标签:
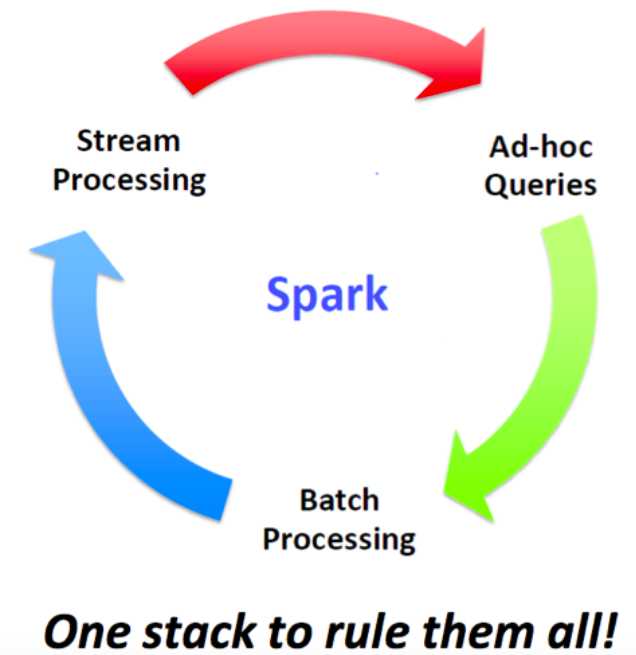
Apache Spark is an open source cluster computing system that aims to make data analytics fast — both fast to run and fast to write.
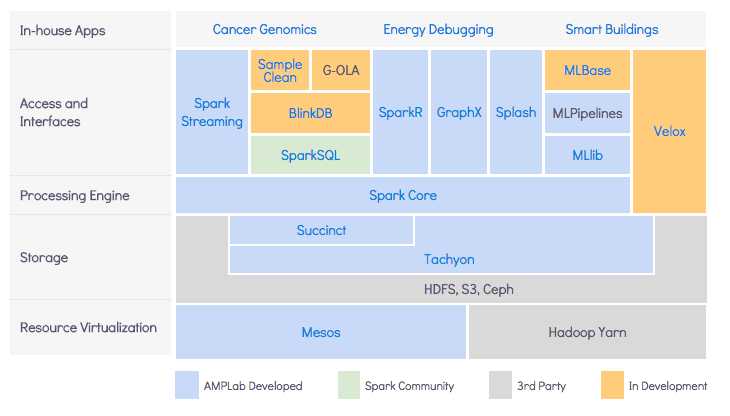
BDAS, the Berkeley Data Analytics Stack, is an open source software stack that integrates software components being built by the AMPLab to make sense of Big Data.
 ?
?
| Spark Components | VS. | Hadoop Components |
|---|---|---|
| Spark Core | <------> | Apache Hadoop MR |
| Spark Streaming | <------> | Apache Storm |
| Spark SQL | <------> | Apache Hive |
| Spark GraphX | <------> | MPI(taobao) |
| Spark MLlib | <------> | Apache Mahout |
BlinkDB is a massively parallel, approximate query engine for running interactive SQL queries on large volumes of data. It allows users to +, enabling interactive queries over massive data by running queries on data samples and presenting results annotated with meaningful error bars.
Two key ideas:
Why spark is fast:
class StorageLevel private(
private var useDisk_ : Boolean,
private var useMemory_ : Boolean,
private var deserialized_ : Boolean,
private var replication_ : Int = 1)
val MEMORY_ONLY_ = new StorageLevel(false, true, true)
lazy evaluation
 ?
?
标签:
原文地址:http://www.cnblogs.com/rainbow203/p/Spark-da-shu-ju-ping-tai.html
 ?
?