标签:style blog http java color 使用
问:
今天花一天时间给centos6.3 64bit的系统搭建了hadoop,顺便把hive和mysql也装上了,测试什么的都没问题。
但是,迷茫了,我怎么用它分析网站的日志。他的工作原理迷迷糊糊的,
而且我这个hadoop用的是hadoop-2.0.2-alpha版本,jps发现没有JobTracker和TaskTracker进程啊。但是做实验的时候还不报错,
难道这个版本没有这两个进程?这可是关键进程啊。
这个在实际当中具体怎么用?
比如我想分析网站的访问日志,我需要把所有节点的日志都put到hdfs上?在用hive加载到表中?在select一下吗?
貌似我这想的不对啊。
答:
2.0.0是从hadoop 0.23.x发展出来的。取消了jobtracker和tasktracker,或者说,是把这两个封装到了container里面。使用YARN替代了原来的map/reduce。
YARN号称是第二代map/reduce,速度比一代更快,且支持集群服务器数量更大。hadoop 0.20.x和由其发展过来的1.0.x支持集群数量建议在3000台左右,最大支持到4000台。而hadoop 2.0和YARN宣称支持6000-10000台,CPU核心数支持200000颗。从集群数量和运算能力上说,似乎还是提高了不少的。并且加入了namenode的HA,也就是高可用。

摘要:本文从Hadoop的初衷、大数据时代背景、Hadoop的使用者来探讨“Hadoop能做什么”这个问题。
Hadoop是Doug Cutting 基于Google公司的GFS和MapReduce思想不断完善项目Nutch中脱胎而出的。
Hadoop是适合于大数据的分布式存储和处理平台,是一种开源的框架。
大数据时代已经到来,给我们的生活、工作、思维方式都带来变革。如何寻求大数据后面的价值,既是机遇又是挑战。不管是金融数据、还是电商数据、又还是社交数据、游戏数据.......这些数据的规模、结构、增长的速度都给传统数据存储和处理技术带来巨大考验。幸运的是,Hadoop的诞生和所构建成的生态系统给大数据的存储、处理和分析带来了曙光。
不管是国外的著名公司Google、Yahoo!、微软、亚马逊、 EBay、FaceBook、Twitter、LinkedIn等和初创公司Cloudera、Hortonworks等,又还是国内的著名公司中国移动、阿里巴巴、华为、腾讯、百度、网易、京东商城等,都在使用Hadoop及相关技术解决大规模化数据问题,以满足公司需求和创造商业价值。
例如:Yahoo! 的垃圾邮件识别和过滤、用户特征建模;Amazon.com(亚马逊)的协同过滤推荐系统;Facebook的Web日志分析;Twitter、LinkedIn的人脉寻找系统;淘宝商品推荐系统、淘宝搜索中的自定义筛选功能......这些应用都使用到Hadoop及其相关技术。
“Hadoop能做什么?” ,概括如下:
1、搜索引擎(Doug Cutting 设计Hadoop的初衷,为了针对大规模的网页快速建立索引)。
2、大数据存储,利用Hadoop的分布式存储能力,例如数据备份、数据仓库等。
3、大数据处理,利用Hadoop的分布式处理能力,例如数据挖掘、数据分析等。
4、科学研究,Hadoop是一种分布式的开源框架,对于分布式计算有很大程度地参考价值。
Source:
1 http://www.wangluqing.com/2014/02/hadoop-doing/
2 Who uses Hadoop? http://wiki.apache.org/hadoop/PoweredBy
3 Who We Are? http://hadoop.apache.org/who.html
4 http://blog.sina.com.cn/s/blog_687194cd01017lgu.html
5 http://thinkinginhadoop.iteye.com/blog/709947
百度作为全球最大的中文搜索引擎公司,提供基于搜索引擎的各种产品,几乎覆盖了中文网络世界中所有的搜索需求,因此,百度对海量数据处理的要求是比较高的,要在线下对数据进行分析,还要在规定的时间内处理完并反馈到平台上。百度在互联网领域的平台需求要通过性能较好的云平台进行处理了,Hadoop就是很好的选择。在百度,Hadoop主要应用于以下几个方面:
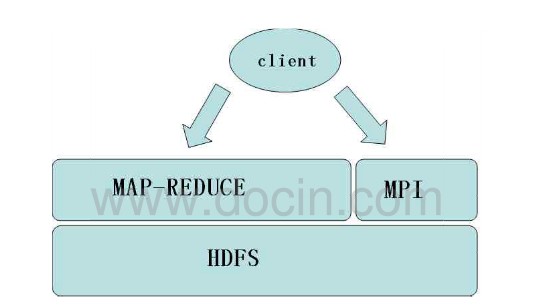
MapReduce主要是一种思想,不能解决所有领域内与计算有关的问题,百度的研究人员认为比较好的模型应该如下图:
HDFS实现共享存储,一些计算使用MapReduce解决,一些计算使用MPI解决,而还有一些计算需要通过两者来共同处理。因为MapReduce适合处理数据很大且适合划分的数据,所以在处理这类数据时就可以用MapReduce做一些过滤,得到基本的向量矩阵,然后通过MPI进一步处理后返回结果,只有整合技术才能更好地解决问题。 百度现在拥有3个Hadoop集群,总规模在700台机器左右,其中有100多台新机器和600多台要淘汰的机器(它们的计算能力相当于200多台新机器),不过其规模还在不断的增加中。现在每天运行的MapReduce任务在3000个左右,处理数据约120TB/天。 百度为了更好地用Hadoop进行数据处理,在以下几个方面做了改进和调整: (1)调整MapReduce策略 限制作业处于运行状态的任务数; 调整预测执行策略,控制预测执行量,一些任务不需要预测执行; 根据节点内存状况进行调度; 平衡中间结果输出,通过压缩处理减少I/O负担。 (2)改进HDFS的效率和功能 权限控制,在PB级数据量的集群上数据应该是共享的,这样分析起来比较容易,但是需要对权限进行限制; 让分区与节点独立,这样,一个分区坏掉后节点上的其他分区还可以正常使用; 修改DFSClient选取块副本位置的策略,增加功能使DFSClient选取块时跳过出错的DataNode; 解决VFS(Virtual File System)的POSIX(Portable Operating System Interface of Unix)兼容性问题。 (3)修改Speculative的执行策略 采用速率倒数替代速率,防止数据分布不均时经常不能启动预测执行情况的发生; 增加任务时必须达到某个百分比后才能启动预测执行的限制,解决reduce运行等待map数据的时间问题; 只有一个map或reduce时,可以直接启动预测执行。 (4)对资源使用进行控制 对应用物理内存进行控制。如果内存使用过多会导致操作系统跳过一些任务,百度通过修改Linux内核对进程使用的物理内存进行独立的限制,超过阈值可以终止进程。 分组调度计算资源,实现存储共享、计算独立,在Hadoop中运行的进程是不可抢占的。 在大块文件系统中,X86平台下一个页的大小是4KB。如果页较小,管理的数据就会很多,会增加数据操作的代价并影响计算效率,因此需要增加页的大小。 百度在使用Hadoop时也遇到了一些问题,主要有:
百度下一步的工作重点可能主要会涉及以下内容:
百度同时也在使用Hypertable,它是以Google发布的BigTable为基础的开源分布式数据存储系统,百度将它作为分析用户行为的平台,同时在元数据集中化、内存占用优化、集群安全停机、故障自动恢复等方面做了一些改进。 |
标签:style blog http java color 使用
原文地址:http://my.oschina.net/MrMichael/blog/294228