标签:
昨晚听了王家林老师的第13课Spark内核架构解密,课堂笔记如下:
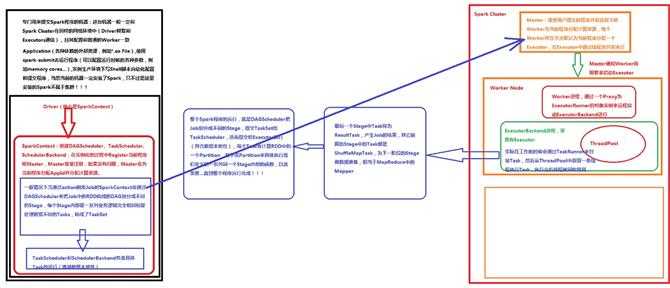
executor中线程池并发执行和复用,Spark executor, backed by a threadpool to run tasks.
默认一个work为一个Application只开启一个executor。一个worker里executor是多点好还是少点好,看具
体情况。
Worker:管理当前Node机器资源,并接受Master的指令来分配具体的计算资源Executor(使用ExecutorRunner
在新的进程中分配),是工头不是工人,使用Proxy来管理Executor。
job是包含task的一系列作业,action来触发,action不会产生RDD,只会run job.
Stage内部:计算逻辑完全一样, 只是计算的数据不同罢了。
Sparkcontext是核心,创建DAGSchedular,TaskScheduler,SchedulerBackend.
SparkContext通过DAGScheduler将job中RDD形成的DAG有向无环图划分为不同的Stage ,TaskScheduler会将不同Stage中的一系列的Task发送到对应的Executor去执行,而Stage内部:计算逻辑完全一样, 只是计算的数据不同罢了。
后续课程可以参照新浪微博 王家林_DT大数据梦工厂:http://weibo.com/ilovepains
王家林 中国Spark第一人,微信公共号DT_Spark
标签:
原文地址:http://www.cnblogs.com/haitianS/p/5137221.html