标签:
作者:戴嘉华
转载请注明出处并保留原文链接( #13 )和作者信息。
本文会在教你怎么用 300~400 行代码实现一个基本的 Virtual DOM 算法,并且尝试尽量把 Virtual DOM 的算法思路阐述清楚。希望在阅读本文后,能让你深入理解 Virtual DOM 算法,给你现有前端的编程提供一些新的思考。
本文所实现的完整代码存放在 Github。
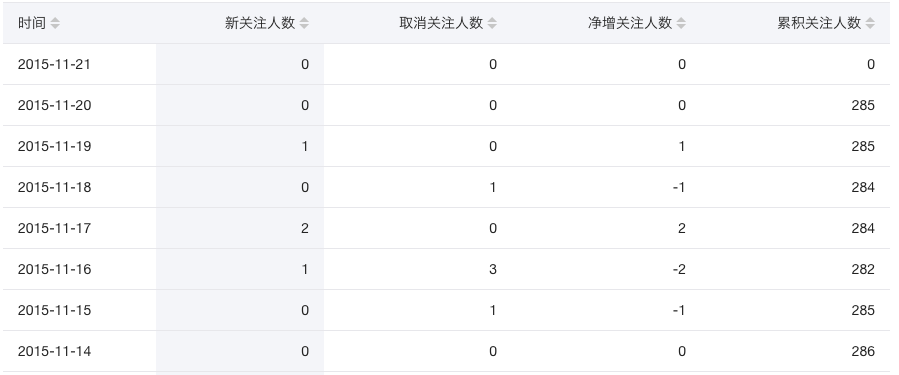
假如现在你需要写一个像下面一样的表格的应用程序,这个表格可以根据不同的字段进行升序或者降序的展示。
这个应用程序看起来很简单,你可以想出好几种不同的方式来写。最容易想到的可能是,在你的 JavaScript 代码里面存储这样的数据:
var sortKey = "new" // 排序的字段,新增(new)、取消(cancel)、净关注(gain)、累积(cumulate)人数
var sortType = 1 // 升序还是逆序
var data = [{...}, {...}, {..}, ..] // 表格数据
用三个字段分别存储当前排序的字段、排序方向、还有表格数据;然后给表格头部加点击事件:当用户点击特定的字段的时候,根据上面几个字段存储的内容来对内容进行排序,然后用 JS 或者 jQuery 操作 DOM,更新页面的排序状态(表头的那几个箭头表示当前排序状态,也需要更新)和表格内容。
这样做会导致的后果就是,随着应用程序越来越复杂,需要在JS里面维护的字段也越来越多,需要监听事件和在事件回调用更新页面的DOM操作也越来越多,应用程序会变得非常难维护。后来人们使用了 MVC、MVP 的架构模式,希望能从代码组织方式来降低维护这种复杂应用程序的难度。但是 MVC 架构没办法减少你所维护的状态,也没有降低状态更新你需要对页面的更新操作(前端来说就是DOM操作),你需要操作的DOM还是需要操作,只是换了个地方。
既然状态改变了要操作相应的DOM元素,为什么不做一个东西可以让视图和状态进行绑定,状态变更了视图自动变更,就不用手动更新页面了。这就是后来人们想出了 MVVM 模式,只要在模版中声明视图组件是和什么状态进行绑定的,双向绑定引擎就会在状态更新的时候自动更新视图(关于MV*模式的内容,可以看这篇介绍)。
MVVM 可以很好的降低我们维护状态 -> 视图的复杂程度(大大减少代码中的视图更新逻辑)。但是这不是唯一的办法,还有一个非常直观的方法,可以大大降低视图更新的操作:一旦状态发生了变化,就用模版引擎重新渲染整个视图,然后用新的视图更换掉旧的视图。就像上面的表格,当用户点击的时候,还是在JS里面更新状态,但是页面更新就不用手动操作 DOM 了,直接把整个表格用模版引擎重新渲染一遍,然后设置一下innerHTML就完事了。
听到这样的做法,经验丰富的你一定第一时间意识这样的做法会导致很多的问题。最大的问题就是这样做会很慢,因为即使一个小小的状态变更都要重新构造整棵 DOM,性价比太低;而且这样做的话,input和textarea的会失去原有的焦点。最后的结论会是:对于局部的小视图的更新,没有问题(Backbone就是这么干的);但是对于大型视图,如全局应用状态变更的时候,需要更新页面较多局部视图的时候,这样的做法不可取。
但是这里要明白和记住这种做法,因为后面你会发现,其实 Virtual DOM 就是这么做的,只是加了一些特别的步骤来避免了整棵 DOM 树变更。
另外一点需要注意的就是,上面提供的几种方法,其实都在解决同一个问题:维护状态,更新视图。在一般的应用当中,如果能够很好方案来应对这个问题,那么就几乎降低了大部分复杂性。
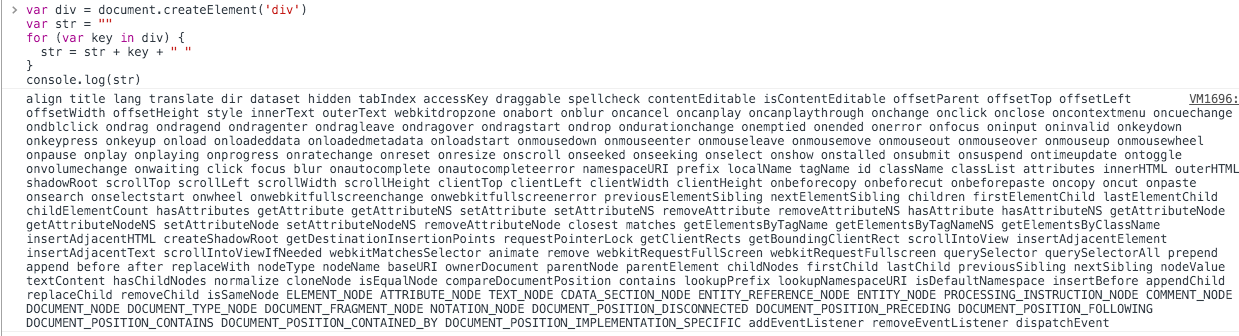
DOM是很慢的。如果我们把一个简单的div元素的属性都打印出来,你会看到:
