标签:
Hadoop7天课程

hadoop前景
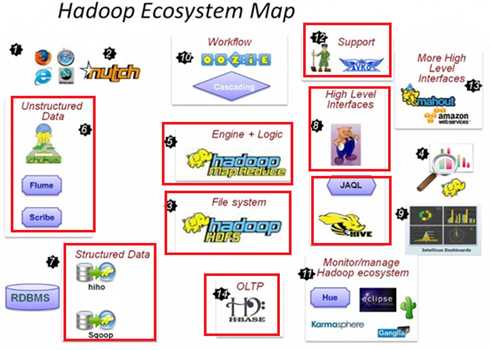
apache的开源项目
海量数据的存储(HDFS)
---Hadoop分布式文件系统,解决机器怎么存储
海量数据的分析(MapReduce)
----分布的计算模型,解决机器怎么干活,区分主从
资源管理调度(YARN)
---另一个资源调用系统,hadoop2.0之后出现,以前只能MapReduce
(不局限于mapreduce:storm实时流、mpi等)
Hadoop的商业版本cdh,已经提供技术支持
lucene的作者
gfs谷歌的分布式文件系统---hdfs数据存储
mapreduce谷歌分布式计算模型----mapreduce数据分析
bigtable大表数据库---hbase列式数据库(介于关系型和nosql之间)怎么存储
hadoop擅长日志分析,主要处理离线数据(分析以前产生的数据),facebook就用Hive来进行日志分析,2009年时facebook就有非编程人员的30%的人使用HiveQL进行数据分析;淘宝搜索中的自定义筛选也使用的Hive;利用Pig还可以做高级的数据处理,包括Twitter、LinkedIn 上用于发现您可能认识的人,可以实现类似Amazon.com的协同过滤的推荐效果。淘宝的商品推荐也是!在Yahoo!的40%的Hadoop作业是用pig运行的,包括垃圾邮件的识别和过滤,还有用户特征建模。(2012年8月25新更新,天猫的推荐系统是Hive,少量尝试mahout!)
storm做实时推荐
Hadoop被公认是一套行业大数据标准开源软件,在分布式环境下提供了海量数据的处理能力。几乎所有主流厂商都围绕Hadoop开发工具、开源软件、商业化工具和技术服务。今年大型IT公司,如EMC、Microsoft、Intel、Teradata、Cisco都明显增加了Hadoop方面的投入
扩展知识:参照淘宝双十一解决方案
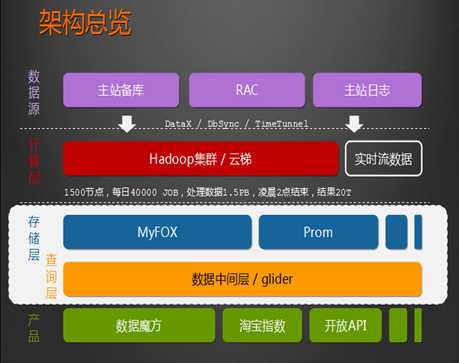
淘宝数据魔方的真实面目
官方版本(2.4.1)
????使用下载最多的版本,稳定,有商业支持,在Apache的基础上打上了一些patch。推荐使用。
Hortonworks公司发行版本。
Hdfs分布式文件系统
Mapreduce并行计算框架
Yarn资源管理调度系统(运行符合规则的程序)

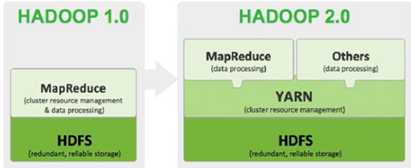
Yarn的出现使得hadoop可以支持多个计算框架(不仅是mapreduce)

