标签:
WEKA是由新西兰怀卡托大学用Java开发的数据挖掘常用软件,WEKA是怀卡托智能分析系统(Waikato Environment for Knowledge Analysis)的缩写。WEKA限制在GNU通用公众证书的条件下发布,它几乎可以运行在所有操作系统平台上,包括Linux、Windows、OS X等。
WEKA作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。
如果想自己实现数据挖掘算法的话,可以参考WEKA的接口文档。在WEKA中集成自己的算法甚至借鉴它的方法自己实现可视化工具,并不是件很困难的事情。
ARFF(Attribute-Relation File Format)文件,一种ASCII文本文件。
关系声明
关系名称在ARFF文件的第一个有效行来定义,格式为@relation 声明字符串。如果这个字符串包含空格,它必须加上引号(指英文标点的单引号或双引号)。
属性声明
属性声明的格式为@attribute <attribute-name> <datatype>
数据集中的每一个属性都有它对应的“@attribute”语句,来定义它的属性名称和数据类型。
这些声明语句的顺序很重要。首先它表明了该项属性在数据部分的位置。其次,最后一个声明的属性被称作class属性,在分类或回归任务中,它是默认的目标变量。
WEKA支持的有四种,分别是
l numeric 数值型
l {<nominal- name1>, <nominal-name2>, ...} 分类(nominal)型
l string 字符串型
l date [<date-format>] 日期和时间型
注意 :“integer”,“real”,“numeric”,“date”,“string”这些关键字是区分大小写的,而 “relation”,“attribute ”和“data”则不区分。
数值属性
数值型属性可以是整数或者实数,但WEKA把它们都当作实数看待。
分类属性(区分大小写)
分类属性由<nominal-specification>列出一系列可能的类别名称并放在花括号中:{<nominal- name1>, <nominal-name2>, <nominal-name3>, ...} 。数据集中该属性的值只能是其中一种类别。
例:如下的属性声明说明“outlook”属性有三种类别:“sunny”,“ overcast”和“rainy”。而数据集中每个实例对应的“outlook”值必是这三者之一。
@attribute outlook {sunny, overcast, rainy}
字符串属性(区分大小写)
字符串属性中可以包含任意的文本。这种类型的属性在文本挖掘中非常有用。
例:@attribute LCC string
日期和时间属性
日期和时间属性统一用“date”类型表示。
例:@attribute <name> date [<date-format>]
其中<name>是这个属性的名称,<date-format>是一个字符串,来规定该怎样解析和显示日期或时间的格式,默认的字符串是ISO-8601所给的日期时间组合格式“yyyy-MM-ddTHH:mm:ss”。数据信息部分表达日期的字符串,必须符合声明中规定的格式要求。
数据信息
数据信息中“@data”标记独占一行,剩下的是各个实例的数据。每个实例占一行。实例的各属性值用逗号“,”隔开。如果某个属性的值是缺失值(missing value),用问号“?”表示,且这个问号不能省略。
例如:
@data
Sunny, 85, 85, FALSE, no
? ,78,90,?,yes
稀疏数据
有的时候数据集中含有大量的0值(比如购物篮分析),这个时候用稀疏格式的数据存贮更加省空间。稀疏格式是针对数据信息中某个实例的表示而言,不需要修改ARFF文件的其它部分。
例:
@data