而这仅仅是第一层。真正的 DOM 元素非常庞大,这是因为标准就是这么设计的。而且操作它们的时候你要小心翼翼,轻微的触碰可能就会导致页面重排,这可是杀死性能的罪魁祸首。
相对于 DOM 对象,原生的 JavaScript 对象处理起来更快,而且更简单。DOM 树上的结构、属性信息我们都可以很容易地用 JavaScript 对象表示出来:
var element = {
tagName: ‘ul‘, // 节点标签名
props: { // DOM的属性,用一个对象存储键值对
id: ‘list‘
},
children: [ // 该节点的子节点
{tagName: ‘li‘, props: {class: ‘item‘}, children: ["Item 1"]},
{tagName: ‘li‘, props: {class: ‘item‘}, children: ["Item 2"]},
{tagName: ‘li‘, props: {class: ‘item‘}, children: ["Item 3"]},
]
}
上面对应的HTML写法是:
<ul id=‘list‘>
<li class=‘item‘>Item 1</li>
<li class=‘item‘>Item 2</li>
<li class=‘item‘>Item 3</li>
</ul>
既然原来 DOM 树的信息都可以用 JavaScript 对象来表示,反过来,你就可以根据这个用 JavaScript 对象表示的树结构来构建一棵真正的DOM树。
之前的章节所说的,状态变更->重新渲染整个视图的方式可以稍微修改一下:用 JavaScript 对象表示 DOM 信息和结构,当状态变更的时候,重新渲染这个 JavaScript 的对象结构。当然这样做其实没什么卵用,因为真正的页面其实没有改变。
但是可以用新渲染的对象树去和旧的树进行对比,记录这两棵树差异。记录下来的不同就是我们需要对页面真正的 DOM 操作,然后把它们应用在真正的 DOM 树上,页面就变更了。这样就可以做到:视图的结构确实是整个全新渲染了,但是最后操作DOM的时候确实只变更有不同的地方。
这就是所谓的 Virtual DOM 算法。包括几个步骤:
Virtual DOM 本质上就是在 JS 和 DOM 之间做了一个缓存。可以类比 CPU 和硬盘,既然硬盘这么慢,我们就在它们之间加个缓存:既然 DOM 这么慢,我们就在它们 JS 和 DOM 之间加个缓存。CPU(JS)只操作内存(Virtual DOM),最后的时候再把变更写入硬盘(DOM)。
用 JavaScript 来表示一个 DOM 节点是很简单的事情,你只需要记录它的节点类型、属性,还有子节点:
element.js
function Element (tagName, props, children) {
this.tagName = tagName
this.props = props
this.children = children
}
module.exports = function (tagName, props, children) {
return new Element(tagName, props, children)
}
例如上面的 DOM 结构就可以简单的表示:
var el = require(‘./element‘)
var ul = el(‘ul‘, {id: ‘list‘}, [
el(‘li‘, {class: ‘item‘}, [‘Item 1‘]),
el(‘li‘, {class: ‘item‘}, [‘Item 2‘]),
el(‘li‘, {class: ‘item‘}, [‘Item 3‘])
])
现在ul只是一个 JavaScript 对象表示的 DOM 结构,页面上并没有这个结构。我们可以根据这个ul构建真正的<ul>:
Element.prototype.render = function () {
var el = document.createElement(this.tagName) // 根据tagName构建
var props = this.props
for (var propName in props) { // 设置节点的DOM属性
var propValue = props[propName]
el.setAttribute(propName, propValue)
}
var children = this.children || []
children.forEach(function (child) {
var childEl = (child instanceof Element)
? child.render() // 如果子节点也是虚拟DOM,递归构建DOM节点
: document.createTextNode(child) // 如果字符串,只构建文本节点
el.appendChild(childEl)
})
return el
}
render方法会根据tagName构建一个真正的DOM节点,然后设置这个节点的属性,最后递归地把自己的子节点也构建起来。所以只需要:
var ulRoot = ul.render()
document.body.appendChild(ulRoot)
上面的ulRoot是真正的DOM节点,把它塞入文档中,这样body里面就有了真正的<ul>的DOM结构:
<ul id=‘list‘>
<li class=‘item‘>Item 1</li>
<li class=‘item‘>Item 2</li>
<li class=‘item‘>Item 3</li>
</ul>
完整代码可见 element.js。
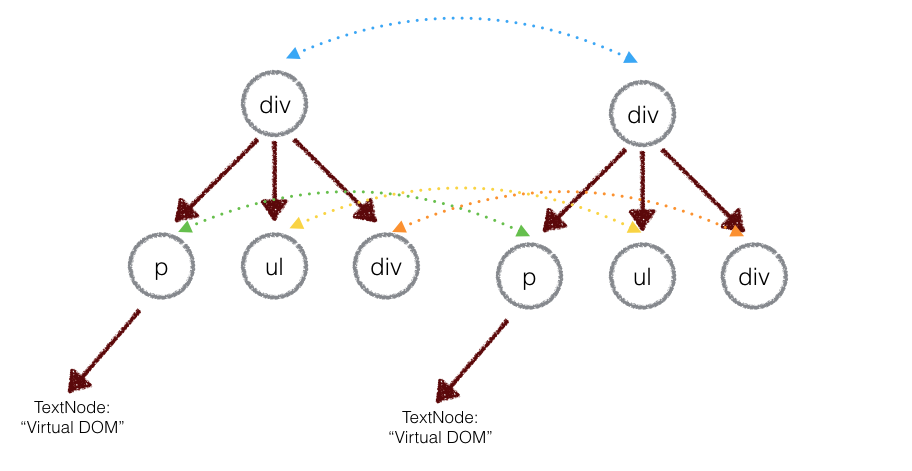
正如你所预料的,比较两棵DOM树的差异是 Virtual DOM 算法最核心的部分,这也是所谓的 Virtual DOM 的 diff 算法。两个树的完全的 diff 算法是一个时间复杂度为 O(n^3) 的问题。但是在前端当中,你很少会跨越层级地移动DOM元素。所以 Virtual DOM 只会对同一个层级的元素进行对比:
上面的div只会和同一层级的div对比,第二层级的只会跟第二层级对比。这样算法复杂度就可以达到 O(n)。
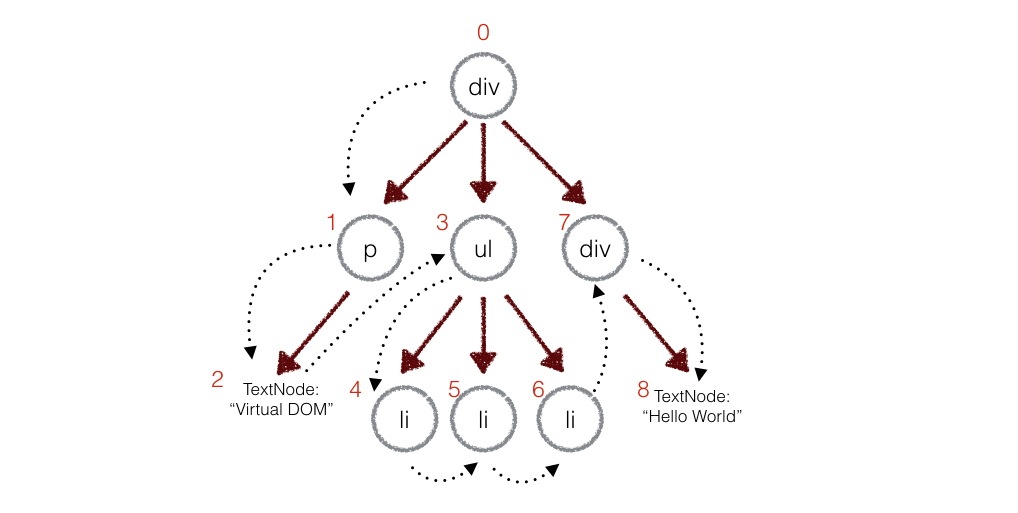
在实际的代码中,会对新旧两棵树进行一个深度优先的遍历,这样每个节点都会有一个唯一的标记:
在深度优先遍历的时候,每遍历到一个节点就把该节点和新的的树进行对比。如果有差异的话就记录到一个对象里面。
// diff 函数,对比两棵树
function diff (oldTree, newTree) {
var index = 0 // 当前节点的标志
var patches = {} // 用来记录每个节点差异的对象
dfsWalk(oldTree, newTree, index, patches)
return patches
}
// 对两棵树进行深度优先遍历
function dfsWalk (oldNode, newNode, index, patches) {
// 对比oldNode和newNode的不同,记录下来
patches[index] = [...]
diffChildren(oldNode.children, newNode.children, index, patches)
}
// 遍历子节点
function diffChildren (oldChildren, newChildren, index, patches) {
