标签:
昨天深夜,突然朋友找我帮忙,下载斯巴鲁的技术文档。原本以为是因为某些原因他访问不到国外的网站,结果却让我惊呆了!妈蛋,这pdf有1000多个啊···
朋友在国外的论坛上找到有人可以下载,而且已经贴上了源码,只是他不懂。
这是文档下载的网站:http://techinfo.subaru.com/index.html
其中账号是要钱买的,好新颖的设定:
另:他们规定,账号下载pdf,不得超过每小时50个文件···坑爹啊···
我借用他们的代码(二楼的代码,用python写的那个;十五楼的时间机制,用来防止超过1小时50次的限制),结合现在的情况改动了部分。
现在分享给各位需要的人。
我的python环境是Python 2.7.10的。使用3.4版本的需要改部分代码,修改的只是包名和部分包名下面的方法名,都是简单的操作。
下面上代码~
1 # Pip install required packages and import them 2 import lxml.html, urllib2, urlparse, os, requests, natsort, time 3 from PyPDF2 import PdfFileMerger, PdfFileReader 4 5 # File Downloader 6 def download_file(url, url_splitter=‘/‘): 7 local_filename = url.split(url_splitter)[-1] 8 # 这里是cookie的模拟方法,需要模拟登录 9 headers = { 10 "Host": "techinfo.subaru.com", 11 "User-Agent": "lol", 12 "Cookie": "JSESSIONID=F3CB4654BFC47A6A8E9A1859F0445123" 13 } 14 r = requests.get(url, stream=True, headers=headers) 15 with open(local_filename, ‘wb‘) as f: 16 for chunk in r.iter_content(chunk_size=1024): 17 if chunk: 18 f.write(chunk) 19 f.flush() 20 return local_filename 21 22 # Grab all the PDFs 23 def grab_files(base_url): 24 res = urllib2.urlopen(base_url) 25 tree = lxml.html.fromstring(res.read()) 26 ns = {‘re‘: ‘http://exslt.org/regular-expressions‘} 27 for node in tree.xpath(‘//a[re:test(@href, "\.pdf$", "i")]‘, namespaces=ns): 28 pdflink = urlparse.urljoin(base_url, node.attrib[‘href‘]) 29 print pdflink 30 filename = download_file(pdflink) 31 print("Downloading " + filename + " complete\n") 32 print("sleep 72") 33 time.sleep(72) 34 return(0) 35 36 # Merge the PDFs 37 def merge_pdfs(merged_filename,files_dir=os.getcwd()): 38 pdf_files = natsort.natsorted([f for f in os.listdir(files_dir) if f.endswith("pdf")]) 39 merger = PdfFileMerger() 40 for filename in pdf_files: 41 print("Merging " + filename) 42 merger.append(PdfFileReader(os.path.join(files_dir, filename), "rb")) 43 merger.write(os.path.join(files_dir, merged_filename)) 44 print("Merge Completed - " + merged_filename) 45 return(merged_filename) 46 47 #这里是下载pdf的网页列表 48 grab_files(‘http://techinfo.subaru.com/search/listResults.html?searchLit=Search&litNum=G2520BE‘) 49 merge_pdfs(‘2016_Outback_Legacy_Manual.pdf‘)
解析一下:
1. 第12行的cookie,需要借用浏览器,然后找到cookie来做。简单的就是用chrome浏览器。如下图:
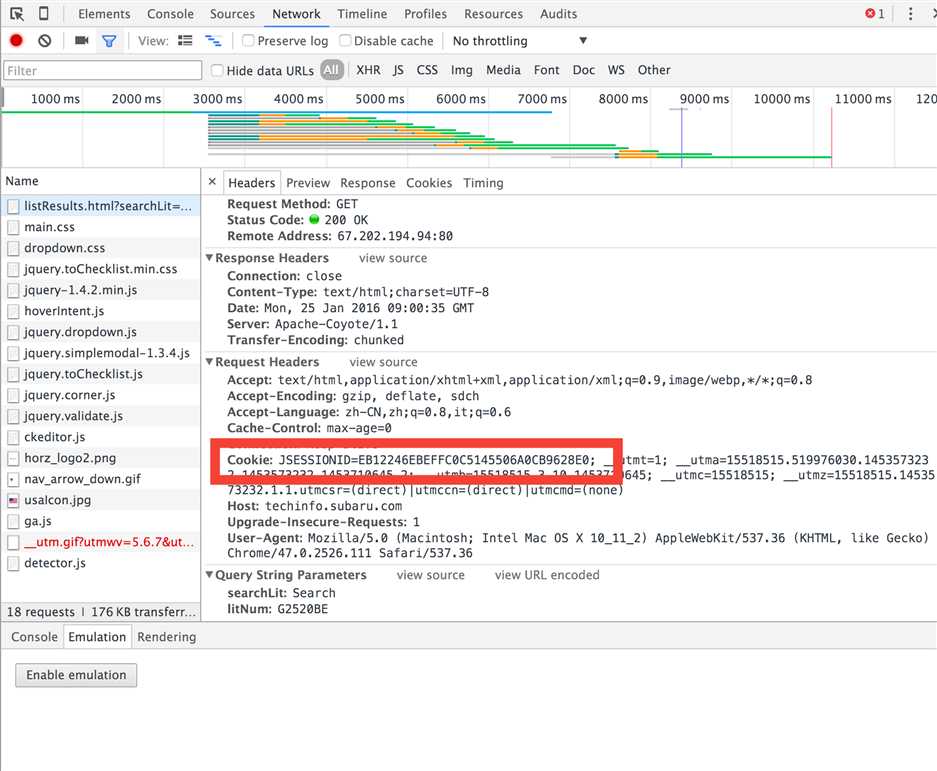
2. 第48行,其中的连接地址就是你需要下载的pdf文档的地址。斯巴鲁的pdf下载好像是在搜索页面中才能出现的。略奇葩啊···
3. 第49行,是合并pdf的代码,毕竟1000+个文档,分开放着够乱啊···(当然也可以选择不合并)
好啦,至此就可以运行代码跑跑跑啦~
如果使用python 3.4,代码修改的时候,请注意:
1. 引用urllib2应该是需要改为引用urllib,官网可以查到urblib2被改为了urllib3,但是在实际使用的时候,我记得后面有个方法又需要把他改为urllib;
2. lxml在引用的时候可能会出现比较大的问题,可以直接下载已经编译好的包。http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml
有问题欢迎留言。
标签:
原文地址:http://www.cnblogs.com/maomishen/p/5158018.html