标签:
1.HashMap的数据结构
a.HashMap是一个链表散列的结合体,即,数组和链表的结合体。
b.HashMap类中定义了Entry类型的数组,Entry [ ] ,Entry有key value hash next属性
如代码
transient Entry[] table; static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; final int hash; …… }
c.结构图如图:
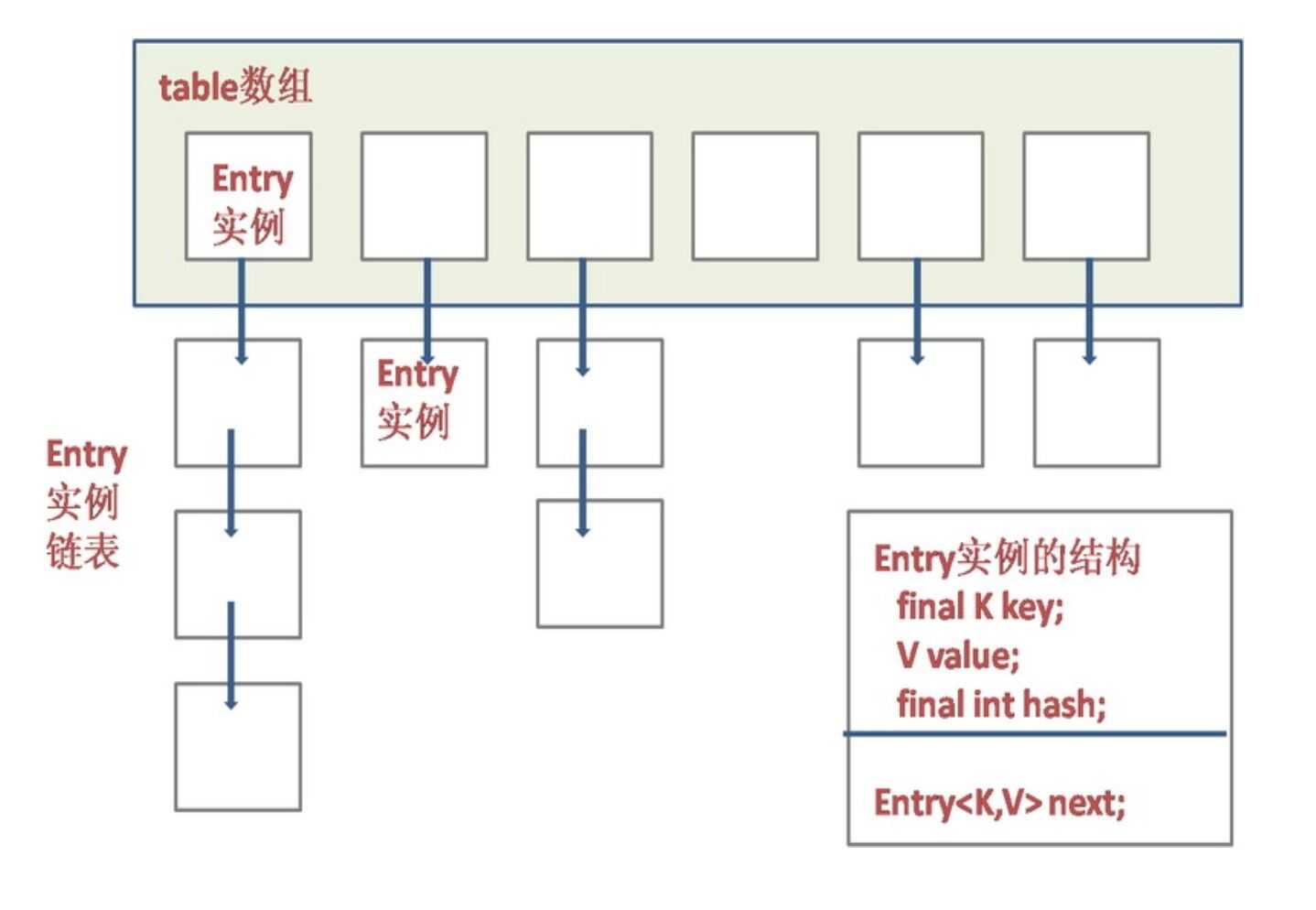
d.HashMap底层就是一个数组结构,数组中的每一项又是一个链表。当新建一个HashMap的时候,
就会初始化一个数组。table数组的元素是Entry类型的。
每个 Entry元素其实就是一个key-value对,并且它持有一个指向下一个 Entry元素的引用
,这就说明table数组的每个Entry元素同时也作为某个Entry链表的首节点,
指向了该链表的下一个Entry元素,这就是所谓的“链表散列”数据结构,即数组和链表的结合体。
2.HashMap的存储实现
当我们往HashMap中put元素的时候,先根据key的重新计算元素的hashCode,
根据hashCode得到这个元素在table数组中的位置(即下标),如果数组该位置上已经存放有其他元素了,那么在这个位置上的元素将以链表的形式存放,新加入的放在链头,
最先加入的放在链尾。如果数组该位置上没有元素,就直接将该元素放到此数组中的该位置上。
代码:
public V put(K key, V value) { // HashMap允许存放null键和null值。 // 当key为null时,调用putForNullKey方法,将value放置在数组第一个位置。 if (key == null) return putForNullKey(value); // 根据key的keyCode重新计算hash值。 int hash = hash(key.hashCode()); // 搜索指定hash值在对应table中的索引。 int i = indexFor(hash, table.length); // 如果 i 索引处的 Entry 不为 null,通过循环不断遍历 e 元素的下一个元素。 for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; // 如果发现 i 索引处的链表的某个Entry的hash和新Entry的hash相等且两者的key相同,则新Entry覆盖旧Entry,返回。 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } // 如果i索引处的Entry为null,表明此处还没有Entry。 modCount++; // 将key、value添加到i索引处。 addEntry(hash, key, value, i); return null;
3.读取元素
从HashMap中get元素时,首先计算key的hashCode,找到数组中对应位置的某一元素,
然后通过key的equals方法在对应位置的链表中找到需要的元素。
public V get(Object key) { if (key == null) return getForNullKey(); int hash = hash(key.hashCode()); for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) return e.value; } return null; }
4.归纳起来简单地说,HashMap 在底层将 key-value 当成一个整体进行处理,
这个整体就是一个 Entry 对象。HashMap 底层采用一个 Entry[] 数组来保存所有的 key-value 对,
当需要存储一个 Entry 对象时,会根据hash算法来决定其在数组中的存储位置,
在根据equals方法决定其在该数组位置上的链表中的存储位置。
标签:
原文地址:http://www.cnblogs.com/fubaizhaizhuren/p/5104811.html