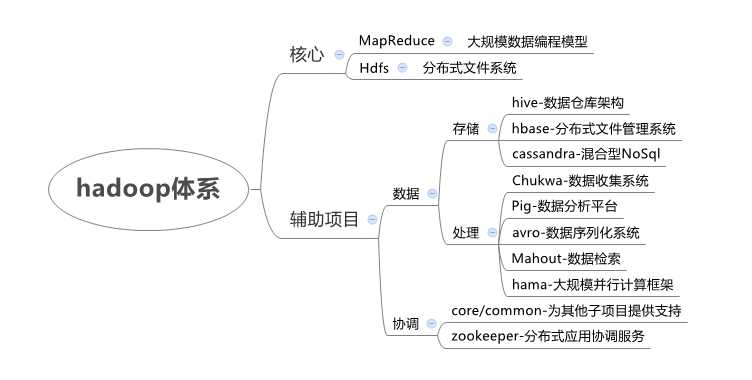
四、什么是Hadoop?
Hadoop是适合大数据的分布式存储与计算平台。
(hadoop的作者是:Doug Cutting、他受Google的三篇论文的启发,搞出了个这么牛逼的Hadoop)
1.数据的分布式存储
---| 为什么会出现这样的数据存储系统?
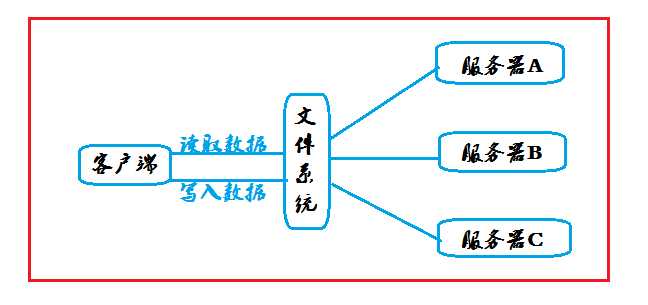
因为,当数据量越来越多的时候,如果只是增加单台服务器的存储容量,到了后面,随着容量的增加,服务器的价格随着指数增长,这样并不经济划算。因此,选择增加多台服务器来分别存储数据。
---|当服务器的数量增多的时候,如何快速的找到属于自己的数据呢?
这个问题非常重要,为了解决这个问题,就出现了文件管理系统。这个文件管理系统中,仅仅存放了所有数据的索引,映射关系。当客户端想要读取自己要的数据的时候,就在文件系统中检索,找到这个映射关系后,就直接去对应的服务器中读取数据。
---|分布式存储系统必须跨服务器
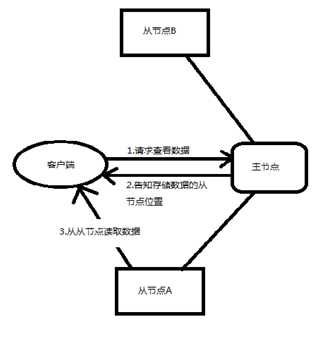
2、命名空间与主从式结构
在分布式文件管理系统中,分散在不同节点中的数据可能属于同一个文件,为了方便的组织管理众多的文件,把文件可以放到不同的文件夹中,文件夹之间可以一级一级的包含。这样的组织形式称为命名空间(namespace)。命名空间管理着整个服务器集群的所有文件。
集群中不同的节点承担着不同的职责。负责命名空间职责的节点我们称为主节点(master node)。负责存储真实数据职责的节点我们称为从节点(slave node)。主节点负责管理文件系统中的文件结构。从节点负责存储真实的数据,这样的结构,我们称为主从式结构(master-slave).
。用户操作时,应该先和主节点打交道。查询数据在哪些从节点上存储,然后再从从节点中读取数据。在主节点,为了加快用户访问的速度,会把把整个命名空间的信息都放到内存中,当存储的文件越来越多的时候,那么主节点就需要越多的内存空间。在从节点存储数据时,有的原始数据文件可能很大,有的可能很小。大小不一的文件不容易管理,那么可以抽象出一个单独的存储文件单位,称为块(block)。数据存放在集群中,可能因为网络原因或者节点硬件原因造成访问失败,最好采用副本(replication)机制。把数据同时备份到多台节点中,这样数据就安全了,数据丢失或者访问失败的概率就笑了。
(关键字:主从节点的职责,主从式结构。为了提高访问速度主节点信息存放到内存中,为了方便大小不一的文件管理,抽象出块。为了数据安全,采用副本机制。)
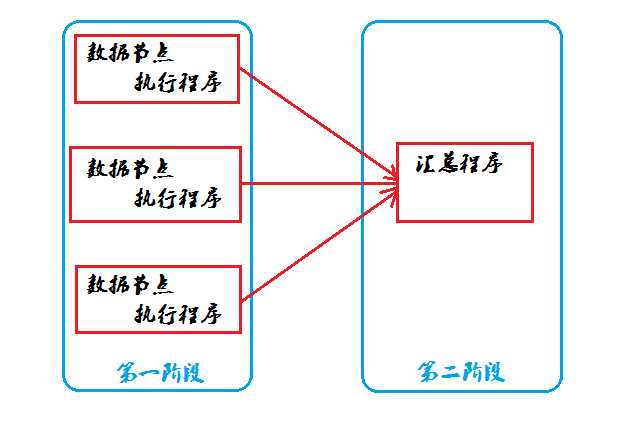
3、数据的分布式计算
为什么会有数据的分布式计算?