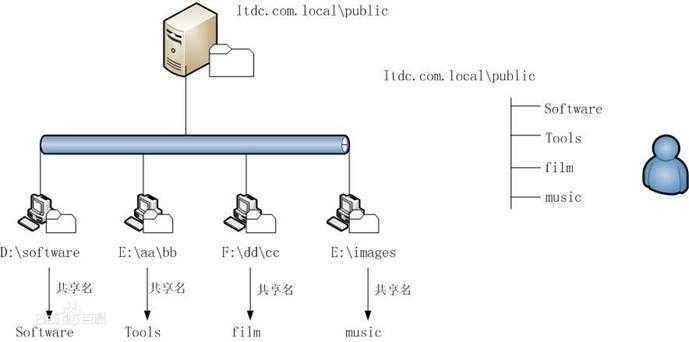
通过水平扩展机器数量来提高存储数据的能力
主节点,只有一个: namenode,负责管理
从节点,有很多个: datanode 负责存储
接收用户操作请求
维护文件系统的目录结构
管理文件与block之间关系,block与datanode之间关系
存储文件
文件被分成block存储在磁盘上
为保证数据安全,文件会有多个副本
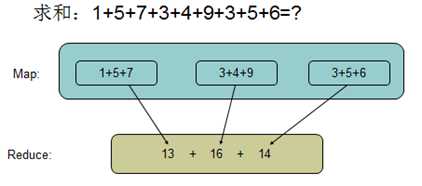
map:大任务分解为若干个小任务
reduce:小任务再汇总整合成大任务的结果
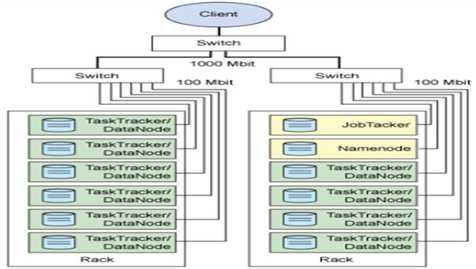
Rack:机架、switch:交换机、datanode:hdfs的小弟(从节点)

本地模式:eclipse调试用,只启一个mapper一个reduce
伪分布模式:一台机器模拟多台机器
集群模式:真实的生产环境
????1.0点击VMware快捷方式,右键打开文件所在位置 -> 双击vmnetcfg.exe -> VMnet1 host-only ->修改subnet ip 设置网段:192.168.1.0 子网掩码:255.255.255.0 -> apply -> ok
????????回到windows --> 打开网络和共享中心 -> 更改适配器设置 -> 右键VMnet1 -> 属性 -> 双击IPv4 -> 设置windows的IP:192.168.1.110 子网掩码:255.255.255.0 -> 点击确定
????????在虚拟软件上 --My Computer -> 选中虚拟机 -> 右键 -> settings -> network adapter -> host only -> ok????
????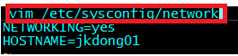
????????vim /etc/sysconfig/network
????????NETWORKING=yes
????????HOSTNAME=itcast01 ###
????????两种方式:
????????第一种:通过Linux图形界面进行修改(强烈推荐)
????????????进入Linux图形界面 -> 右键点击右上方的两个小电脑 -> 点击Edit connections -> 选中当前网络System eth0 -> 点击edit按钮 -> 选择IPv4 -> method选择为manual -> 点击add按钮 -> 添加IP:192.168.1.119 子网掩码:255.255.255.0 网关:192.168.1.1 -> apply
????????第二种:修改配置文件方式(屌丝程序猿专用)
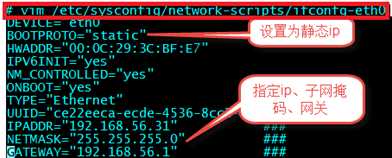
????????????vim /etc/sysconfig/network-scripts/ifcfg-eth0
????????????DEVICE="eth0"
????????????BOOTPROTO="static"
????????????HWADDR="00:0C:29:2C:BF:E3"
????????????IPV6INIT="yes"
????????????NM_CONTROLLED="yes"
????????????ONBOOT="yes"
????????????TYPE="Ethernet"
????????????UUID="ce22eeca-ecde-4536-8cc3-ef0fc36d6a8c"
????????????IPADDR="192.168.56.32 "
????????????NETMASK="255.255.255.0"
????????????GATEWAY="192.168.56.1"
????----x相当于本地的dns
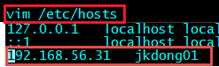
????????vim /etc/hosts
????????192.168.56.31????jkdong01
????????#查看防火墙状态

