标签:
Hadoop是一个开源项目,Cloudera对Hadoop进行了商业化,简化了安装过程,并对hadoop做了一些封装。
根据使用的需要,Hadoop集群要安装很多的组件,一个一个安装配置起来比较麻烦,还要考虑HA,监控等。
使用Cloudera可以很简单的部署集群,安装需要的组件,并且可以监控和管理集群。
CDH是Cloudera公司的发行版,包含Hadoop,Spark,Hive,Hbase和一些工具等。
Cloudera有两个版本:
Cloudera Express 版本是免费的
Cloudera Enterprise (60天试用期)需要购买注册码
先安装Cloudrea Manager,再通过Cloudrea Manager在节点上安装Cloudrea Manager客户端,CDH,管理工具。
官方文档:
https://www.cloudera.com/documentation/manager/5-1-x.html
环境需求:
1. 关闭selinux
2. 各节点可以SSH登陆
3. 在/etc/hosts中添加各节点的主机名
可以通过官方的一键安装包,也可以通过yum或rpm安装。
下面介绍用官方的一键安装包安装。
本次安装环境为CnetOS 7,在3台机器上进行安装
test165 (cloudera manager server)
test166 (cloudera manager agent)
test167 (cloudera manager agent)
http://archive.cloudera.com/cm5/installer/latest/
下载最新版: cloudera-manager-installer.bin
在test165上安装cloudera manager server,启动安装向导
# chmod a+x cloudera-manager-installer.bin # ./cloudera-manager-installer.bin
出现下面画面
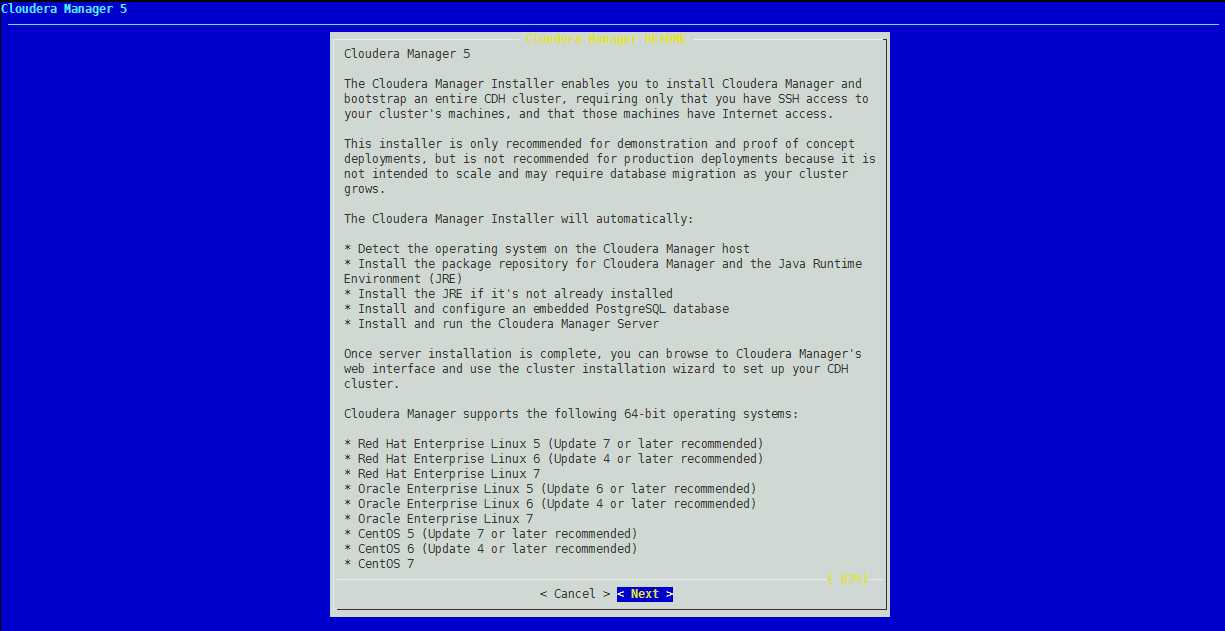
一路选择< Next > 和 < Yes >,开始安装。
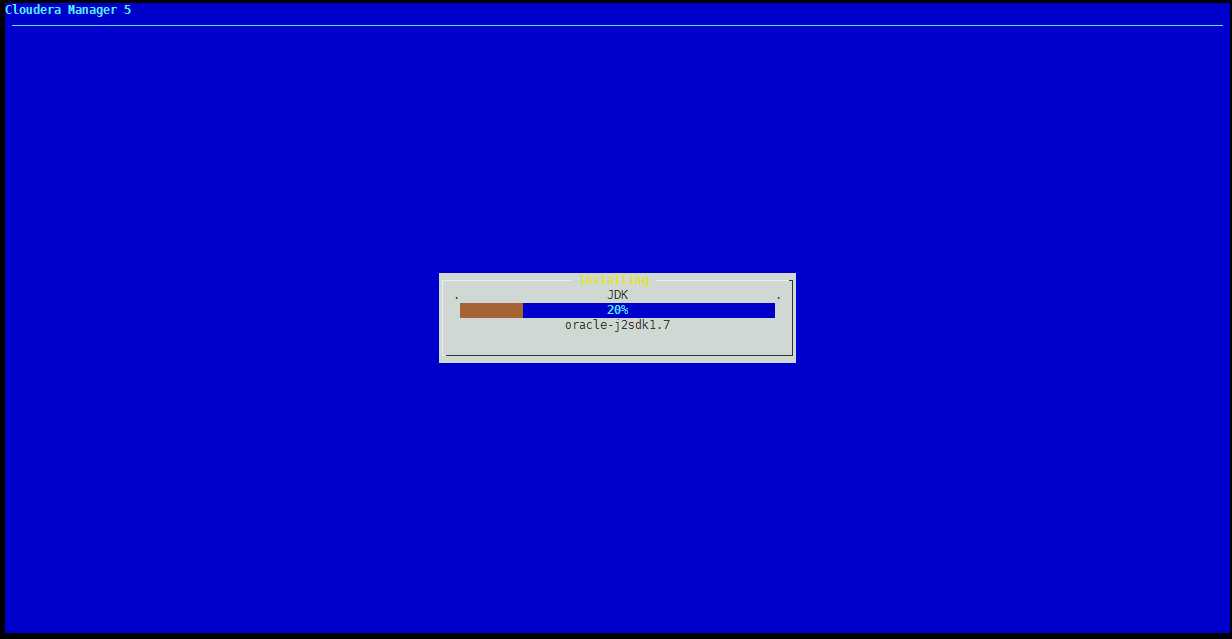
