标签:
转载或借鉴请注明转自 http://www.cnblogs.com/FG123/p/5101733.html 谢谢!
1.安装Spark之前需要先安装Java,Scala及Python(个人喜欢用pyspark,当然你也可以用原生的Scala)
首先安装Java jdk:
我们可以在Oracle的官网下载Java SE JDK,下载链接:http://www.oracle.com/technetwork/java/javase/downloads/index.html。
最好是下载最新版本,下载完解压,配置环境变量等,可以查看是否安装好
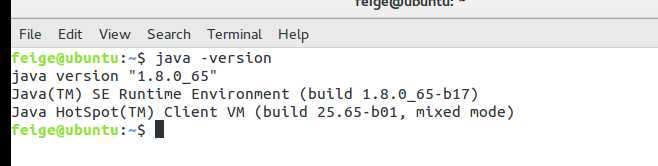
然后安装Scala:
这里我们下载最新版本2.11.7的Scala安装 Scala官网下载地址:http://www.scala-lang.org/download/
然后我们执行:
tar zxvf scala-2.11.7.tgz
sudo mv scala-2.11.7 /opt/
解压后测试scala命令,并查看版本:

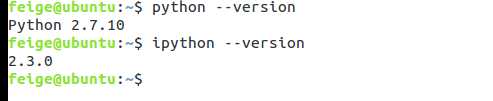
然后安装Python及IPython:
sudo apt-get install python ipython
查看他们的版本信息:
安装spark:
Spark官方下载链接:http://spark.apache.org/downloads.html 我下的是Spark 1.5.1
下载后解压并拷贝到/opt/目录:
tar zxvf spark-1.5.1-bin-hadoop2.6.tgz
sudo mv spark-1.5.1-bin-hadoop2.6 /opt/source ~/.zshrc
配置路径到PATH环境变量中:
echo "export PATH=$PATH:/opt/spark-1.5.1-bin-hadoop2.6/bin" >> ~/.bashrc
source ~/.bashrc
测试下spark-shell的位置是否可以找到 :

进入spark配置目录进行配置:
cd /opt/spark-1.5.1-bin-hadoop2.6/conf
cp log4j.properties.template log4j.properties
修改 log4j.rootCategory=WARN, console
sudo cp spark-env.sh.template spark-env.sh
设置spark的环境变量,进入spark-env.sh文件添加:
export SPARK_HOME=/opt/spark-1.5.1-bin-hadoop2.6
export SCALA_HOME=/opt/scala-2.11.7
至此,Spark就已经安装好了
运行spark:
Spark-Shell命令可以进入spark,可以使用Ctrl D组合键退出Shell:

我们可以看到进入的是Scala状态下的spark
如果习惯用python 我们可以运行pyspark:
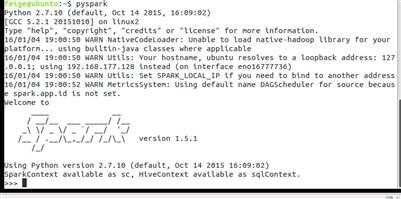
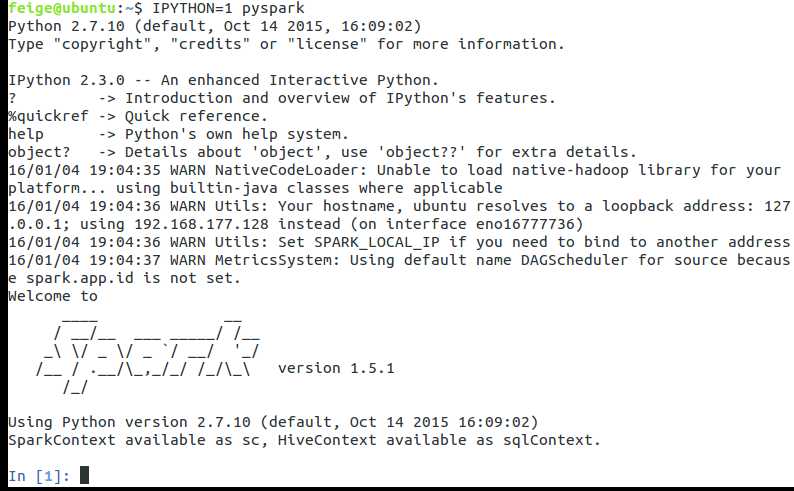
或者直接使用IPython,执行命令:IPYTHON=1 pyspark:

这里我们启动了主结点
如果主节点启动成功,master默认可以通过web访问http://localhost:8080:
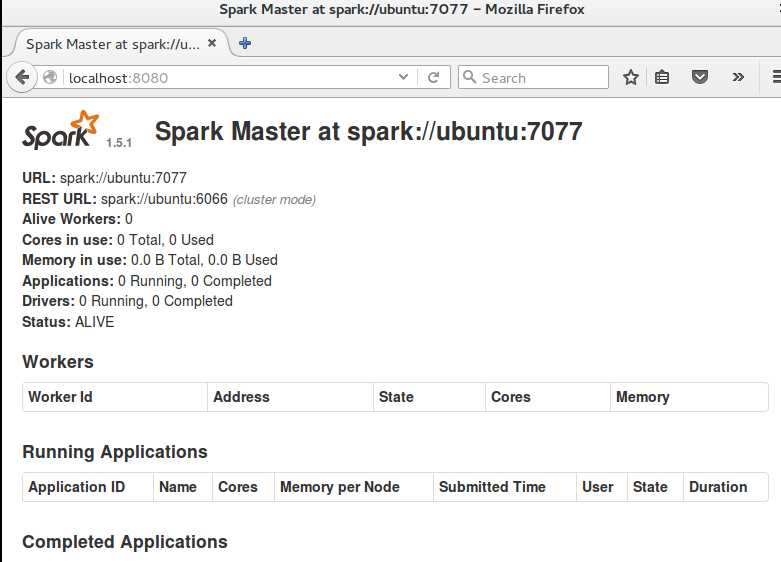
上述的spark://ubuntu:7077 就是从结点启动的参数 我的是Ubuntu 你们的可能是不一样的
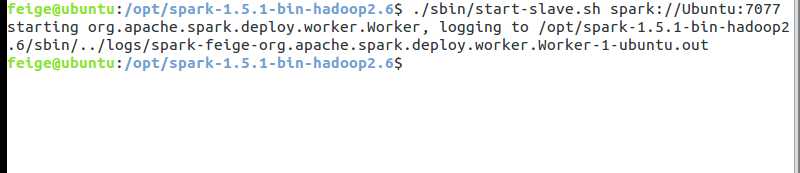
启动slave:
./sbin/start-slave.sh spark://ubuntu:7077
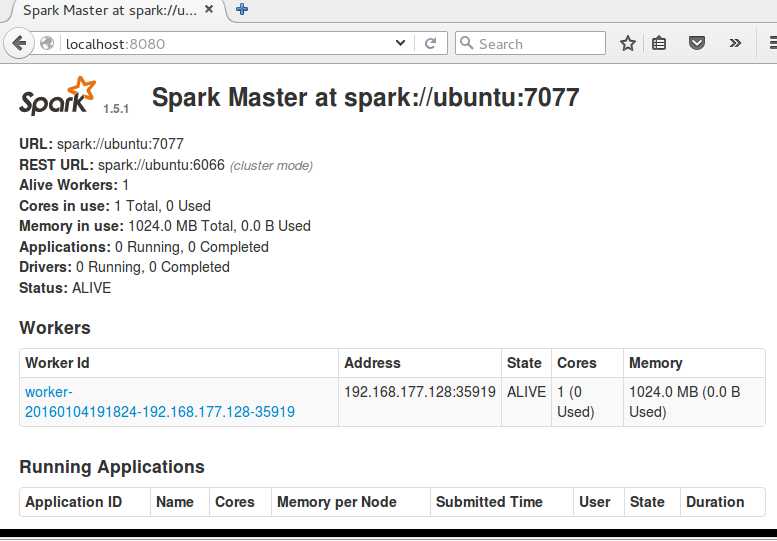
我们可以再次刷新浏览器页面,可以看到worker Id多了一行:
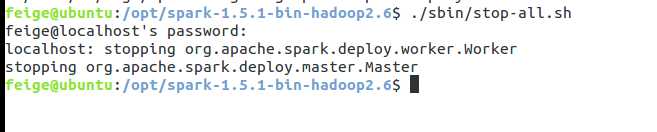
停止服务:
./sbin/stop-all.sh 输入密码即可停止
标签:
原文地址:http://www.cnblogs.com/FG123/p/5101733.html