标签:style blog http color 使用 strong
本文是Andrew Ng在Coursera的机器学习课程的笔记。

神经网络模型由输入层(layer 1)、中间层(layer 2,..,L-1)、输出层(layer L)三部分组成。输入层每个单元代表一个特征,输出层的每个单元代表一个类别。
如果我们的目标如果是识别一张20x20像素的图片上写的数字(0~9),那么输入层是一个400维的向量,每一维是某个位置的像素值;输出层的第一个单元输出一个(0,1)之间的数,表示结果属于0的概率,其他单元以此类推。
相邻层间的线都附带权重参数,用 θ 表示。例如,\( \theta_{53}^{(1)} \) 表示Layer1的第3个节点与Layer2的第5个节点的线段的权重,这些权重决定了模型的作用,神经网络的目标就是通过样本来计算权重。
每一个中间层和输出层的节点(图中橙色的圈)都是一个Logistic函数 g(z)=a,例如\( z_1^{(2)} \)表示第二层的第一个节点的输入值,带入Logistic函数得到输出\( a_1^{(2)} \) (a表示activation,激励)。
如果我们将权重参数θ初始化为0,那么训练对每层内部的各个节点的影响都相同,每层内所有点的效用等价于一个节点的效用,需要避免这种情况。解决方法是将权重参数随机初始化为[-ε,ε]之间,ε是预设的一个足够小的值。
% L_in(out): node number inside layer L_in(out). epsilon_init = 0.12; W = rand(L_out, 1 + L_in) * 2 * epsilon_init - epsilon_init;
神经网络的训练的过程与线性回归和逻辑斯蒂回归的过程相似,依然是:
接下来的任务是:对于每一个样本,计算当前模型下该样本的输出,求出代价函数,再根据输出来更新权重参数。
 计算神经网络模型的输出比较简单:
计算神经网络模型的输出比较简单:
需要注意的就是每一步加入的bias项。
定义公式为:
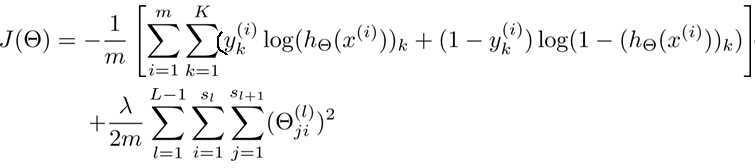
这个公式与逻辑斯蒂回归定义的代价函数比较相似。m是样本的个数,由于神经网络有K个输出,其代价函数也相应地计算了K个输出的代价。公式第二行是为了防止过拟合而设置的。
有了代价函数之后,我们下一个目标就是调整参数,让代价函数最小,使用的方法是反向传播算法。
我们用反向传播算法的目的是为了求代价函数关于各个权重系数的偏导数,以此来更新各个权重系数。反向传播的关键在于链式求导法则。
以右图为例,假如我们要求\( {\partial J}/{\partial \theta_{45}^{(3)}} \),即(第3层,第5节点)到(第4层,第4节点)的边的权重的偏导,我们有:
\( {\partial J}/{\partial \theta_{45}^{(3)}}=[{\partial J}/{\partial a_{4}^{(4)}} * {\partial a_{4}^{(4)}}/{\partial z_{4}^{(4)}}] * {\partial z_{4}^{(4)}}/{\partial \theta_{45}^{(3)}}\)
这就是链式法则的应用。计算右式,有:
① \( {\partial J}/{\partial a_{4}^{(4)}} * {\partial a_{4}^{(4)}}/{\partial z_{4}^{(4)}} = a_4^{(4)} - y_4 \)
② \( {\partial z_{4}^{(4)}}/{\partial \theta_{45}^{(3)}} = a_4 \)
接下来我们继续计算\( {\partial J}/{\partial \theta_{53}^{(2)}} \),即(第2层,第3节点)到(第3层,第5节点)的边的权重的偏导,我们有:
\( {\partial J}/{\partial \theta_{53}^{(2)}}=[[{\partial J}/{\partial a_{1}^{(4)}} * {\partial a_{1}^{(4)}}/{\partial z_{1}^{(4)}}] * {\partial z_{1}^{(4)}}/{\partial a_{5}^{(3)}} * {\partial a_{5}^{(3)}} / {\partial z_{5}^{(3)}}]*{\partial z_{5}^{(3)}} / {\partial \theta_{53}^{(2)}} +{\partial J}/{\partial a_{2}^{(4)}}... \)
可以看出,第L层的偏导公式与第L-1层有很大部分是重叠的,我们可以直接用计算的中间结果,这也就是“传播”的意义。上面公式中,用[中括号]标注的,就是接下来要介绍的 δ .
本段介绍的是δ(L) 与δ(L-1) 之间的关系。
将公式中的[中括号]部分提取出来,得到 \( \delta_j^{(l)} \),即为(第 l 层,第 j 个节点)的error值,照着上面公式替代重叠部分,可以得到:
\( \delta_j^{(l)} \)可以理解为反映了(第 l 层,第 j 个节点)理想值与实际值之间的error。输出层的error就是理想值与实际值的差值;中间层的error由输出层反向传播得到,可以理解为他们各自需要为下一层的error付多少责任。
本段介绍的是δ 与偏导数的关系。对照公式可以得到:
\( \partial J(\theta)/\partial \theta_{ij}^{(l)} = a_j^{(l)}\delta_i^{(l+1)} \)
从这里可以看出,求出一层的δ,就能求出一层的偏导数。
BP传播的原理并不复杂,关键就在于反向传播过程的链式偏导法则的应用。实际使用中,需要注意:
这些东西太久不用肯定会忘的,需要学而时习之。
完整的训练过程如下所示:

利用以上方法训练,很有可能由于某些原因出现bug,导致结果失败。不过,一个简单的梯度检查就能极大程度地排除这些bug。
梯度检查的想法很简单。当我们利用BP算法将所有的样本都过一遍,得到J关于各个θ的梯度值时(易错但比较高效),我们再利用梯度计算,在数值上近似求得梯度值(正确但比较耗时)。比较这两者的值,如果差别不大,就说明BP算法正在正确进行。以下是梯度检查的方法:
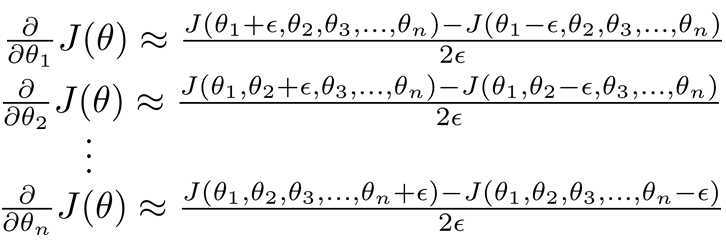
梯度检查比较耗时,所以只能在前几轮中使用梯度检查,之后应该及时关掉梯度检查。
for i = 1:n, thetaPlus = theta; thetaPlus(i) = thetaPlus(i) + EPSILON; thetaMinus = theta; thetaMinus(i) = thetaMinus(i) – EPSILON; gradApprox(i) = (J(thetaPlus) – J(thetaMinus)) /(2*EPSILON); end;
标签:style blog http color 使用 strong
原文地址:http://www.cnblogs.com/ericxing/p/3860707.html