标签:
CVPR15:Person Count Localization in Videos from Noisy Foreground and Detections
paper主要的contribution是定义了person count localization及其周边,不过虽然之前提过的person count问题常用结果评估标准是只看最后给出的counts,但其实之前的文章也并不完全是只给出global counts的。文中可能是更加重视这个localization的问题并且确实是利用这个信息去解决问题了,但是这样就要做出一个区分,即首先将问题定义好。
文章提出这个person count localization问题,是对给定视频序列,给出每帧上的detection及其counts,如下图所示:
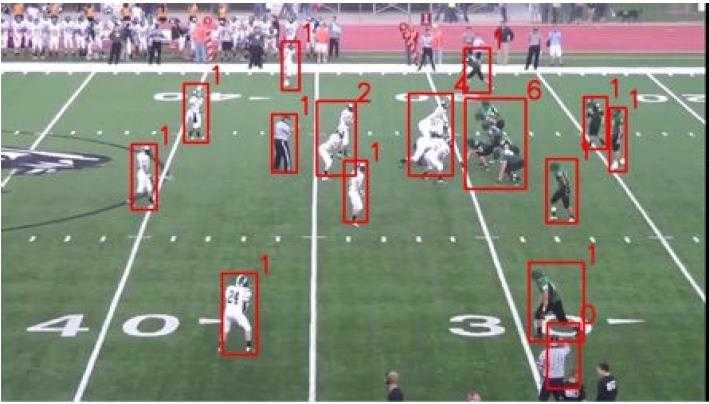
阅读之后很快发现,其实是用MOT的思路解决的。【虽然文章中说,这是middle-ground between frame-level person counting and person detection,但是我更感觉这是粗糙的MOT,至少Error driven Graph Revision部分的思路是一致的】不知道直接在上面跑MOT是什么样的效果~
其实调研之初我在考虑方法时考虑过这个问题,但不知为什么很排斥tracking by detection的方法去解决person count的方法,可能是觉得如果做tracking就专心做tracking吧~之前的代码测试虽然在无情的打击着我对state of art的信心,但还是充满希望~
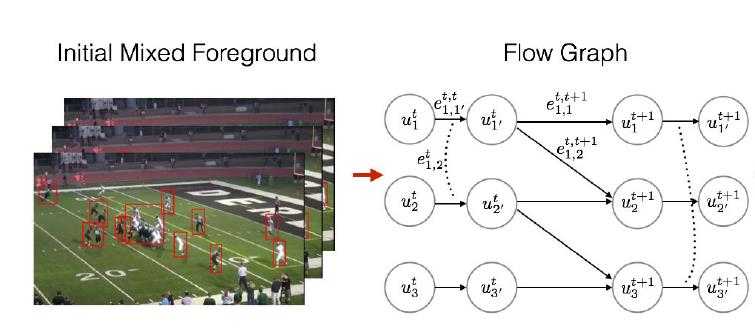
言归正传,paper提出的方法是现在视频上跑一遍person detector and foreground segmentation,两个结果互为补充。然后using both the person detector’s results and the relatively larger connected components from the foreground segmentation构建如下流图,u是detection,e是互联的边,为了更加像一个图,又把同一个u分成两个部分,使得中间也有一个边e连接。它满足图的构造限制,每个边上都会有一个流量x,流入等于流出
然后把NP-complete的问题变成解ILP问题:
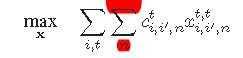
中间的步骤先略去,文章几个位置还没有看懂,比如红字部分为什么要求和?
最后就是利用MOT的思路加边,加节点或者利用tracker补上missing detection,而三种操作的选择方法是训练了一个random forest classifier,略去~这样原来的流图就会发生改变,再次重复这两个步骤至迭代停止条件满足即可~
实验结果评测时由于他加入了位置信息,传统方法不适用,所以提出了自己的评估方法,没什么可说的~但此时回到前面问过的问题,即前面所说的区分,如果跟MOT的结果比呢?
paper reading in 1/1/2016~1/3/2016
标签:
原文地址:http://www.cnblogs.com/xy2012/p/5096991.html