标签:
1. 查找历年最高的温度。
MapReduce任务过程被分为两个处理阶段:map阶段和reduce阶段。每个阶段都以键/值对作为输入和输出,并由程序员选择它们的类型。程序员还需具体定义两个函数:map函数和reduce函数。
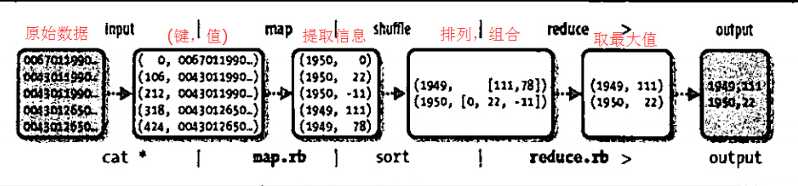
对应的Java MapReduce代码如下:
public class MaxTemperature{ static class MaxTemperatureMapper extends Mapper<LongWritable,Text,Text,IntWritable>{ public void map(LongWritable key, Text value,Context context) throws IOException,InterruptedException{ String line = value.toString(); String year = line.substring(15,19); int airTemperature; if(line.charAt(87) == ‘+‘){ airTemperature = Integer.parseInt(line.substring(88, 92)); } else { airTemperature = Integer.parseInt(line.substring(87, 92)); } String quality = line.substring(92, 93); if(airTemperature != MISSING && quality.matches("[01459]")){ context.write(new Text(year),new IntWritable(airTemperature)); } } } static class MaxTemperatureReducer extends Reduce<Text,IntWritable,Text,IntWritable>{ public void reduce(Text key,Iterable<IntWritable> values, Context context) throws IOException,InterruptedException{ int maxValue = Inerger.MIN_VALUE; for(IntWritable value : values){ maxValue = Math.max(maxValue,value.get()); } context.write(key,new IntWritable(maxValue)); } } public static void main(String[] args) throws Exception{ if(args.length != 2){ System.out.println("Usage: MaxTemperature <input path> <output path>"); System.exit(-1); } Job job = new Job(); job.setJarByClass(MaxTemperature.class); FileInputFormat.addInputPath(job,new Path(args[0])); FileOutputFormat.setOutputPath(job,new Path(args[1])); job.setMapperClass(MaxTemperatureMapper.class); job.setReducerClass(MaxTemperatureReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); System.exit(job.waitForCompletion(true)?0:1); } }
2. 为了实现横向扩展,需要把数据存储在分布式文件系统HDFS中,由此允许hadoop将MapReduce计算移到存储有部分数据的各台机器上。
(1) 一个reduce任务的MapReduce数据流
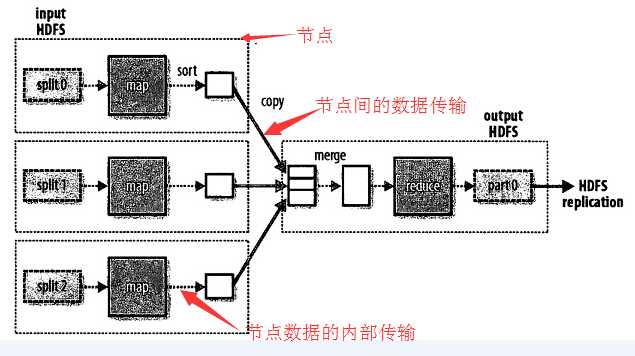
MapReduce作业(job)是客户端需要执行的一个工作单元:包括输入数据、MapReduce程序和配置信息。Hadoop将作业分成若干个小任务(task)来执行,其中包括两类任务:map任务和reduce任务。
有两类节点控制着作业执行过程:一个jobtracker及一系列tasktracker。jobtracker通过调度tasktracker上运行的任务,来协调所有运行在系统上的作业。tasktracker在运行任务的同时将运行进度报告发送给jobtracker,jobtracker由此记录每项作业任务的整体进度情况。如果其中一个任务失败,jobtracker由此在另外一个tasktracker节点上重新调度该任务。
Hadoop将MapReduce的输入数据划分成等长的小数据块,成为输入分片(input split)。Hadoop为每个分片构建一个map任务,并由该任务来运行用户自定义的map函数从而处理分片中的每条记录。