需要下载JAVA和Cloudrea Manager,共600多MB,根据网络情况,会花一些时间。
出现下面页面,安装完成。
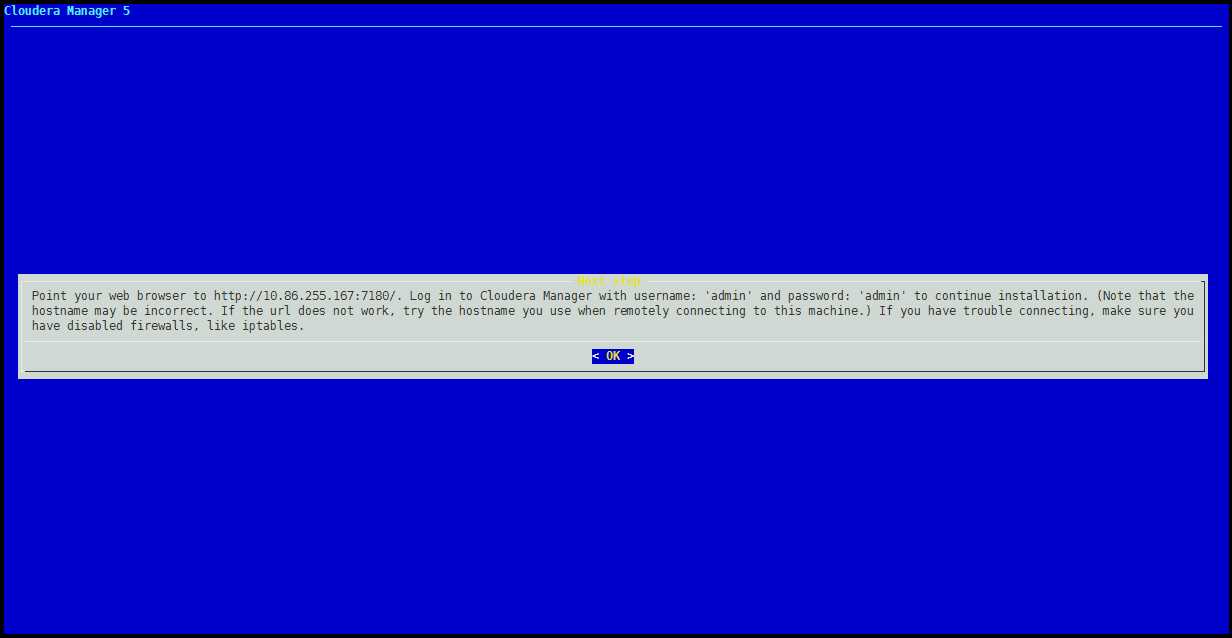
安装完成后,访问Cloudrea Manager的页面,用户名密码都是admin
http://IP或主机名:7180/
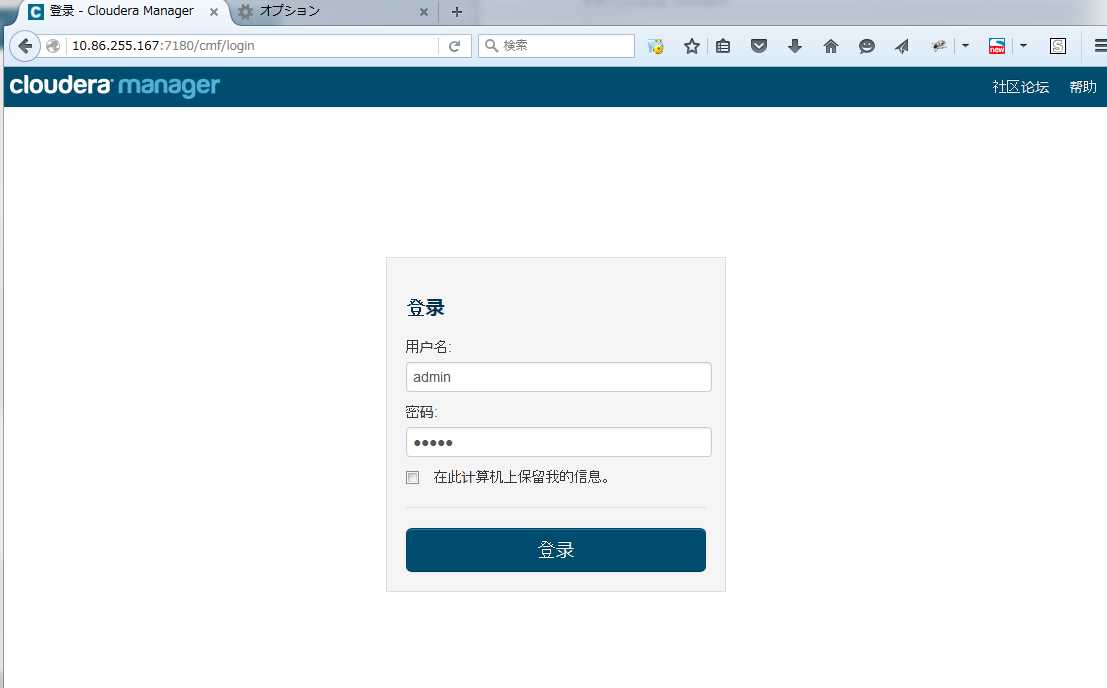
登录Cloudrea Manager页面,选择要安装的版本,本次安装的是Cloudera Express
选择要安装CDH的主机,用主机名或IP搜索,本次是在三个节点上安装CDH
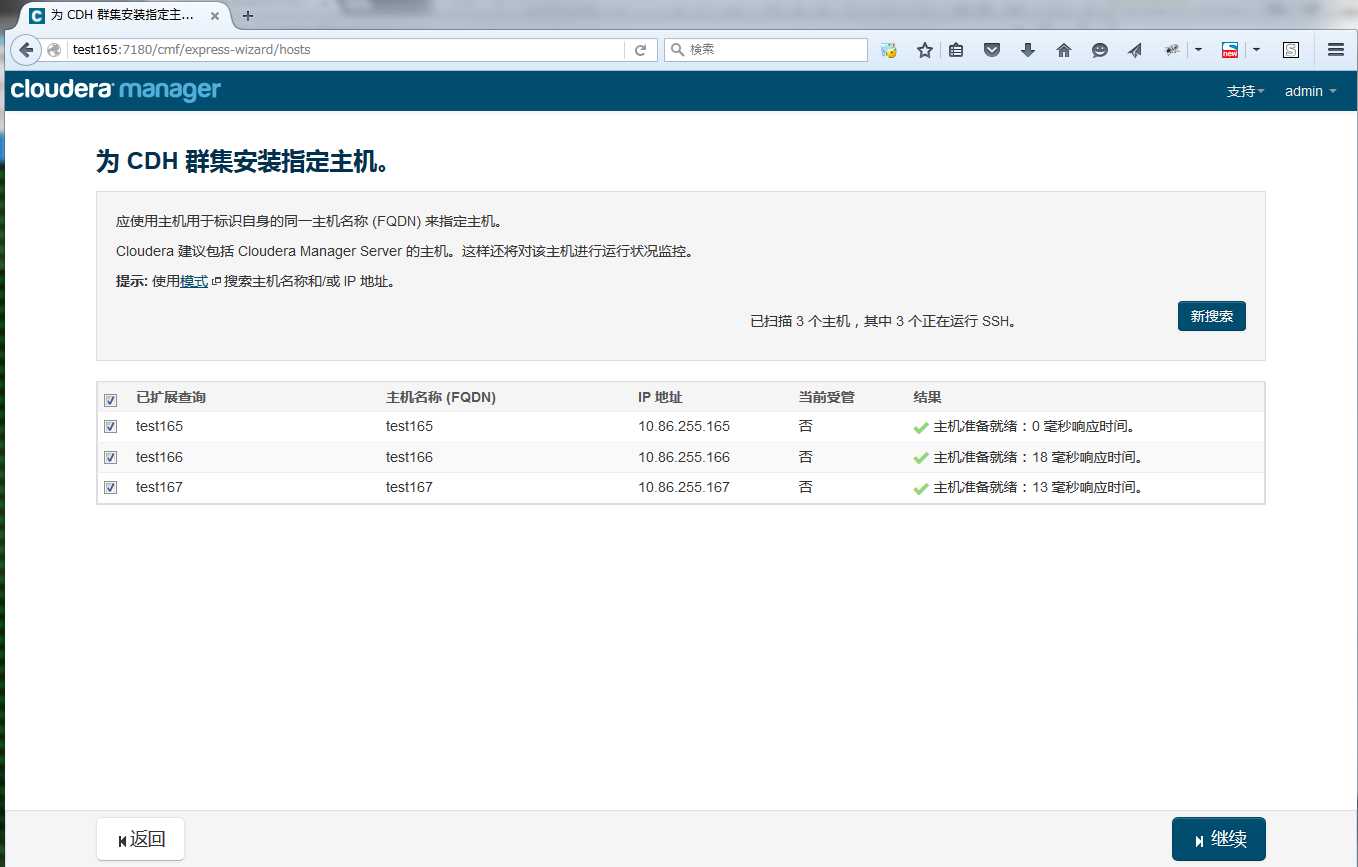
