标签:
DRBD(Distributed Replicated Block Device),DRBD 号称是 "网络 RAID",开源软件,由
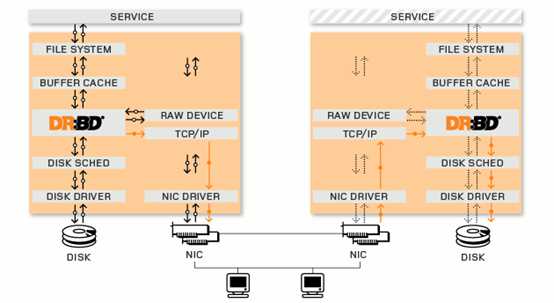
LINBIT 公司开发。DRBD实际上是一种块设备的实现,主要被用于Linux平台下的高可用(HA)方案之中。他有内核模块和相关程序而组成,通过网络通信来同步镜像整个设备,有点类似于一个网络RAID-1的功能。也就是说当你将数据写入本地的DRBD设备上的文件系统时,数据会同时被发送到网络中的另外一台主机之上,并以完全相同的形式记录在文件系统中。本地节点与远程节点的数据可以保证实时的同步,并保证IO的一致性。所以当本地节点的主机出现故障时,远程节点的主机上还会保留有一份完全相同的数据,可以继续使用,以达到高可用的目的.
复制模式:三种
????A:数据一旦写入磁盘并且发送到网络则认为完成写入。特点:快,易丢数据。
????B:收到对端"接收"的信号就认为写完成。半同步。
????C:收到对端"写入"信号才认为完成写操作。特点:数据完整,应用最广。
软件下载:http://oss.linbit.com/drbd 官网http://www.drbd.org
实验环境:rhel6.5 selinux and iptables disabled
主机:server2 172.25.12.2
server3 172.25.12.3
解决软件依赖性:yum install gcc flex rpm-build kernel-devel -y
tar zxf drbd-8.4.3.tar.gz
cd drbd-8.4.0
./configure --enable-spec --with-km
rpmbuild -bb drbd.spec????#编译生成 drbd rpm 包
rpmbuild -bb drbd-km.spec #编译 drbd 内核模块
error: File /root/rpmbuild/SOURCES/drbd-8.4.3.tar.gz: No such file or directory
cp drbd-8.4.0.tar.gz rpmbuild/SOURCES/
?
[root@server2 drbd-8.4.3]# cd ~/rpmbuild/RPMS/x86_64/
[root@server2 x86_64]# ls
drbd-8.4.3-2.el6.x86_64.rpm
drbd-bash-completion-8.4.3-2.el6.x86_64.rpm
drbd-debuginfo-8.4.3-2.el6.x86_64.rpm
drbd-heartbeat-8.4.3-2.el6.x86_64.rpm
drbd-km-2.6.32_431.el6.x86_64-8.4.3-2.el6.x86_64.rpm
drbd-km-debuginfo-8.4.3-2.el6.x86_64.rpm
drbd-pacemaker-8.4.3-2.el6.x86_64.rpm
drbd-udev-8.4.3-2.el6.x86_64.rpm
drbd-utils-8.4.3-2.el6.x86_64.rpm
drbd-xen-8.4.3-2.el6.x86_64.rpm
scp * server2:
yum install *
在两台机上准备好相同大小的磁盘。名字不一定一样
配置两台主机
resource wwwdata {
meta-disk internal;
device /dev/drbd1;
syncer {
verify-alg sha1;
}
on server2.example.com {
disk /dev/drbd_vg/drbd_lv;
address 172.25.12.2:7789;
}
on server3.example.com {
disk /dev/drbd_vg/drbd_lv;
address 172.25.12.3:7789;
}
}
拷贝到另一节点scp wwwdata.res server3:/etc/drbd.d/
DRBD将数据的各种信息块保存在一个专用的区域里,这些metadata包括了
a,DRBD设备的大小
b,产生的标识
c,活动日志
d,快速同步的位图
metadata的存储方式有内部和外部两种方式,使用哪种配置都是在资源配置中定义的
内部metadata:内部metadata存放在同一块硬盘或分区的最后的位置上
优点:metadata和数据是紧密联系在一起的,如果硬盘损坏,metadata同样就没有了,同样在恢复
的时候,metadata也会一起被恢复回来
缺点: 如果底层设备是单一的磁盘,没有做raid,也不是lvm等,那么可能会造成性能影响。metadata和数据在同一块硬盘上,对于写操作的吞吐量会带来负面的影响,因为应用程序的写请求会触发metadata的更新,这样写操作就会造成两次额外的磁头读写移动。
外部metadata:外部的metadata存放在和数据磁盘分开的独立的块设备上
优点:对于一些写操作可以对一些潜在的行为提供一些改进
缺点:metadata和数据不是联系在一起的,所以如果数据盘出现故障,在更换新盘的时候就需要人工干预操作来进行现有node新硬盘的同步了。
配置注意点:meta-disk external;
meta-disk /dev/sdb2 [0];
?
在两台主机上分别执行以下命令:
drbdadm create-md wwwdata
/etc/init.d/drbd start ????????#这里两个同时起,不然单个节点会等代另一结点的反应
开机不自启动。手动起就好。
将 server3设置为 primary 节点,并同步数据:(在 server3 主机执行以下命令)
drbdsetup /dev/drbd1 primary --force
或者drbdadm --overwrite-data-of-peer primary wwwdata
在两台主机上查看同步状态: watch cat /proc/drbd
[root@server3 drbd.d]# cat /proc/drbd
version: 8.4.3 (api:1/proto:86-101)
GIT-hash: 89a294209144b68adb3ee85a73221f964d3ee515 build by root@server2.example.com, 2015-03-13 17:17:17
?
