标签:
在HDFS HA(http://www.cnblogs.com/yinchengzhe/p/5140117.html)基础上进行yarn的安装。
1、配置yarn-site.xml
参数详情参考 http://www.cnblogs.com/yinchengzhe/p/5142659.html
配置如下:
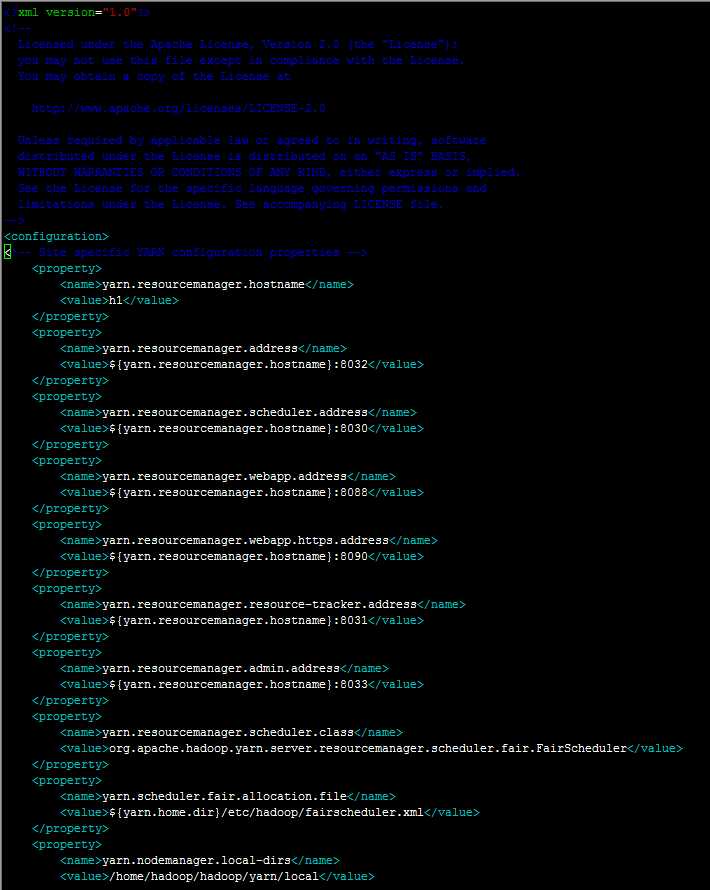
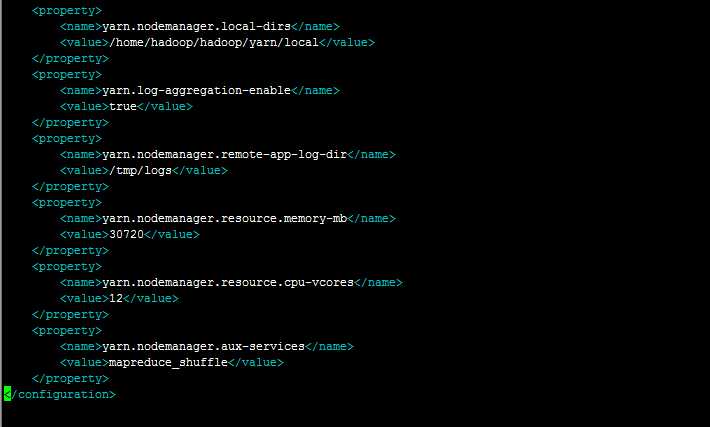
2、配置mapred-site.xml
在${HADOOP_HOME}/etc/hadoop/下,将mapred-site.xml.templat重命名成mapred-site.xml
配置如下:
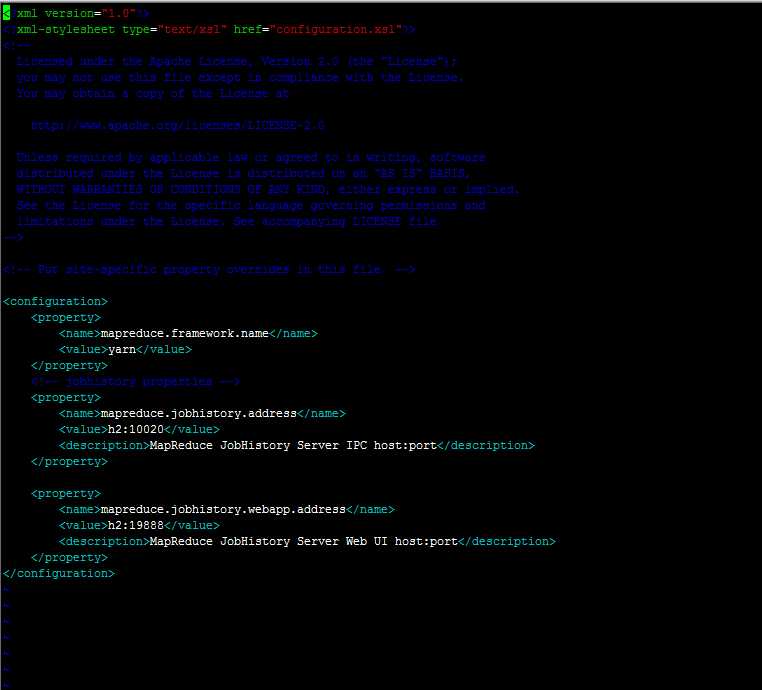
相比于Hadoop1.0,用户无需再配置mapred.job.tracker,这是因为JobTracker已变成客户端的一个库,他可能被随机调度到任何一个slave上,也就是它的位置是动态生成的
3、启动关闭
在h1上启动yarn,执行
> sbin/start-yarn.sh
在h2上启动JobHistory Server,执行
> sbin/mr-jobhistory-daemon.sh start historyserver
注:Hadoop启动jobhistoryserver来实现web查看作业的历史运行情况,由于在启动hdfs和Yarn进程之后,jobhistoryserver进程并没有启动,需要手动启动
jobhistory配置可参照 http://www.cnblogs.com/yinchengzhe/p/5142659.html
关闭 sbin/stop-yarn.sh
标签:
原文地址:http://www.cnblogs.com/yinchengzhe/p/5142800.html