选择使用Parcel安装,选择CDH版本
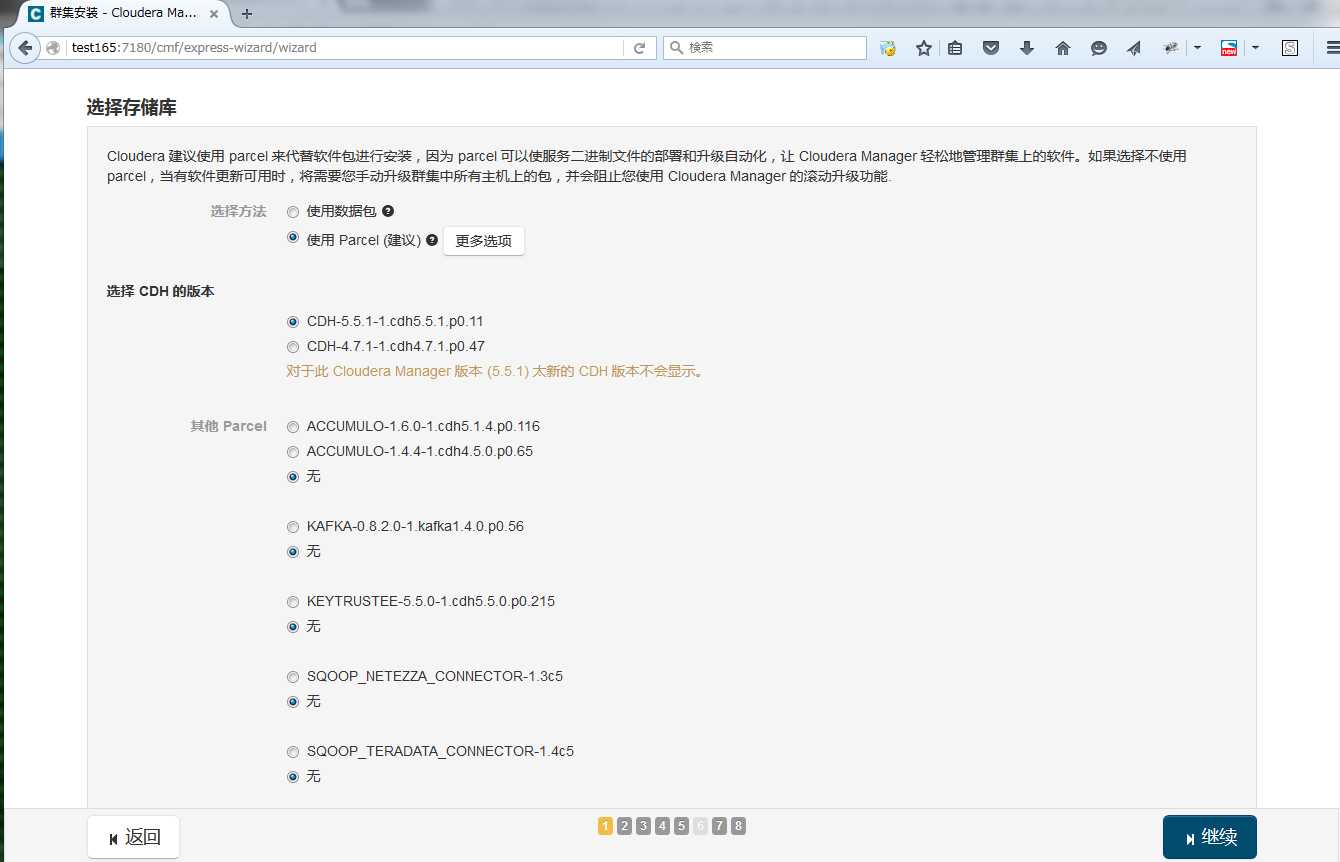
选择安装JDK
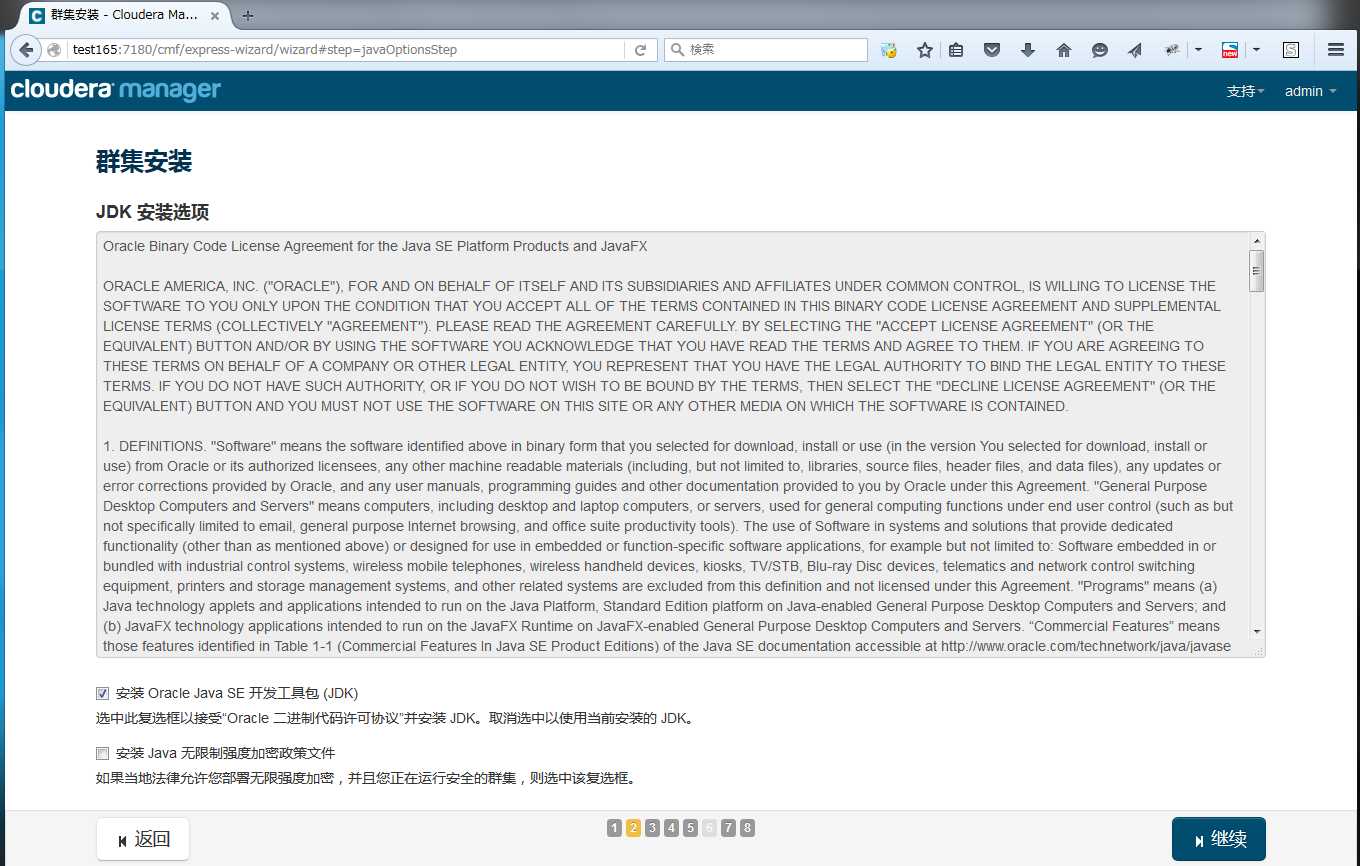
提供SSH登录信息
开始安装JDK和cloudera manager agent
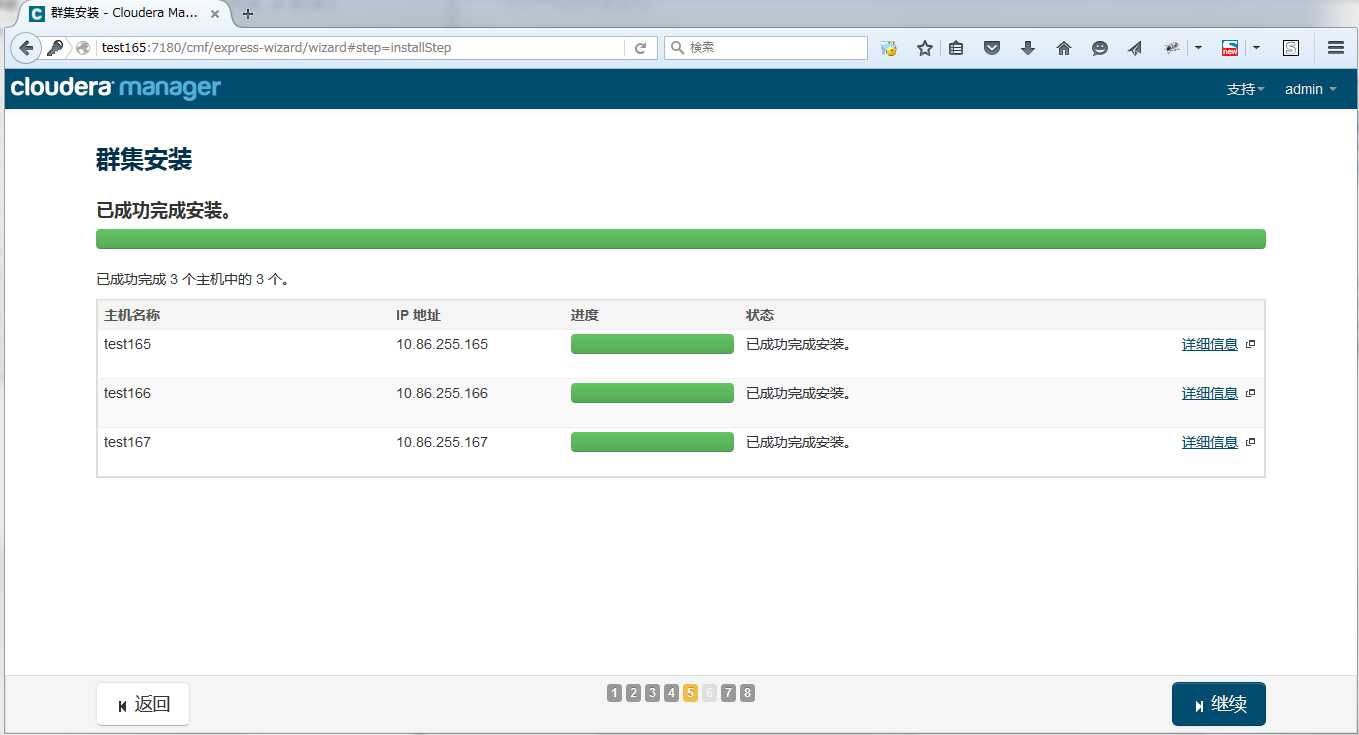
如果安装过程中,下载安装jdk 或 cloudera-manager-agent失败,可以在节点上手动安装,然后再在Cloudrea Manager上继续安装
# yum -y install jdk # yum -y install oracle-j2sdk1.7 # yum -y install cloudera-manager-agent
下载Parcel并分配Parcel到各节点