如果我们并行处理每个分片,且每个分片数据比较小,那么整个处理过程将获得更好的负载平衡。对于大多数作业来说,一个合理的分片大小趋向于HDFS的一个块的大小,默认是64M。
Hadoop在存储有输入数据(HDFS中的数据)的节点上运行map任务,可以获得最佳的性能,这就是所谓的数据本地化优化(data locality optimization)。最佳分片的大小应该与块大小相同,因为它是确保可以存储在单个节点上的最大输入块的大小。如果分片跨越两个数据块,那么对于任何一个HDFS节点,基本上都不可能同时存储这两个数据块,因此分片中的部分数据需通过网络传输到map任务节点。
map任务将其输出写入本地硬盘,而非HDFS,因为map的输出结果是中间结果,该中间结果由reduce任务处理后才产生最终输出结果,而一旦作业完成,map的输出结果可以被删除。因此,如果把它存储在HDFS中并实现备份难免有些小题大做。如果该节点上运行的map任务在map中间结果传送给reduce任务之前失败,Hadoop将在另一个节点上重新运行这个map任务以再次构建map中间结果。
reduce任务并不具备数据本地化的优势-单个reduce任务的输入通常来自于所有mapper的输出。因此,上例中排过序的map输出需要通过网络传输发送到运行reduce任务的节点。数据在reduce端合并,然后由用户定义的reduce函数处理。reduce的输出通常存储在HDFS中以实现可靠存储。对于每个reduce输出的HDFS数据块,第一个复本存储在本地节点上,其他复本存储在其他机架节点中。
(2) 多个reduce任务的数据流
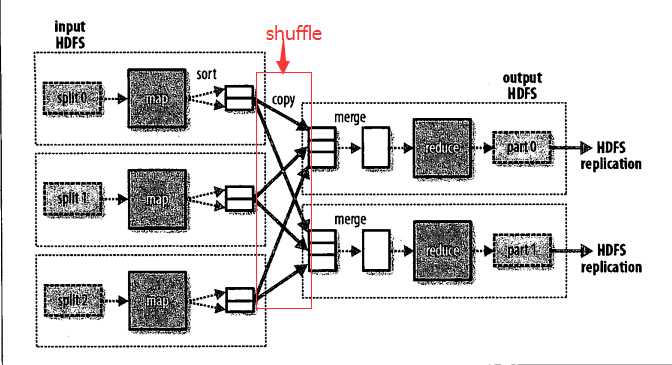
reduce任务的数量并非由输入数据的大小决定,而是特别指定的。如果有多个reduce任务,则每个map任务都会对其输出进行分区,即为每个reduce任务建一个分区。每个分区有许多键(及其对应值),但每个键对应的键/值对都在同一个分区中,分区由用户定义的分区函数控制,但通常用默认的分区器通过哈希函数来区分。
(3) 无reduce任务的MapReduce数据流
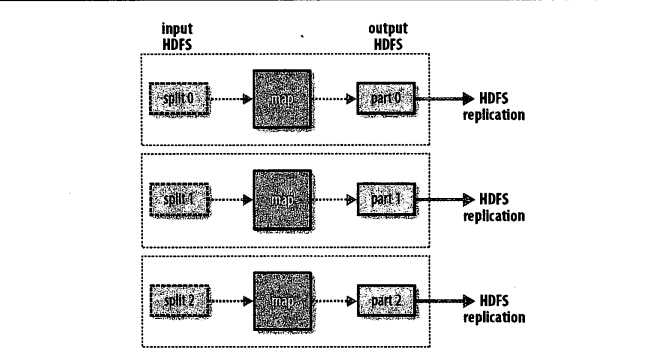
在这种情况下,唯一的非本地节点数据传输是map任务将结果写入HDFS。
3. combiner
集群上的可用带宽限制了MapReduce作业的数量,因此尽量避免map任务和reduce任务之间的数据传输。Hadoop允许用户针对map任务的输出指定一个合并函数——合并函数的输出作为reduce函数的输入。Hadoop无法确定针对map任务输出中任一条记录需要调用多少次合并函数。
例:计算最高温度的例子中,1950年的读数由两个map任务处理。假设第一个map的输出为:(1950,0),(1950,20),(1950,10),第二个map的输出为:(1950,25),(1950,15),reduce函数被调用时,输出:(1950,[0 20 10 25 15]),因此reduce函数的输出为(1950,25)。
我们可以像使用reduce函数那样,使用合并函数找出每个map任务输出结果中的最高温度,则reduce函数调用时将被传入:(1950,[20,25])
使用合并函数快速找出最高气温的代码:
public class MaxTemperatureWithCombiner{ public static void main(String[] args) throws IOException{ if(args.length != 2){ System.out.println("Usage: MaxTemperatureWithCombiner <input path> <output path>"); System.exit(-1); } JobConf conf = new JobConf(MaxTemperatureWithCombiner.class); conf.setJobName("Max Temperature"); FileInputFormat.addInputPath(conf,new Path(args[0])); FileOutputFormat.setOutputPath(conf,new Path(args[1])); conf.setMapperClass(MaxTemperatureMapper.class); conf.setReducerClass(MaxTemperatureReducer.class); conf.setCombinerClass(MaxTemperatureReducer.class); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); JobClient.runJob(conf); } }
4. Hadoop的Streaming
Hadoop的Streaming使用unix标准流作为Hadoop和应用程序之间的接口,所以我们可以使用任何编程语言通过标准输入/输出来写MapReduce程序。
标签:
原文地址:http://www.cnblogs.com/mengrennwpu/p/4893481.html