标签:
一个项目只需要tesseract traineddata 中的数字部分。
实现过程简单说就是解包,去掉多余,再打包。利用了tesseract的dawg2wordlist / wordlist2dawg 和 combine_tessdata 这三个命令。
首先解包:
这里需要用到Tesseract安装包,而不是源码。在Tesseact-OCR文件夹下运行
combine_tessdata -u tessdata/eng.traineddata d:/temp/eng.
得到一堆零件:
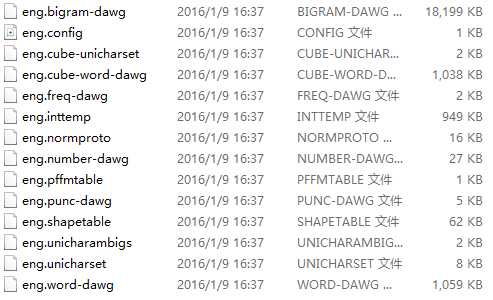
看到最大的那个eng.bigram-dawg文件。用下面命令解析成看得清的文本文档:
dawg2wordlist d:/tempeng.unicharset d:/temp/eng.bigram-dawg d:/temp/bigram-wordlist
看到文件里是这样的东西:
I F
I Found
I Foundations
I For
I Forgot
I Forget
I Fig
I Figure
I First
I Fine
I Find
I FIND
I FINALLY
I From
I Fucked
I Family
I Fall
I FOUND
I Feel
I Feed
I Fell
原来是一些可能的文字组合,怪不得这么大。
检查了一下里面根本没有数字。把这个文件删除,我们自己来做一个。
新建一个mywordlist文本文件,里面只写一行(全空无法生成):
1234567890 1234567890
用下面命令生成dawg文件
wordlist2dawg d:/temp/mywordlist d:/temp/eng.bigram-dawg d:/temp/eng.unicharset
再用下面命令生成eng.traineddata文件,原文件会被覆盖。
combine_tessdata d:/temp/eng.
看一下,只有3M多一点了。
放手机上试一下,能用。
标签:
原文地址:http://www.cnblogs.com/dfun/p/5117036.html