标签:
2.1 介绍
概率机器人的核心是从传感器数据中估计状态的这么一个概念。状态估计解决从传感器数据中估计的变量问题,这些估计变量并非直接可观测到,而是被推断出来的。在大多数机器人应用当中,决定做什么相对来说容易,如果仅仅知道某些变量的话。例如,移动一个移动机器人是相对容易的如果机器人以及所有附近障碍的精确位置是已知的。不幸的是,这些变量不能直接测得。相反,一个机器人不得不依靠它的传感器来获得这些信息。传感器只是携带了部分这些变量的信息,他们的测量被噪声腐蚀了。状态估计试图从数据当中恢复状态变量。概率状态估计算法计算对可能世界状态的信任度分布。概率状态估计的一个例子在本书介绍中已经遇到:移动机器人定位。
本章的目标是介绍基本的词表以及数学工具对于从传感器数据中来估计状态。
2.2介绍了基本的概率概念全书所使用的。
2.3描述了机器人环境交互的正式的模型,提出了本书中被使用的关键术语。
2.4介绍了贝叶斯滤波,对于状态估计的递归算法是形成本书中提出的每一个技术的基础。
2.5讨论了表示和计算问题当实现贝叶斯滤波的时候所出现的问题。
2.2概率中基本的概念
这部分使读者熟悉基本的符号和概率事实在本书中所使用的。在概率机器人中,变量比如传感器测量,控制,机器人的状态和它的环境所有都被模型为随机变量。随机变量可能呈现多个值,并且他们这么做是根据具体的概率法则。概率推导是计算这些随机变量法则的过程,这些随机变量从其他的随机变量和观测数据中得出。
让X表示一个随机变量,x表示一个X可能呈现的具体的值。一个标准的随机变量的例子是扔硬币,X可能呈现头和尾,如果X可以呈现的所有值空间是离散的,正如离子一样,如果X是一个扔硬币的结果,我们就写为p(X=x)来表示随机变量X有值x的概率。例如,一个普通的硬币有这么一个特点p(X=head)=p(X=tail)=1/2.离散概率总和为1,即
∑p(X=x)=1.概率总是非负的,即p(X=x)>0。
为了简化这个符号,我们通常忽略详述的随机变量的表示只要可能的话,而是用通常的简写p(x)表示p(X=x)。
本书中的大多数技术解决估计和在连续空间中做决定。连续空间冠以这么一个特征,由随机变量可以表示一个连续的值。除非明确表示,我们假定所有连续随机变量拥有概率密度函数(PDF).一个常见的密度函数是一维的正态分布均值为μ协方差为σ2.正态分布的概率密度函数由以下高斯函数给出:
 -------(2.3)
-------(2.3)
正态分布在本书中有重要作用。我们通常把他们简化为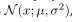 ,说明了随机变量的均值和协方差。
,说明了随机变量的均值和协方差。
正态分布2.3假定x是一个标量值。通常x将是一个多维向量。对向量的正态分布称为多变量。多维的正态分布的概率密度函数时以下形式:
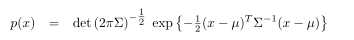 ---(2.4),μ是均值向量,Σ是一个半正定对称矩阵成为协方差矩阵。上标T表示一个向量的转置。the argument in the exponent in this PDF is quadratic in x,and the parameters of this quadratic function are u and Σ.
---(2.4),μ是均值向量,Σ是一个半正定对称矩阵成为协方差矩阵。上标T表示一个向量的转置。the argument in the exponent in this PDF is quadratic in x,and the parameters of this quadratic function are u and Σ.
读者应该花片刻来理解(2.4)是(2.3)的一个普及化。两个是相等的如果x是一个标量值Σ=σ2.
方程(2.3)和(2.4)是一个概率密度函数的例子。正如离散的概率密度分布加起来为1,一个概率密度函数的积分为1: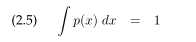
然而,不像离散概率,一个概率密度函数的值上限并不是1.通过本书,我们将用术语,概率,概率密度函数,概率密度相互替换。我们默认所有连续随机变量是可测量的,我们也假定所有连续分布时拥有密度的。
两个随机变量X和Y是联合分布由以下给出:
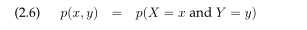