????????service iptables status
????????#关闭防火墙
????????service iptables stop
????????#查看防火墙开机启动状态

????????chkconfig iptables --list
????????#关闭防火墙开机启动
????????chkconfig iptables off
????????reboot
????????#创建文件夹
????????mkdir /usr/java
????????#解压
????????tar -zxvf jdk-7u55-linux-i586.tar.gz -C /usr/java/
????????vim /etc/profile

????????#在文件最后添加
????????export JAVA_HOME=/usr/java/jdk1.7.0_55
????????export PATH=$PATH:$JAVA_HOME/bin
????????#刷新配置
????????source /etc/profile
????????#解压到/itcast/目录下
????????tar -zxvf hadoop-2.2.0.tar.gz -C /itcast/
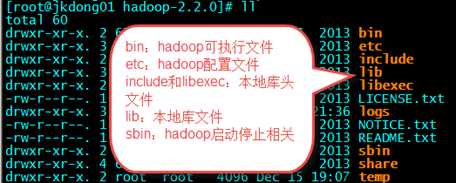
Cd etc/hadoop
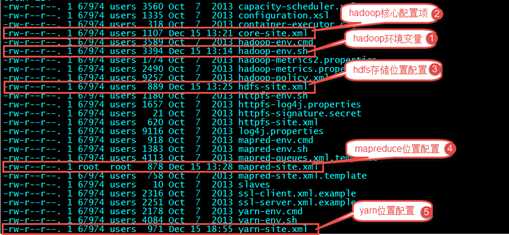
????????第一个:hadoop-env.sh—指定环境变量
????????#在27行修改

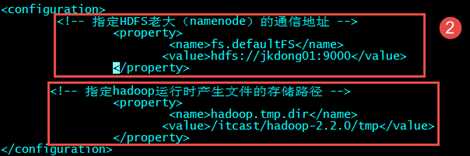
????????第二个:core-site.xml—hadoop核心配置
????????
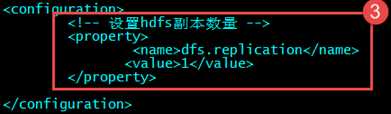
????????第三个:hdfs-site.xml—hdfs节点配置
????????
????????第四个:mapred-site.xml.template 需要重命名: mv mapred-site.xml.template mapred-site.xml
????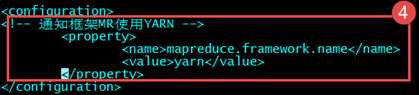 ????????
????????
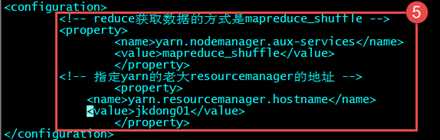
第五个:yarn-site.xml
????
????????命令:vim /etc/profile
???????? ????????再执行:source /etc/profile刷新配置
????????再执行:source /etc/profile刷新配置
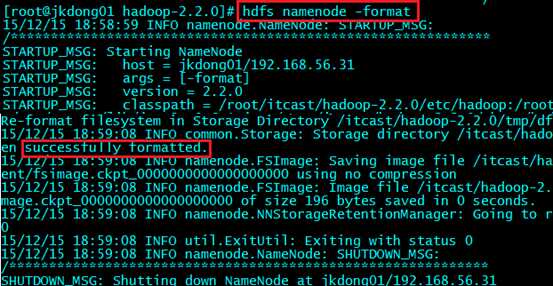
????????hadoop namenode -format(过时了但是依然可用)
hdfs namenode -format(现用的格式化命令)
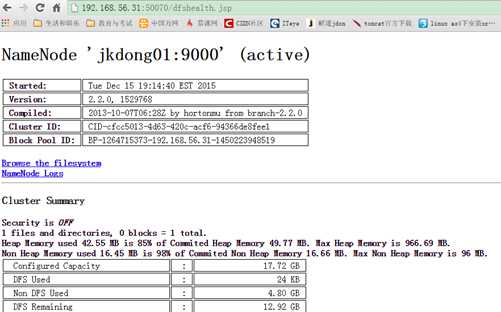
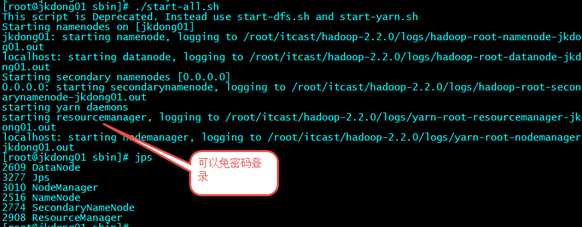
????????先启动HDFS
????????sbin/start-dfs.sh
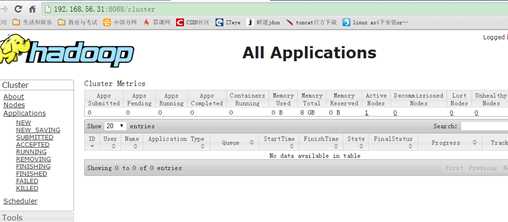
????????再启动YARN
????????sbin/start-yarn.sh
????????使用jps命令验证

