标签:
Hadoop 是 Apache 下一个开源的分布式的软件计算框架,它是由Doug Cutting根据 Google提出的分布式文件系统 GFS 和 MapReduce 编程模型而实现的。Hadoop 由许多部分组成,其核心是用于数据存储的分布式文件系统HDFS与用于分布式计算的 MapReduce 编程模型。HDFS 用于 Hadoop 平台中所有数据文件的存储,采用 master/slave 架构,包含一个名字节点(NameNode)和若干个数据节点(DataNode)。MapReduce 主要是进行分布式计算,由一个 JobTracker 和若干个TaskTracker 组成。
HDFS采用主从式结构,包含三个核心角色:名称节点(NameNode),第二名称节点(SecondNameNode)以及数据节点(DataNode)。并且采用master/slave的架构运行,即一个NameNode和若干个DataNode。一般情况下,在一台机器上运行NameNode实例,而在集群中的其他机器上均运行一个DataNode实例。NameNode是分布式文件系统中的管理者,主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。DataNode是文件存储的基本单元,它将块(Block)存储在本地文件系统中,并且保存了块的元数据,还将周期性地将所有存在的块信息发送给NameNode。下图是HDFS的组成示意图。
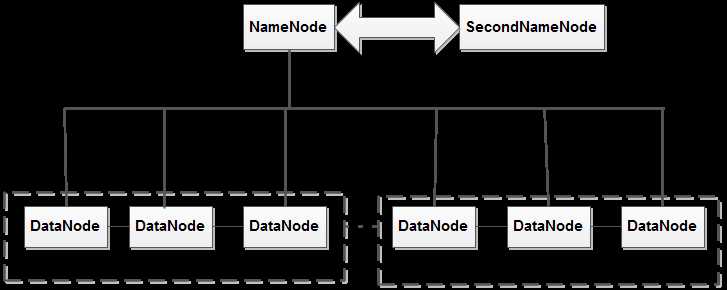
图1 HDFS组成示意图
MapRedude是并行化编程的一种范式。利用并行计算可以把一个庞大的计算任务分解为若干个小的计算任务,将这些小任务在不同的计算机上并行执行,可以在接受的时间内解决使用传统算法难以完成的复杂运算问题。MapReduce被设计成基于数据并行进行编程,用来并行处理大规模数据,并且数据之间没有依赖,不需要负担因保持节点间数据的同步而产生的通信开销,因而可以把工作流划分到集群中的多个机器上去,使得系统在大规模机器上变得可靠和效率高。Hadoop的MapReduce是Google的MapReduce的开源实现,其实质是一样的。从设计思想上来讲,Map就是将一个任务分解成为多个任务,Reduce就是将分解后多任务处理的结果汇总起来,得出最后的分析结果。下图是MapReduce的原理图。
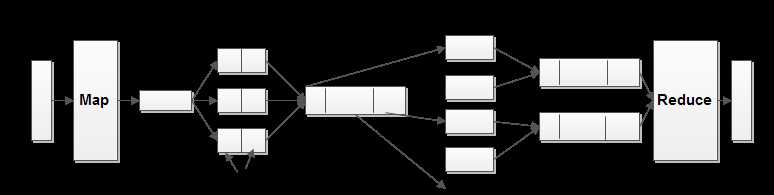
图2 MapReduce原理图
MapReduce主要包括Map端和Reduce端。执行Map任务的过程中,首先将块数据切分成输入分片,每个分片的内容形式是key-value对的形式。经过map函数后将得到一组新的key-value对,这些结果不会直接写入本地磁盘,而是写入到一个环形内存缓冲区。当缓存内容超过某个阈值时,一个后台线程便开始把内容写到磁盘。在写入磁盘之前,缓冲区内的数据会被划分成多个分区,分区是由数据最终被划分到哪一个reducer所决定的,也就是说是由partition接口方法决定。在每个分区中,会将数据按照key进行排序,如果有一个combiner,它将对相同的key进行一次规约操作以减少数据的写入和传输消耗,不过combiner是一个优化函数,它并不一定会执行,但也可能多次应用。这些溢写文件最终被合并成一个已分区并且已排序的输出文件,这个过程叫合并。当有Map任务完成后,可用的Reduce任务通过HTTP拉取map端的数据,如果数据很小,会存储在内存中,否则被写入磁盘。这些混合存储在内存和磁盘上的数据会被合并成一个更大的,排好序的文件。这个合并过程会循环执行,最终的文件会被写入磁盘中。数据形式是key-valuelist,然后reduce过程将输入的相同key的各个value进行规约操作,并将得到的输出写到HDFS上。
标签:
原文地址:http://www.cnblogs.com/yi-fei/p/5161505.html