标签:
preision与recall之间的权衡

依然是cancer prediction的例子,预测为cancer时,y=1;一般来说做为logistic regression我们是当hθ(x)>=0.5时,y=1;
当我们想要在预测cancer更确信时(因给病人说他们有cancer会给他们带来很重大的影响,让他们去治疗,所以想要更确信时再告诉病人cancer的预测): 我们可以将阀值设为0.7,这时我们将有一个高的precision(因为标注出有cancer的都是很确信的),和一个低值的recall;如果将threshold设为0.9--->高的precision,和一个低值的recall
当我们希望避免漏掉患有cancer的病人时(避免假阴性,即我们不希望一个病人有cancer,但是我们却没有告诉他,耽误了他的治疗):将threshold设为0.3,这时我们得到一个低的precision(标出有cancer的有很多都是实际上被误标的)和一个高的recall(因为绝大多数的cancer都被标注出来了).
因此对于大多数的回归模型,我们需要权衡precision与recall。
precision&recall曲线(随着threshold的改变而改变)如上图右边所示,precision&recall曲线有很多种可能性,取决于具体的算法。
那么我们可以自动选取合适的threshold吗?
如何选择合适的threshold
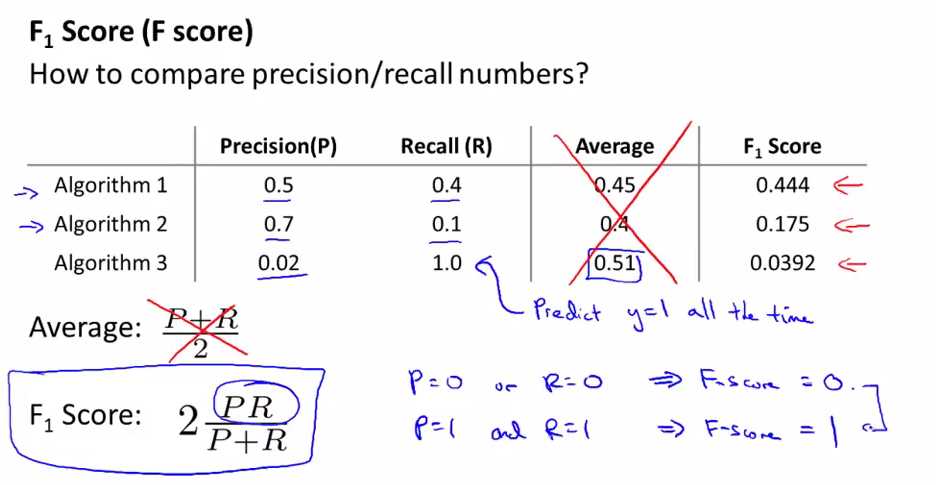
以上三个算法的threshold值不同,即precision与recall值不同,那么我们应该选择上面三个模型中的哪个模型呢?----我们需要一个评估试题值(evaluation metric)来进行衡量。
precison与recall不能做为evaluation metric,因为它们是不同的两个数字(此消彼长)。
如果我们使用平均值来做为这个evaluation metric: 可以看到算法3的平均值是最大的,但是算法3不是一个好的算法,因为我们可以通过将所有的y预测为1(即将threshold降低)来达到高的recall,低的precision,这显然不是一个好的算法,但是它却有很好的average,故我们不能使用average来做为evaluation metric。
F score(或者F1 score): 在机器学习中常用的来衡量precision与recall的evaluation metric(用来选择threshold),当precison与recall中有一个很小时,通过这个公式得到的F值也会很小,这样就防止了我们上面提到的用average来衡量的错误。即只要F值是大的,则precision与recall都较大。
如果precision或者recall有一个为0,F值就为0;如果是很完美的模型,即precision与recall都为1的话,则F值也为1,故现实中F值的范围在0-1之间。
总结
Handling skewed data---trading off precision and recall
标签:
原文地址:http://www.cnblogs.com/yan2015/p/5160384.html