标签:
将RDD中的每个数据项,一对一的映射关系,RDD数目不变,分区数也不变
例子:
数据集:

map操作:


和map一样,但是会拆分每一个map之后的list,可以理解为一对多(注:会把字符串当作数组然后拆分)
例子:

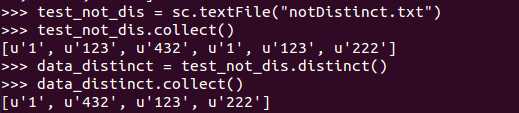
对RDD的数据项进行去重操作
例子:
def coalesce(numPartitions: Int, shuffle: Boolean = false)(implicit ord: Ordering[T] = null): RDD[T]
功能:对RDD进行重分区,使用HashPartitioner。
参数1:重分区的数目
参数2:是否进行shuffle,默认为false(注:一般用coalesce比repartition的好处就是可以不需要shuffle)
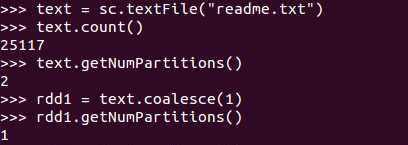
例子:(我虚拟机给了两个核,默认就成两个分区了,并且大于2也不行,或许分区数与可用处理器数量有关,网上有说如果分区大于当前分区就要设参数为true,不过我把分区为1的设为2也成功了,大数据不知道是否可行)
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
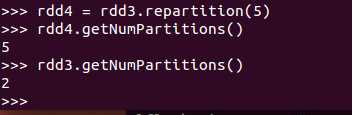
也是重新分区,会进行shuffle工作,给一个分区数就ok了(对于大量小任务,Spark有自己的分区机制,如果强制设为一些较小的分区数,说不定可以加快程序)
例子
def randomSplit(weights: Array[Double], seed: Long = Utils.random.nextLong): Array[RDD[T]]
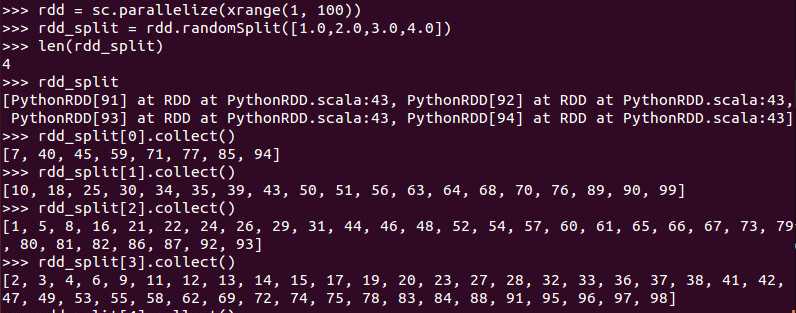
将一个RDD随机切分成多个RDD, 切分根据为double数组
第二个参数为random的种子,基本可忽略。
例子:
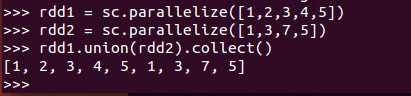
def union(other: RDD[T]): RDD[T]
将两个RDD合并,不去重
例子:
返回两个RDD的交集,并且去重
def intersection(other: RDD[T]): RDD[T]
def intersection(other: RDD[T], numPartitions: Int): RDD[T]
def intersection(other: RDD[T], partitioner: Partitioner)(implicit ord: Ordering[T] = null): RDD[T]
numPartitions:指定返回的RDD的分区数。
partitioner:指定分区函数
例子:

返回在RDD出现但是不在otherRDD出现的数据项集合,不去重
def subtract(other: RDD[T]): RDD[T]
def subtract(other: RDD[T], numPartitions: Int): RDD[T]
def subtract(other: RDD[T], partitioner: Partitioner)(implicit ord: Ordering[T] = null): RDD[T]
例子:

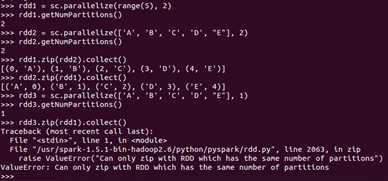
def zip[U](other: RDD[U])(implicit arg0: ClassTag[U]): RDD[(T, U)]
作用:将两个RDD组合成Key/Value形式的RDD
注意:默认两个RDD的partition数量以及元素数量都相同,否则会抛出异常
例子:
def zipWithIndex(): RDD[(T, Long)]
将RDD中的元素和这个元素在RDD中的ID(索引号)组合成键/值对(可用于编号)(不同机器可能会冲突)
例子:

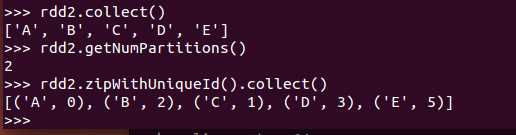
def zipWithUniqueId(): RDD[(T, Long)]
该函数将RDD中元素和一个唯一ID组合成键/值对,该唯一ID生成算法如下:
每个分区中第一个元素的唯一ID值为:该分区索引号,
每个分区中第N个元素的唯一ID值为:(前一个元素的唯一ID值) + (该RDD总的分区数)
例子:(尽管在不同的机器中分别编号,整个RDD中也不会重复,注意区别于zipWithIndex())
def partitionBy(partitioner: Partitioner): RDD[(K, V)]
该函数根据partitioner函数生成新的ShuffleRDD,将原RDD重新分区
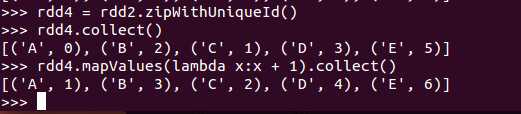
def mapValues[U](f: (V) => U): RDD[(K, U)]
同基本转换操作中的map,只不过mapValues是针对[K,V]中的V值进行map操作
例子:
def flatMapValues[U](f: (V) => TraversableOnce[U]): RDD[(K, U)]
同基本转换操作中的flatMap,只不过flatMapValues是针对[K,V]中的V值进行flatMap操作
例子:

根据key-value中的key将RDD合并,等于key唯一了
def reduceByKey(func: (V, V) => V): RDD[(K, V)]
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)]
该函数用于将RDD[K,V]中每个K对应的V值根据映射函数来运算。
参数numPartitions用于指定分区数;
参数partitioner用于指定分区函数;
例子:

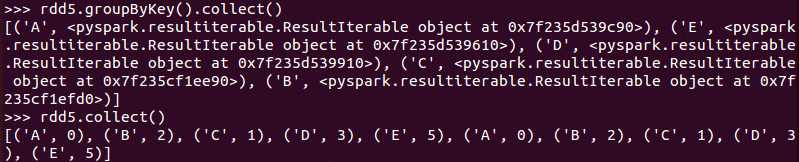
def groupByKey(): RDD[(K, Iterable[V])]
def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])]
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])]
该函数用于将RDD[K,V]中每个K对应的V值,合并到一个集合Iterable[V]中,
参数numPartitions用于指定分区数;
参数partitioner用于指定分区函数;
例子:
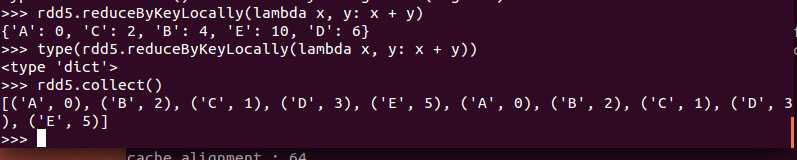
def reduceByKeyLocally(func: (V, V) => V): Map[K, V]
该函数将RDD[K,V]中每个K对应的V值根据映射函数来运算,运算结果映射到一个Map[K,V]中,而不是RDD[K,V]。(在python中其实是dictionary)
例子:
subtractByKey和基本转换操作中的subtract类似
这里是针对K的,返回在主RDD中出现,并且不在otherRDD中出现的元素。
参数numPartitions用于指定结果的分区数
参数partitioner用于指定分区函数

运行失败
Spark Programming--Transformations
标签:
原文地址:http://www.cnblogs.com/loadofleaf/p/5090143.html