标签:
saveAsTextFile
saveAsTextFile(path, compressionCodecClass=None)
aveAsTextFile用于将RDD以文本文件的格式存储到文件系统中, 将每一个元素以string格式存储(结合python的loads和dumps可以很好应用)
Parameters:
- path – path to text file
- compressionCodecClass – (None by default) string i.e. “org.apache.hadoop.io.compress.GzipCodec“ 指定压缩的类名
例子:
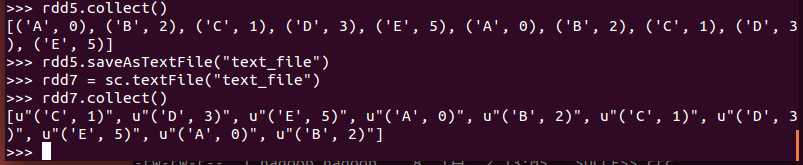

saveAsSequenceFile
sequenceFile(path, keyClass=None, valueClass=None, keyConverter=None, valueConverter=None, minSplits=None, batchSize=0)
Parameters:
- path – path to sequncefile
- keyClass – fully qualified classname of key Writable class (e.g. “org.apache.hadoop.io.Text”)
- valueClass – fully qualified classname of value Writable class (e.g. “org.apache.hadoop.io.LongWritable”)
- keyConverter –
- valueConverter –
- minSplits – minimum splits in dataset (default min(2, sc.defaultParallelism))
- batchSize – The number of Python objects represented as a single Java object. (default 0, choose batchSize automatically)
saveAsSequenceFile用于将RDD以SequenceFile的文件格式保存到HDFS上
存储的时候会默认存储到hdfs上面,会保留原始格式
例子:

查看hdfs上文件,以及get下来后看文件格式:

saveAsHadoopFile
saveAsHadoopDataset
saveAsNewAPIHadoopFile
saveAsNewAPIHadoopDataset
Spark Programming--Actions II
标签:
原文地址:http://www.cnblogs.com/loadofleaf/p/5094583.html