贝叶斯原理在概率机器人(总的来说是概率推导)中占有很重要的地位。
如果x是一个可以通过y推导的变量,概率p(x)被称作对变量X的先验概率分布。如(2.14)表示,贝叶斯规则提供了一种方便计算后验概率p(x|y)的方法运用它的相反的条件概率p(y|x)以及先验概率p(x)。换句话说,如果对从传感器数据y中推导x感兴趣,那么贝叶斯规则允许我们这么做通过相反的概率,该概率指出数据y的概率在x条件下。在机器人学,概率p(y|x)通常被称为生成模型,因为在某种抽象的程度上它描述了状态变量X怎样导致传感器测量变量Y的。
一个重要的观察就是贝叶斯规则的分母p(y)并不依赖于x。因此,因子p(y)-1在方程(2.13)和(2.14)中将会是一样的不管x的值是多少在后验分布p(x|y)中。由于这样,p(y)-1通常被写作归一化变量在贝叶斯规则中, 并且一般表示为η:
p(x|y)=ηp(y|x)p(x)
这种表示法的优点在于它的简洁.而非明确为归一化常数提供确定的表达式--归一化常数在一些数学的推导中会增长得很快---我们将简单的用归一化符号η来表示最后的结果会被归一化为1.纵观全书,这个类型的正规化子将表示为η或者(η‘,η’‘,....)。重要的是:我们将自由的运用同样的η在不同的方程中来表示归一化子,尽管他们的实际值不相同。
我们注意到到目前为止所讨论的任何规则对任何变量都适合,比如变量Z。例如,条件贝叶斯Z=z如下:
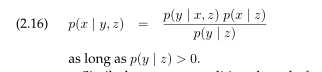


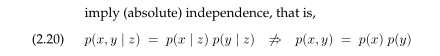
反过来也不是对的:绝对独立并不表示条件独立:
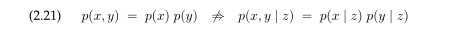
然而,在特别的例子中,条件独立和绝对独立可能一致。
许多概率算法要求我们计算特征或者统计的概率分布。一个随机变量X的期望由以下给出:
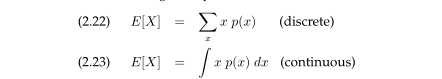
并不是所有的随机变量都拥有有限的期望;然而,哪些变量在本书中没有被提到。

协方差矩阵测量离均值的平均偏差的平方。正如以上所述,多维正态分布N(x;μ,Σ)的均值为μ,它的协方差为Σ。
本书中最后一个重要的概念是熵。一个概率分布的熵由以下表达式给出:
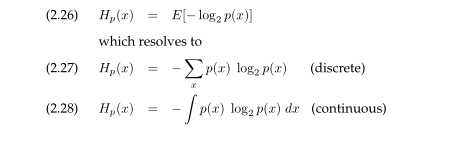
熵的概念起源于信息理论。熵是x值所携带的预期的信息。。。。。。。。。。。。
在离散例子中,-log2p(x)是被要求的比特数来编码x运用一个最优编码,假定p(x)是观测x的概率。在这本书中,熵将被用于机器人信息的聚集,以便去表达机器人可能收到的信息基于执行具体的行为。
2.3 机器人环境交互
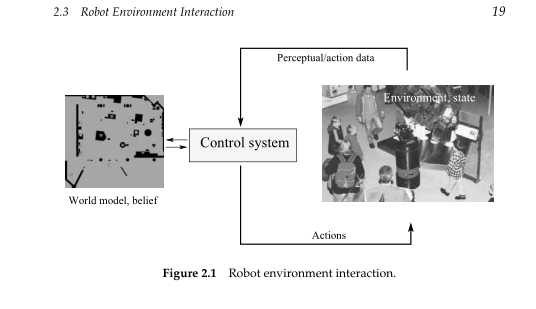
上图表示了机器人与周围环境的交互。环境或者世界,是一个动态系统,拥有内部状态。机器人可以用它的传感器来获得关于环境的信息。然而,传感器有噪声,通常有许多东西都不能直接感知到。结果就是,机器人维持了一个内部的关于环境状态的信任度,在图片的左部分。
机器人也可以通过操作来影响它的环境。这么做的效果通常是具有不可预测性。因此,每一个控制行为既影响了环境 状态,又影响了相对于环境状态的机器人维持的内部信任度。
交互现在将被更正式化描述。
2.3.1状态
环境被称为状态。本书中提供的材料,把状态看作为机器人和它的环境(可以影响将来的)所有方面的集合,这是很方便的。某状态变量趋向于随着时间改变,在机器人附近人的跟踪。其他的趋向于保持静止,比如建筑物的墙的位置。改变的状态被称为动态状态,这区别于静态状态,或者非改变状态。状态也包括关于机器人本身的变量,比如:位姿,速度,不管他的传感器正确起作用与否,等等。
纵观本书,状态将表示为x;尽管具体的变量被包含于x中的将取决于上下文。在t时刻的状态表示为xt。在本书中典型的状态变量是:
机器人位姿,包括相对于全局坐标系的位置和方向。刚体移动机器人拥有6个状态变量,三个笛卡儿坐标,三个他们的方向角(倾斜,横滚,偏航)。对于限制于平面环境的刚体机器人,位姿通常由三个变量给出,在平面的坐标位置和它的偏航角。
在机器人的操作中,位姿包括对于机器人的执行机构的配置变量。例如:他们可能包括转动关节的关节角,在机器人手臂中的每一个自由度被称为在任何时间点的一维的配置,这是机器人运动状态的一部分。机器人配置通常被称为运动学状态。
机器人速度以及它关节的速度被称为动态状态。一个刚体机器人移动通过一个空间有六个速度变量,一个对于每一个位姿变量。本书中动态状态有很小的作用。
在环境中周围物体的位置和特征也被称为状态变量。一个物体可能是一棵树,一面墙,在一个很大平面上的一个点。这些物体的特征可能是他们的视觉外观(颜色,纹理)。取决于被模型的状态饿粒度,机器人环境拥有在数十道数百十亿的状态变量(甚至更多)。想象一下,这要多少比特才能精确描述物理环境。在本书中已经研究了许多问题,环境中的物体位置是静态的。在一些问题当中,物体将假定为路标的形式,它是可区别的,静态的环境特征可以被可靠的识别。
移动物体和人的位置和速度也是潜在的状态变量。通常,在环境中机器人不是唯一的移动因素。其他的移动实体拥有他们自己的运动的和动态的状态。