var leftNode = null
var currentNodeIndex = index
oldChildren.forEach(function (child, i) {
var newChild = newChildren[i]
currentNodeIndex = (leftNode && leftNode.count) // 计算节点的标识
? currentNodeIndex + leftNode.count + 1
: currentNodeIndex + 1
dfsWalk(child, newChild, currentNodeIndex, patches) // 深度遍历子节点
leftNode = child
})
}
例如,上面的div和新的div有差异,当前的标记是0,那么:
patches[0] = [{difference}, {difference}, ...] // 用数组存储新旧节点的不同
同理p是patches[1],ul是patches[3],类推。
上面说的节点的差异指的是什么呢?对 DOM 操作可能会:
div换成了sectiondiv的子节点,把p和ul顺序互换Virtual DOM 2。所以我们定义了几种差异类型:
var REPLACE = 0
var REORDER = 1
var PROPS = 2
var TEXT = 3
对于节点替换,很简单。判断新旧节点的tagName和是不是一样的,如果不一样的说明需要替换掉。如div换成section,就记录下:
patches[0] = [{
type: REPALCE,
node: newNode // el(‘section‘, props, children)
}]
如果给div新增了属性id为container,就记录下:
patches[0] = [{
type: REPALCE,
node: newNode // el(‘section‘, props, children)
}, {
type: PROPS,
props: {
id: "container"
}
}]
如果是文本节点,如上面的文本节点2,就记录下:
patches[2] = [{
type: TEXT,
content: "Virtual DOM2"
}]
那如果把我div的子节点重新排序呢?例如p, ul, div的顺序换成了div, p, ul。这个该怎么对比?如果按照同层级进行顺序对比的话,它们都会被替换掉。如p和div的tagName不同,p会被div所替代。最终,三个节点都会被替换,这样DOM开销就非常大。而实际上是不需要替换节点,而只需要经过节点移动就可以达到,我们只需知道怎么进行移动。
这牵涉到两个列表的对比算法,需要另外起一个小节来讨论。
假设现在可以英文字母唯一地标识每一个子节点:
旧的节点顺序:
a b c d e f g h i
现在对节点进行了删除、插入、移动的操作。新增j节点,删除e节点,移动h节点:
新的节点顺序:
a b c h d f g i j
现在知道了新旧的顺序,求最小的插入、删除操作(移动可以看成是删除和插入操作的结合)。这个问题抽象出来其实是字符串的最小编辑距离问题(Edition Distance),最常见的解决算法是 Levenshtein Distance,通过动态规划求解,时间复杂度为 O(M * N)。但是我们并不需要真的达到最小的操作,我们只需要优化一些比较常见的移动情况,牺牲一定DOM操作,让算法时间复杂度达到线性的(O(max(M, N))。具体算法细节比较多,这里不累述,有兴趣可以参考代码。
我们能够获取到某个父节点的子节点的操作,就可以记录下来:
patches[0] = [{
type: REORDER,
moves: [{remove or insert}, {remove or insert}, ...]