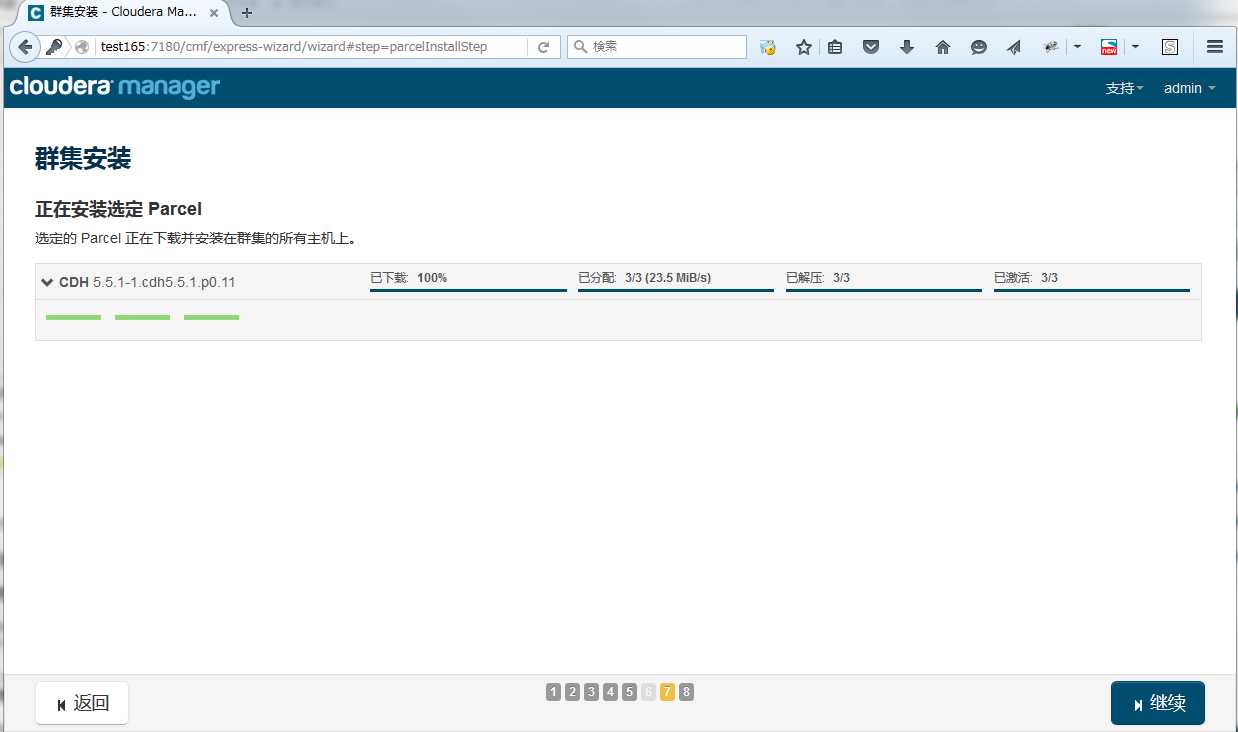
Parcel包1.5G左右,需要一段时间,为了提高安装速度,可以先把包下载到Cloudrea Manager本地,配置本地源
parcel下载地址:
http://archive.cloudera.com/cdh5/parcels/5.5.1/
将下面文件拷贝到/opt/cloudera/parcel-repo/文件夹下
CDH-5.5.1-1.cdh5.5.1.p0.11-el7.parcel
CDH-5.5.1-1.cdh5.5.1.p0.11-el7.parcel.sha
