标签:
寒假开始学习一些简答的爬虫并且做一些有意义的事情。
首先,百度一下爬虫的意思:
网络爬虫:网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
我所理解的最简单的爬虫的意思就是将网页上的内容抓取下来,然后在进行其他的一些行为。那么首先就要获得一个网页。
那么如何获得一个网页呢,首先要知道这个页面的URL,就以百度为一个例子,百度的URL为:http://www.baidu.com/。Java中的URL类可以获取一个URL。
那么这个URL获取到了之后会被当成一个文件处理,也就是说URL当做一个文件输入流读取进来。
读取完这个URL所对应的资源之后,我们可以让他显示出来:
先看看代码:
1 public class TestSp1 { 2 public static void main(String[] args){ 3 try { 4 URL pageURL=new URL("http://www.baidu.com"); 5 InputStream input=pageURL.openStream(); 6 Scanner scanner = new Scanner(input, "utf-8"); 7 String text = scanner.useDelimiter("//a").next(); 8 System.out.println(text); 9 } catch (MalformedURLException e) { 10 e.printStackTrace(); 11 } catch (IOException e) { 12 e.printStackTrace(); 13 } 14 } 15 }
首先访问百度页面,然后读取流的内容,之后输出,得到的结果如下:
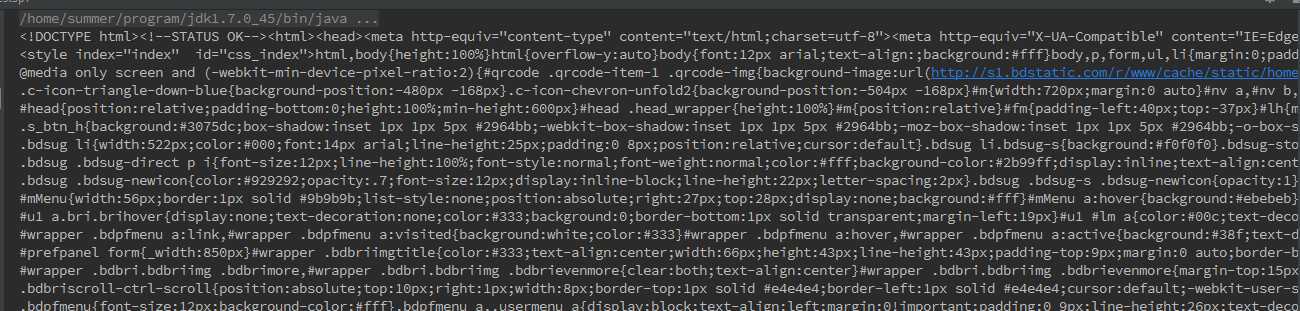
那么这一串代码是什么呢?我们可以访问一下百度的页面看一下百度网页的源代码。下面是我用谷歌浏览器访问百度之后查看的源代码:

经过对比我们可以发现是一样的,也就是说我们读取到的网页实际上就是一个html文件,将服务器上的html文件读取出来,然后输出到控制台上就好了。
这就是爬虫的第一步,不过据说,实际上网络换进会比较复杂,所以使用java.net中的API工作量会非常大的,所以实际开发中会有现成的开源包,Apache下含有Http客户端的jar包,叫做HttpClient.jar
那么使用HttpClient这个工具怎么获得百度的网页呢?
首先需要两个包
第二个logging这个包如果没有程序是无法正常工作的,所以第二个必须有。之后代码就改成了这个:
1 public class TestSp2 { 2 public static void main(String[] args){ 3 HttpClient httpClient=new HttpClient(); 4 GetMethod get=new GetMethod("http://www.baidu.com/"); 5 try { 6 int num=httpClient.executeMethod(get); 7 System.out.println(num); 8 } catch (IOException e) { 9 e.printStackTrace(); 10 } 11 12 try { 13 System.out.println(get.getResponseBodyAsString()); 14 } catch (IOException e) { 15 e.printStackTrace(); 16 } 17 18 } 19 }
num是用来获得Http状态码这个就不过多的说了,如果正常访问的话会输出200。接下来输出的是页面的内容:

和预期一样,状态码输出为200,表示访问正常,然后就是HTML页面的内容。
=========================================

标签:
原文地址:http://www.cnblogs.com/Summer7C/p/5136619.html