标签:Lucene style blog http java 使用
本文配置环境:solr4.6+ IK2012ff +tomcat7
在Solr4.0发布以后,官方取消了BaseTokenizerFactory接口,而直接使用Lucene Analyzer标准接口TokenizerFactory。因此IK分词器2012 FF版本也取消了org.wltea.analyzer.solr.IKTokenizerFactory类。
这里IK的文档给了一个solr的配置如下:
|
<fieldType name="text" class="solr.TextField"> <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType> |
这个配置不能实现分词器的智能选择和同义词、停用词配置功能。
这里通过开发一个IKAnalyzerTokenizerFactory类继承Lucene Analyzer标准接口TokenizerFactory来实现上述功能。
package org.wltea.analyzer.lucene;
import java.io.Reader;
import java.util.Map;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.util.TokenizerFactory;
import org.apache.lucene.util.AttributeSource.AttributeFactory;
public class IKAnalyzerTokenizerFactory extends TokenizerFactory{
private boolean useSmart;
public boolean useSmart() {
return useSmart;
}
public void setUseSmart(boolean useSmart) {
this.useSmart = useSmart;
}
public IKAnalyzerTokenizerFactory(Map<String, String> args) {
super(args);
assureMatchVersion();
this.setUseSmart(args.get("useSmart").toString().equals("true"));
}
@Override
public Tokenizer create(AttributeFactory factory, Reader input) {
Tokenizer _IKTokenizer = new IKTokenizer(input , this.useSmart);
return _IKTokenizer;
}
}
将IKAnalyzerTokenizerFactory编译放入到IK2012ff的jar包中。
在schema.xml文件中配置:
<!--IKAnalyzer-->
<fieldType name="text_ik" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKAnalyzerTokenizerFactory" useSmart="false"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKAnalyzerTokenizerFactory" useSmart="true"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
</analyzer>
</fieldType>
注意:synonyms.txt 在添加中文后需要保存为无BOM UTF-8格式,否则分词报错。
效果如下:
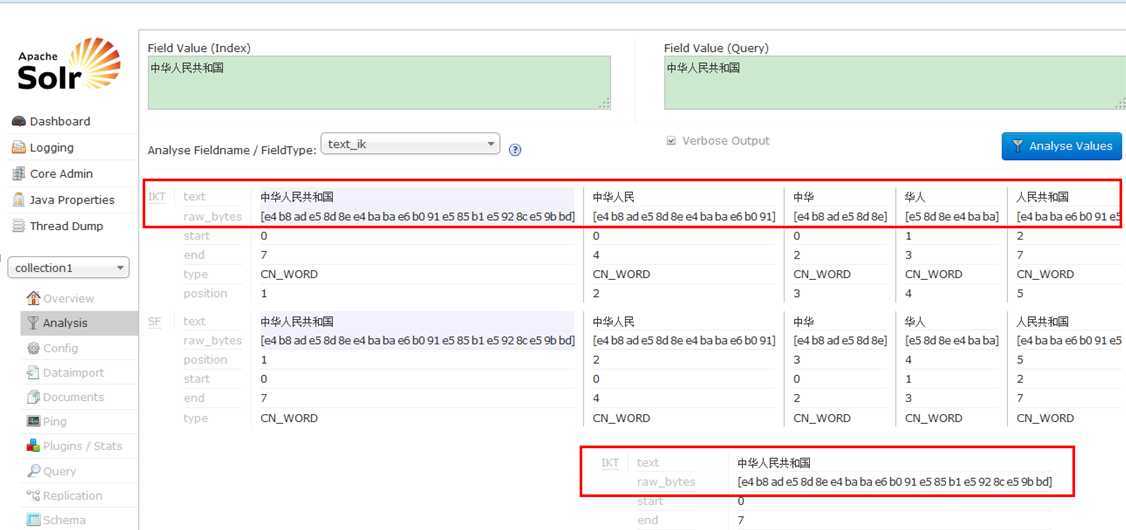
solr4.x配置IK2012FF智能分词+同义词配置,布布扣,bubuko.com
标签:Lucene style blog http java 使用
原文地址:http://www.cnblogs.com/a198720/p/3863721.html