1: cs:SyncSource ro:Primary/Secondary ds:UpToDate/Inconsistent C r-----
ns:679604 nr:0 dw:0 dr:680600 al:0 bm:41 lo:0 pe:1 ua:1 ap:0 ep:1 wo:f oos:365500
????[============>.......] sync‘ed: 65.1% (365500/1044412)K
????finish: 0:00:21 speed: 17,356 (17,408) K/sec
?
数据同步结束后创建文件系统:mkfs.ext4 /dev/drbd1
挂载文件系统:mount /dev/drbd1 /var/www/html
@转换主从关系
drbdadm primary wwwdata
注意:两台主机上的/dev/drbd1 不能同时挂载,只有状态为 primary 时,才能被挂载使用,而此时另一方的状态为 secondary.
?
脑裂:
split brain实际上是指在某种情况下,造成drbd的两个节点断开了连接,都以primary的身份来运行。当drbd某primary节点连接对方节点准 备发送信息的时候如果发现对方也是primary状态,那么会会立刻自行断开连接,并认定当前已经发生split brain了,这时候他会在系统日志中记录以下信息:"Split-Brain detected,dropping connection!"当发生split brain之后,如果查看连接状态,其中至少会有一个是StandAlone状态,另外一个可能也是StandAlone(如果是同时发现split brain状态),也有可能是WFConnection的状态。如果我们在配置文件中配置了自动解决split brain(好像linbit不推荐这样做),drbd会自行解决split brain问题,具体解决策略是根据配置中的设置来进行的
?
脑裂发生时处理:
明确自己是从节点:drbdadm secondary data0
放手资源:drbdadm --discard-my-data connect data0
????连接资源:drbdadm connect data0
?
节点宕机:
?
磁盘处理:
我这里模拟测试下,一切正常的:
把从节点的磁盘,先分离后。
破坏了原来的数据dd if=/dev/zero of=/dev/sdb1 bs=1M count=300
drbdadm create-md data1
drbdadm invalidate data1
drbdadm attach data1
cat /proc/drbd
?
在实验环境中server2.example.com 中有原来的数据,需要迁移到server1.example.com。
在两边正常配置就行,但是drbd裸设备不能格式化。不然数据就丢了。
drbdadm create-md data1
1044 dd if=/dev/zero of=/dev/sdb1 bs=1M count=10
1045 drbdadm create-md data1
1046 /etc/init.d/drbd start
1047 cat /proc/drbd
1051 drbdsetup /dev/drbd2 primary –force
注意点:当两边的磁盘不一样大时,通常迁移到新盘的大一些。Drbd会大的磁盘缩小至对端小磁盘一样大。当数据同步完成之后。就可以恢复回来。
/etc/init.d/drbd stop
e2fsck -f /dev/vg0/lv0
resize2fs /dev/vg0/lv0
2) 收缩resource容量,我觉得用的比较少。这里我并没有测试,因为我一开始就把/dev/drbd2格成ext4了,没法在线缩容量。
容量收缩比扩容操作要危险得多,因为该操作更容易造成数据丢失。在收缩resource的容量之前,必须先收缩drbd设备之上的容量,也就是文件系统的大小。如果上层文件系统不支持收缩,那么resource也没办法收缩容量。
如果在配置drbd的时候将meta信息配置成internal的,那么在进行容量收缩的时候,千万别只计算自身数据所需要的空间大小,还要将drbd的meta信息所需要的空间大小加上。
当文件系统收缩好以后,就可以在线通过以下命令来重设resource的大小: drbdadm –size=***G resize resource_name。在收缩的resource的大小之后,你就可以自行收缩释放底层设备空间(如果支持的话)
如果打算停机状态下收缩容量,可以通过以下步骤进行:没试过,备用
(1)在线收缩文件系统
(2)停用drbd的resource:drbdadm down resourcec_name
(3)导出drbd的metadata信息(在所有节点都需要进行):drbdadm dump-md resource_name > /path_you_want_to_save/file_name
(4)在所有节点收缩底层设备
(5)更改上面dump出来的meta信息的la-size-sect项到收缩后的大小(是换算成sector的数量后的数值)
(6)如果使用的是internal来配置meta-data信息,则需要重新创建meta-data:drbdadm create-md resource_name
(7)将之前导出并修改好的meta信息重新导入drbd(摘录自linbit官方网站的一段导入代码): drbdmeta_cmd=$(drbdadm -d dump-md test-disk)
${drbdmeta_cmd/dump-md/restore-md} /path_you_want_to_save/file_name
(8)启动resource:drbdadm up resource_name
?
Heartbeat和drbd结合:
结合之前配置的heartbeat就行:
但是drbd必须要建立起来,才能HA切换
server2.example.com IPaddr::192.168.88.200/24/eth0 drbddisk::data0 Filesystem::/dev/drbd1::/data::ext4
一行命令搞定,注意顺序不能错:
data0????资源名称。
/dev/drbd1 裸设备
/data 挂载点
ext4 文件系统类型
?
?
?
?
?
????????????????????????????????????????????????????????????????
????????????????????????????????????????????????????浅淡
????????????????????????????????????????????????????1138122262@qq.com
标签:
原文地址:http://www.cnblogs.com/wxl-dede/p/5114696.html