完全状态:如果这是最好的未来的预测,那么状态xt将被称为完全的。换句话说,完全包含了过去状态,测量,或者控制的知识,没有携带附加的信息,这将帮助我们更精确的预测未来。这是很重要的注意到完全的定义并不要求将来是状态的决定性函数。将来可能是随机的,但是没有先于xt的变量可以影响将来状态的随机发展,除了这个依赖是通过xt作为中介,满足这些条件的临时过程通常被称为马尔可夫链。
状态完全性的概念是理论上重要的。在实践中,对于一个任何的现实机器人系统来说指明一个完全的状态是不可能的。一个完全的状态不仅包括影响将来环境的所有方面,而且还有机器人本身,计算机存储的内容,周围人的大脑转储等等。其中一些是很难获得的。因此实际实现挑出所有状态变量的一个子集,比如,以上列出的。这样的一个状态称为非完全状态。
在大多数机器人应用当中,状态是连续的,意味着xt对一个连续统一体的定义。一个好的连续状态空间的例子是机器人位姿,也就是,它的位置和方向相对于外部坐标系。有时,状态是离散的。一个离散的状态空间的例子是状态变量模拟是否是传感器坏了。状态空间即包括连续的又包括离散的变量称为混合状态空间。
在大多数有兴趣的机器人问题中,状态随时间的改变。在本书中,时间是离散的,即,所有感兴趣的事件将发生在离散的时间步t=0,1,2,...如果机器人开始它的操作在一个可区别的时间点上,我们将表示这个时间为t=0.
2.3.2 环境交互
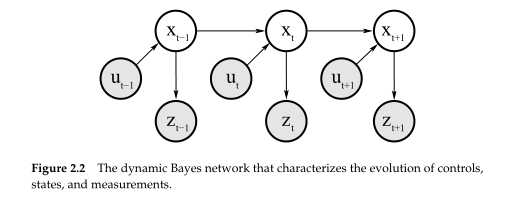
在机器人和它的环境之间有两种基本的交互类型:机器人可以影响环境的状态通过它的制动器,它可以收集信息关于状态的通过传感器。两个交互的类型可能同时发生。但是为了解说的原因,我们将在本书中分开,交互在图2.1中表示。
环境传感器测量。


假设,机器人可以保持所有去过传感器数据和控制的记录,我们将把这个集合称为数据(不管他们是否被存储),根据两类环境交互的例子,机器人有两个不同的数据流。
环境测量数据提供关于环境瞬时状态的信息。测量数据的例子包括相机图像,距离扫描等等。对于大多数而言,我们将简单忽略很小的及时效应(例如,大多数激光传感器以非常高的速度连续扫描环境,但是我们只假定对应于具体时间点的测量)。在t时刻的测量数据表示为zt。

控制数据携带改变环境中状态的信息。在移动机器人学中,一个典型的控制数据例子是机器人的速度。把速度设置为每秒10cm,在经过5秒的时间表明机器人位姿,在执行了这个运动命令后,在它位姿(控制执行之前)之前50cm。因此,控制表达了关系状态改变的信息。