0, X, 0, Y, "class A"
0, 0, W, 0, "class B"
用稀疏格式表达的话就是
@data
{1 X, 3 Y, 4 "class A"}
{2 W, 4 "class B"}
注意:在稀疏格式中没有注明的属性值不是缺失值,而是0值。若要表示缺失值,必须显式的用问号表示出来。
Relational型属性
在WEKA 3.5版中增加了一种属性类型叫做Relational,有了这种类型我们可以像关系型数据库那样处理多个维度了。但是这种类型目前还不见广泛应用,暂不作介绍。
(一).* ---> .csv(注意第一行是“属性名”)
a) Excel的XLS文件另存为CSV文件。
b) 在Matlab中的二维表格是一个矩阵,我们通过这条命令把一个矩阵存成CSV格式:
csvwrite(‘filename‘,matrixname)
(二)下载地址:http://sourceforge.net/projects/weka/files
(三) WEKA所带的命令行工具
(四) “Explorer”界面
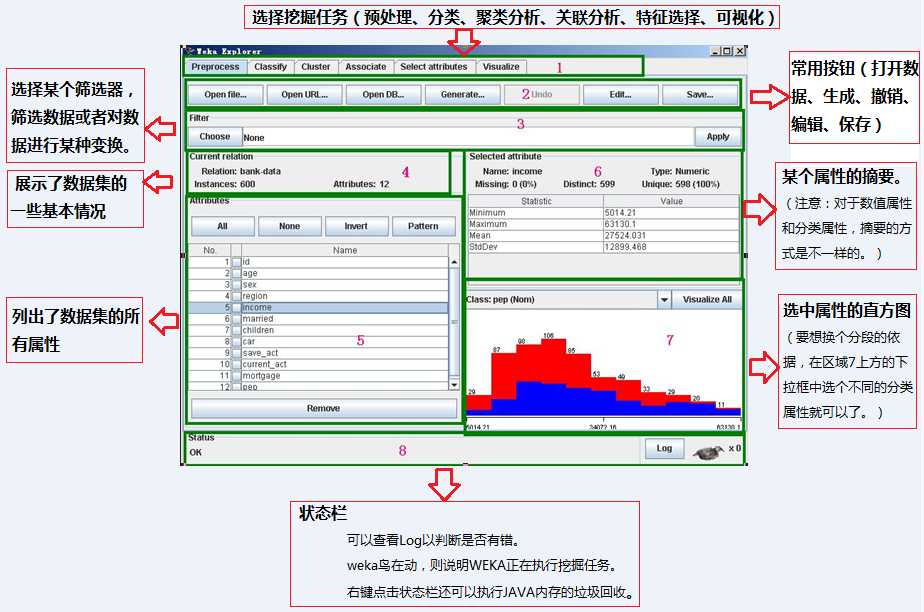
(五)预处理
bank-data数据各属性的含义如下:
id a unique identification number
age age of customer in years (numeric)
sex MALE / FEMALE
region inner city/rural/suburban/town
income income of customer (numeric)
married is the customer married (YES/NO)
children number of children (numeric)
car does the customer own a car (YES/NO)
save_acct does the customer have a saving account (YES/NO)
current_acct does the customer have a current account (YES/NO)
mortgage does the customer have a mortgage (YES/NO)
pep did the customer buy a PEP after the last mailing
(YES/NO)
1、通常对于数据挖掘任务来说,ID这样的信息是无用的,我们将之删除。在区域5勾选属性“id”,并点击“Remove”。
有些算法,只能处理所有的属性都是分类型的情况。这时候我们就需要对数值型的属性进行离散化。在这个数据集中有3个变量是数值型的,分别是“age”,“income”和“children”。
2、其中“children”只有4个取值:0,1,2,3。这时我们在Ultra-Edit中直接修改ARFF文件,把
@attribute children numeric
改为
@attribute children {0,1, 2, 3}
3、“age”和“income”的离散化我们需要借助WEKA中名为“Discretize”的Filter来完成。
“weka.filters.unsupervised.attribute.Discretize”
点击“Choose”旁边的文本框,会弹出新窗口以修改离散化的参数。关于它们的意思可以点“More”查看。若想放弃离散化可以点区域2的“Undo”。
如果对“"(-inf-34.333333]"”这样晦涩的标识不满,我们可以用Ultra-Edit打开保存后的ARFF文件,把所有的“‘\‘(-inf-34.333333]\‘‘”替换成“0_34”。其它标识做类似地手动替换。
标签:
原文地址:http://www.cnblogs.com/sweetyu/p/5098145.html