}]
但是要注意的是,因为tagName是可重复的,不能用这个来进行对比。所以需要给子节点加上唯一标识key,列表对比的时候,使用key进行对比,这样才能复用老的 DOM 树上的节点。
这样,我们就可以通过深度优先遍历两棵树,每层的节点进行对比,记录下每个节点的差异了。完整 diff 算法代码可见 diff.js。
因为步骤一所构建的 JavaScript 对象树和render出来真正的DOM树的信息、结构是一样的。所以我们可以对那棵DOM树也进行深度优先的遍历,遍历的时候从步骤二生成的patches对象中找出当前遍历的节点差异,然后进行 DOM 操作。
function patch (node, patches) {
var walker = {index: 0}
dfsWalk(node, walker, patches)
}
function dfsWalk (node, walker, patches) {
var currentPatches = patches[walker.index] // 从patches拿出当前节点的差异
var len = node.childNodes
? node.childNodes.length
: 0
for (var i = 0; i < len; i++) { // 深度遍历子节点
var child = node.childNodes[i]
walker.index++
dfsWalk(child, walker, patches)
}
if (currentPatches) {
applyPatches(node, currentPatches) // 对当前节点进行DOM操作
}
}
applyPatches,根据不同类型的差异对当前节点进行 DOM 操作:
function applyPatches (node, currentPatches) {
currentPatches.forEach(function (currentPatch) {
switch (currentPatch.type) {
case REPLACE:
node.parentNode.replaceChild(currentPatch.node.render(), node)
break
case REORDER:
reorderChildren(node, currentPatch.moves)
break
case PROPS:
setProps(node, currentPatch.props)
break
case TEXT:
node.textContent = currentPatch.content
break
default:
throw new Error(‘Unknown patch type ‘ + currentPatch.type)
}
})
}
完整代码可见 patch.js。
Virtual DOM 算法主要是实现上面步骤的三个函数:element,diff,patch。然后就可以实际的进行使用:
// 1. 构建虚拟DOM
var tree = el(‘div‘, {‘id‘: ‘container‘}, [
el(‘h1‘, {style: ‘color: blue‘}, [‘simple virtal dom‘]),
el(‘p‘, [‘Hello, virtual-dom‘]),
el(‘ul‘, [el(‘li‘)])
])
// 2. 通过虚拟DOM构建真正的DOM
var root = tree.render()
document.body.appendChild(root)
// 3. 生成新的虚拟DOM
var newTree = el(‘div‘, {‘id‘: ‘container‘}, [
el(‘h1‘, {style: ‘color: red‘}, [‘simple virtal dom‘]),
el(‘p‘, [‘Hello, virtual-dom‘]),
el(‘ul‘, [el(‘li‘), el(‘li‘)])
])
// 4. 比较两棵虚拟DOM树的不同
var patches = diff(tree, newTree)
// 5. 在真正的DOM元素上应用变更
patch(root, patches)
当然这是非常粗糙的实践,实际中还需要处理事件监听等;生成虚拟 DOM 的时候也可以加入 JSX 语法。这些事情都做了的话,就可以构造一个简单的ReactJS了。
本文所实现的完整代码存放在 Github,仅供学习。
标签:
原文地址:http://www.cnblogs.com/hubing/p/5128808.html