因为数据量非常多的时候,所有的数据都在一个机器上运算,会给机器造成非常大的压力,并且效率也低。为了解决这个问题,我们让数据在各自的节上先进行运算,这是第一阶段。然后再把各个节点运算的数据汇总起来,再进行运算,这就是第二阶段。
分布是计算提高了计算的速度,也保证了数据的完整性。
4、分布式系统中的软件和硬件。
一个问题,我们平常所说的服务器是软件还是硬件?
很明显,在不同的情境下,服务器可能是软件,可能是硬件。所以看下面
---| 各种分布式框架是软件层面的设计
---|当把这些框架部署到服务器集群时,考虑的是硬件方面。
---|分布式框架可以部署在一台机器上,也可以部署在集群上。
五、Hadoop1和Hadoop2
1.hadoop1的核心项目
Hdfs:Hadoop Distributed File System 分布式文件管理系统
MapReduce:分布式计算模型
2.hadoop2的核心项目
Hdfs:分布式文件管理系统(与hadoop1的hdfs有不同之处)
Yarn:资源管理平台,在上面运行分布式计算,典型的计算模型有MapReduce、Storm、Spark等(这是hadoop2新增的部分)
MapReduce:分布式计算模型(与hadoop1的mapreduce也有不同之处)
3.简单介绍hadoop2的核心项目
HDFS的架构:负责数据的分布式存储
主从结构:
主节点、可以有2个:namenode(接受用户的操作请求,是用户操作的入口。维护文件系统的目录结构,也就是命名空间)
从节点、有很多个:datanode(存储文件)
Yarn的架构:资源的调度与管理平台
主从式结构:
主节点、可以有2个:ResourceManager(集群资源的分配与调度 mapreduce,spark等应用,必须实现Application接口,才能被RM管理)
从节点、可以有很多个:NodeManager(单节点资源的管理 )
MapReduce的架构:依赖磁盘IO的批处理极端模型
主从结构:
主节点、只有一个:JobTracker(接收客户提交的计算任务,把计算任务分给TaskTracker执行,监控TaskTracker的执行情况)
从节点、有很多个:TaskTracker(执行JobTracker分配的计算任务)
4.hadoop1中的MapReduce与hadoop2中的MapReduce的不同
说明:在hadoop1中还没有Yarn架构,因此也就没有管理资源的节点
六、Hadoop的特点
扩容能力(Scalable):能可靠地(reliably)存储和处理千兆字节(PB)数据。
成本低(Economical):可以通过普通机器组成的服务器群来分发以及处理数据。这些服务器群总计可达数千个节点。
高效率(Efficient):通过分发数据,hadoop可以在数据所在的节点上并行地(parallel)处理它们,这使得处理非常的快速。
可靠性(Reliable):hadoop能自动地维护数据的多份副本,并且在任务失败后能自动地重新部署(redeploy)计算任务。
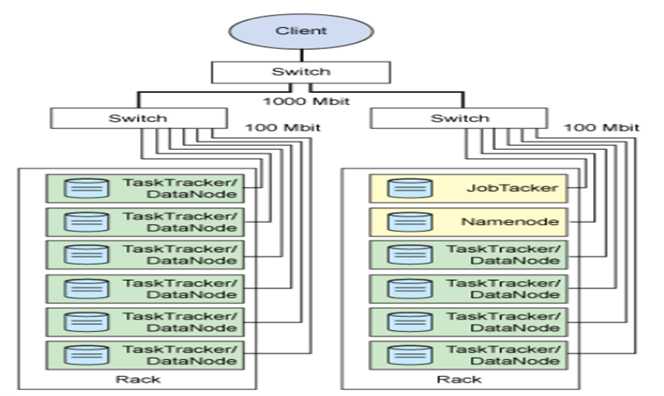
七、Hadoop集群的物理分布
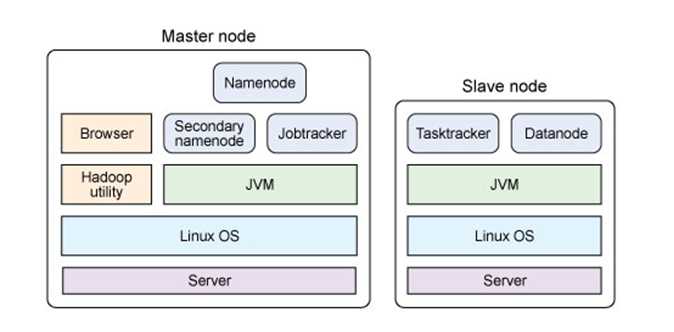
单节点的物理结构
hadoop的简述
标签:
原文地址:http://www.cnblogs.com/hsw-time/p/5093448.html