标签:
 。
。
一、Hadoop Yarn组件介绍:
我们都知道yarn重构根本的思想,是将原有的JobTracker的两个主要功能资源管理器 和 任务调度监控 分离成单独的组件。新的架构使用全局管理所有应用程序的计算资源分配。 主要包含三个组件ResourceManager 、NodeManager和ApplicationMaster以及一个核心概念Container.
1.ResourceManager(RM)
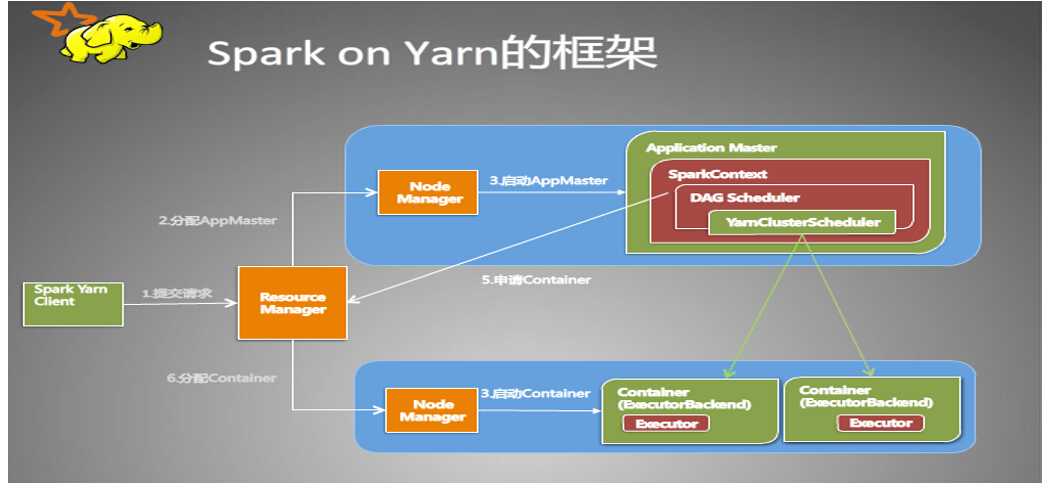
就是所谓的资源管理器,每个集群一个,实现全局的资源管理和任务调度。它可以处理客户端提交计算作业的请求,启动并监听ApplicationMaster,监控NodeManager,进行资源分配与调度。每一个应用程序需要不同类型的资源,因此就需要不同的容器。这里的资源包括内存、CPU、磁盘、网络等。(比如使用spark-submit 执行程序jar包,就需要向ResourceManager注册,申请相应的容器,资源),其中该ResourceManager提供一个调度策略的插件,负责将集群资源分配给多个队列和应用程序.(可以基于现有的能力调度和公平调度模型)
2.NodeManager(NM)
节点管理器,每个节点一个,实现节点的监控与报告。处理来自ResourceManager的命令,也处理来自ApplicationMaster的命令,同时监控资源可用性,报告错误,管理资源的生命周期。NodeManager是每一台机器框架的代理,是执行应用程序的容器,监控应用程序的资源使用情况(CPU、内存、硬盘、网络)并向调度器汇报。
3.ApplicationMaster(AM)
应用控制器,每个作业或应用一个,实现应用的调度和资源协调。具体来说呢,它进行数据的切分,为应用申请资源并分配给任务,完成任务监控与容错。实际上,每个应用的ApplicationMaster是一个详细的框架库。它结合从ResourceManager获得的资源和NodeManager协同工作来运行和监听任务。ApplicationMaster负责向ResourceManager索要适当的资源容器(containter)来运行任务,跟踪应用程序的状态和监控她们的进程,处理任务的失败原因。
4.Container
容器,封装了及其资源,包括内存、CPU、磁盘、网络等。每个任务会被分配一个容器,该任务只能在该容器中执行,并使用该容器封装的资源。当应用程序发出资源请求时,ResourceManager并不会立刻返回满足要求的资源,需要ApplicationMaster与ResourceManager不断地通信,检测分配到的资源足够,才会进行分配。一旦分配完毕,ApplicationMaster便可从ResourceManager处获取以Container表示的资源。(Container可以看做一个可序列化的Java对象,包含字段信息)一般来说,每个Container可用于执行一个任务。ApplicationMaster在收到一个或多个Container后,再将该Container进一步分配给内部的某个任务,确定该任务后,ApplicationMaster将该任务运行环境(包含运行命令、环境变量、依赖的外部文件等)连同Container中的资源信息封装到ContainerLaunchContext对象中,进而与对应的NodeManager通信,启动该任务。
二、Spark on Yarn
1.当提交一个spark-submit任务时,spark将在startUserClass函数专门启动了一个线程(名称为Driver的线程)来启动用户提交的Application,也就是启动了Driver。在Driver中将会初始化SparkContext。
2.等待SparkContext初始化完成,最多等待spark.yarn.applicationMaster.waitTries次数(默认为10),如果等待了的次数超过了配置的,程序将会退出;否则用SparkContext初始化yarnAllocator.
3.当SparkContext、Driver初始化完成的时候,通过ApplicationMasterClient向ResourceManager注册ApplicationMaster.
4.分配并启动Executeors。在启动Executeors之前,先要通过yarnAllocator获取到numExecutors个Container,然后在Container中启动Executeors。(启动Executeors是通过ExecutorRunnable实现的,而ExecutorRunnable内部是启动CoarseGrainedExecutorBackend的)
5.最后,Task将在CoarseGrainedExecutorBackend里面运行,然后运行状况会通过Akka通知CoarseGrainedScheduler,直到作业运行完成。
Spark on Yarn只需要部署一份spark,当应用程序启动时,spark会将相关的jar包上传注册给ResoureManager,任务的执行由ResourceManager来调度,并执行spark的代码。
标签:
原文地址:http://www.cnblogs.com/yangsy0915/p/5118100.html