Ssh即安全的shell命令
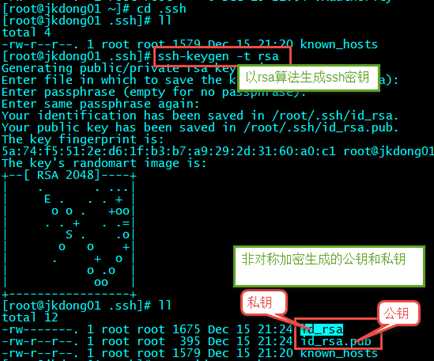
????生成ssh免登陆密钥
????cd ~,进入到我的home目录
????cd .ssh/
????ssh-keygen -t rsa (四个回车)
????执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
????将公钥拷贝到要免登陆的机器上
/root/.ssh目录下:cp id_rsa.pub authorized_keys
????或
????ssh-copy-id 192.168.56.32
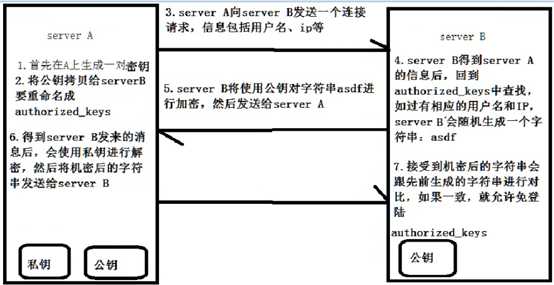
这样server A就可以对server B进行免密码登录
课程安排:
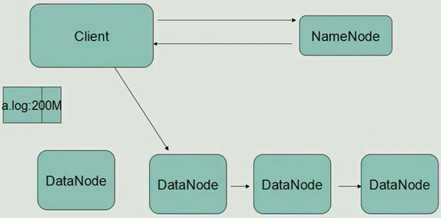
Datanode会横向流水线方式复制文件产生副本
上传的文件还会分block块(hadoop块的大小128M)
用一个系统来管理多台机器上的文件(冗余存储)
允许通过网络分享文件和存储空间
通透性:访问远程文件就像访问本地资源一样
容错:持续运行而不会使数据损失
Hdfs就是一种分布式文件系统,不支持并发写(按block块的顺序写),小文件不适合(hadoop1.x)
常见分布式文件系统:gfs(谷歌文件系统),hdfs、Lustre。。。
?
?
?
?
?
?
标签:
原文地址:http://www.cnblogs.com/jkdong1024/p/5127381.html