在测量和控制之间的区别是一个关键,两种类型的数据对于即将讨论的都是根本不同的作用。环境感知提供关于环境状态的信息,因此它倾向于增加机器人的知识。另一方面,运动倾向于引发知识的丢失由于在机器人驱动以及机器人环境的随机性固有的噪声。我们的区别绝不是打算去说明行动和感知是在时间上分开的。相反,感知和控制室同时发生的。我们的分开在只是为了方便。
2.3.3 概率生成法
状态和测量的演变史有概率法则管理。一般来说,状态xt从状态xt-1随机生成。因此,表明从概率分布中生成xt是由道理的。乍看一眼,状态xt的出现可能条件基于所有过去状态,测量,和控制。因此,概率法则 描述了状态的演变可能用以下形式的概率分布来给出: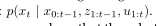
注意没有特别的动机,我们认为在这儿机器人首先执行控制行为u1,然后获取一个观测z1.
一个重要的洞察力是:如果状态x是完全的然后它是一个充分的在先前时间步发生的总结。特别是,xt-1是一个充分的所有先前的控制和测量直到这个时间点的统计特性,也就是,u1:t-1和z1:t-1。从以上表达式中所有的变量,如果我们知道状态xt-1,只有控制量ut是重要的。
在概率属于中,这个洞察力用以下等式表达:
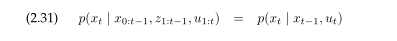
由这个等式所表达的是一个条件独立的例子。这表明某个变量与其他变量独立如果一个已经知道第三个变量组的值,这个条件变量。在本书中条件独立被广泛的应用。这是主要的原因为什么本书中提到的许多算法计算是可以进行的。
我们也想模拟这个过程在过程中形成的测量。再一次如果xt是完全的,那么我们有一个重要的条件独立性:
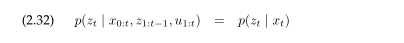
换句话说,状态xt对于预测观测量zt(含有潜在的噪声)是充分的。任何其他变量的知识,比如过去测量,控制,甚至过去状态,是不相关的如果xt是完全的。
这个讨论给出两个条件独立概率是: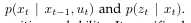 .
.
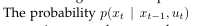 是状态转移概率。指出环境状态随时间怎样改变作为机器人控制ut的一个函数。机器人环境是随机的,这由一个事实所反映,
是状态转移概率。指出环境状态随时间怎样改变作为机器人控制ut的一个函数。机器人环境是随机的,这由一个事实所反映,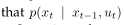 是一个概率分布,并不是一个决定性的函数。有时状态转移概率并不依赖于时间索引t,这样我们可以写为
是一个概率分布,并不是一个决定性的函数。有时状态转移概率并不依赖于时间索引t,这样我们可以写为
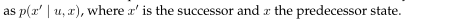
概率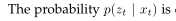 被称为观测概率。
被称为观测概率。

2.3.4 信任度分布(Belief Distributions)
在概率机器人学中另一个重要的概念是信任度。一个信任度反映了机器人的内部知识关于环境状态的。我们已经讨论了状态不能直接测量。例如,一个机器人的位姿可能是xt=<14.12,12.7,45。>在某个全局坐标系统中,但是它通常不知道它的位姿,因为位姿是不可直接测量的(即使是GPS也不能!)。相反,机器人必须从数据中推断它的位姿。因此我们要从他的内部信任度(相对于状态的)中区别于真实状态。在文献中与信任度是同义词的是这个术语-知识状态和信息状态(不要与下面要讨论的信息矩阵和信息向量搞混)。概率机器人学通过条件概率分布来表示信任度。一个信任度分布把一个概率(或者密度值)指定给每一个相对于真实状态的可能假设。信任度分布时对基于可用数据的条件下状态变量的分布。我们将表示对状态变量xt的信任度bel(xt)来表示,这是一个对后验分布的简写:

读者可能注意到我们默认这个信任度被获取,在加入了观测量zt之后。偶尔,这将证明在计算一个后验概率在融入zt之前是有用的,仅仅在执行了控制ut之后。这样一个后验概率将表示为如下:
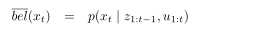 这个概率分布被称作预测在概率滤波上下文中。这个术语反映了这个事实
这个概率分布被称作预测在概率滤波上下文中。这个术语反映了这个事实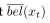 预测t时刻的状态在基于先前的状态后验分布上,在融入t时刻测量之前。
预测t时刻的状态在基于先前的状态后验分布上,在融入t时刻测量之前。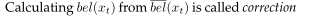
标签:
原文地址:http://www.cnblogs.com/gary-guo/p/5129102.html