manifest.json
安装完成后,点继续,到检查结果的页面
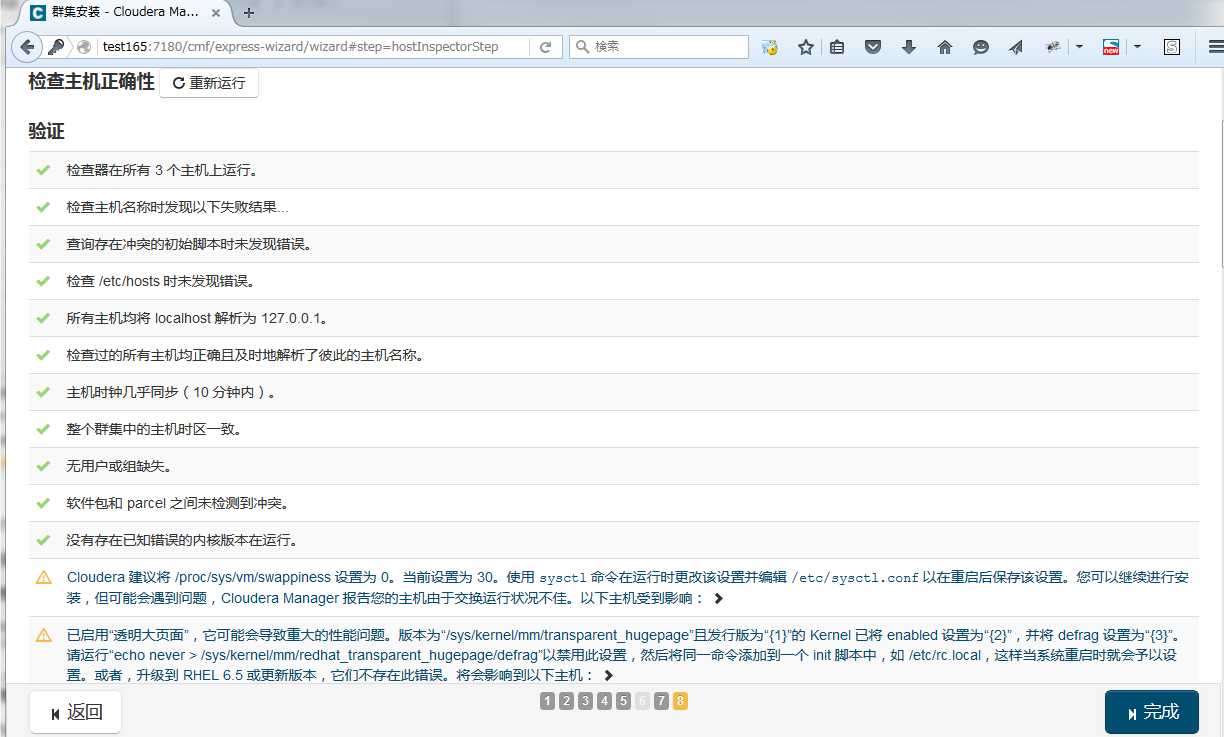
检查主机正确性时出现 “Cloudera 建议将 /proc/sys/vm/swappiness 设置为 0。当前设置为 30。” 的警告,进行如下设定
# vi /etc/sysctl.conf vm.swappiness = 0 # sysctl –p
检查主机正确性时出现 “已启用“透明大页面”,它可能会导致重大的性能问题。” 的警告,进行如下设定
echo never > /sys/kernel/mm/transparent_hugepage/enabled echo never > /sys/kernel/mm/transparent_hugepage/defrag # vi /etc/rc.local echo never > /sys/kernel/mm/transparent_hugepage/enabled echo never > /sys/kernel/mm/transparent_hugepage/defrag
检查主机正确性后,点击完成,进入集群配置
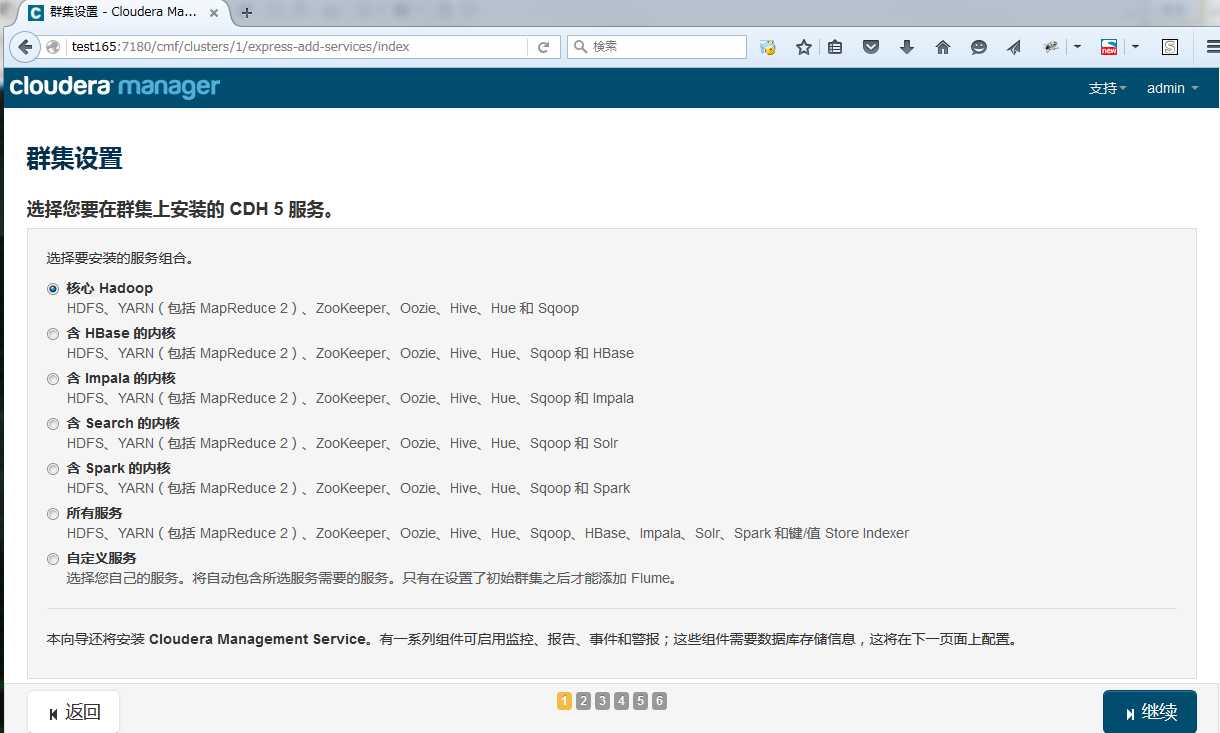
选择要安装的服务,可以选择组合或自定义
配置各节点间如何分配
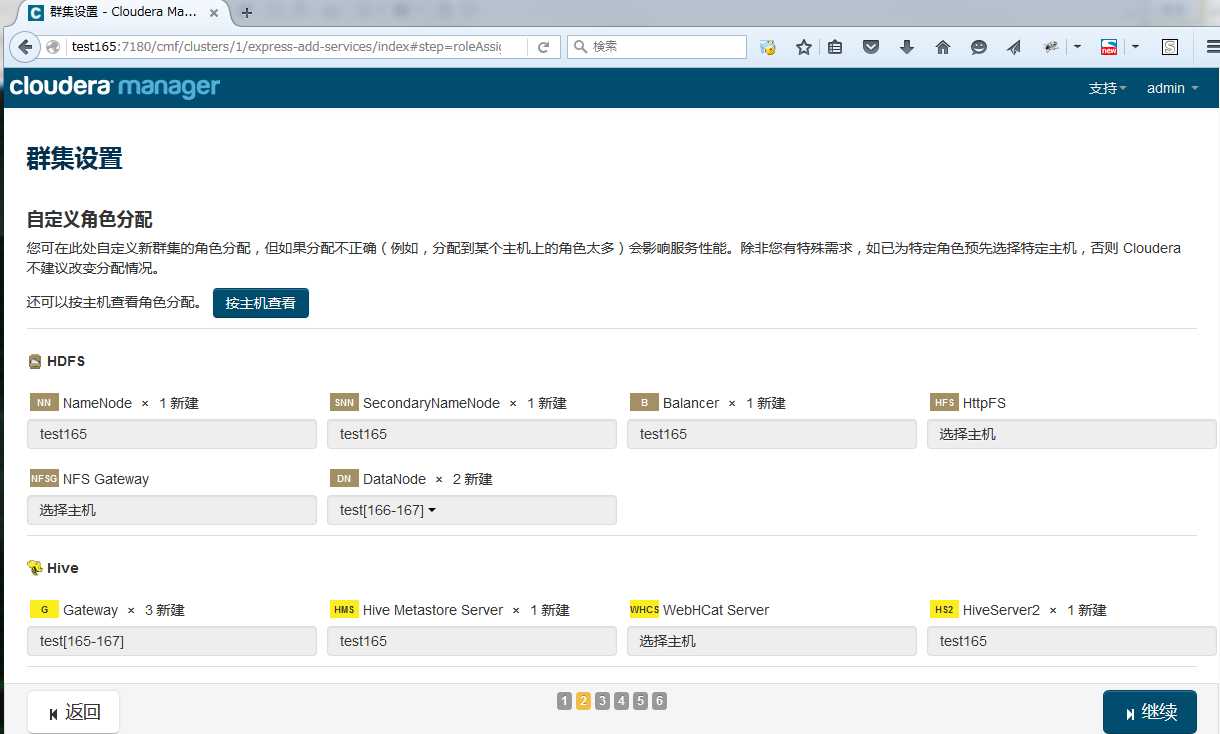
注意: HDFS的Data Node 最少3个。
测试数据库连接
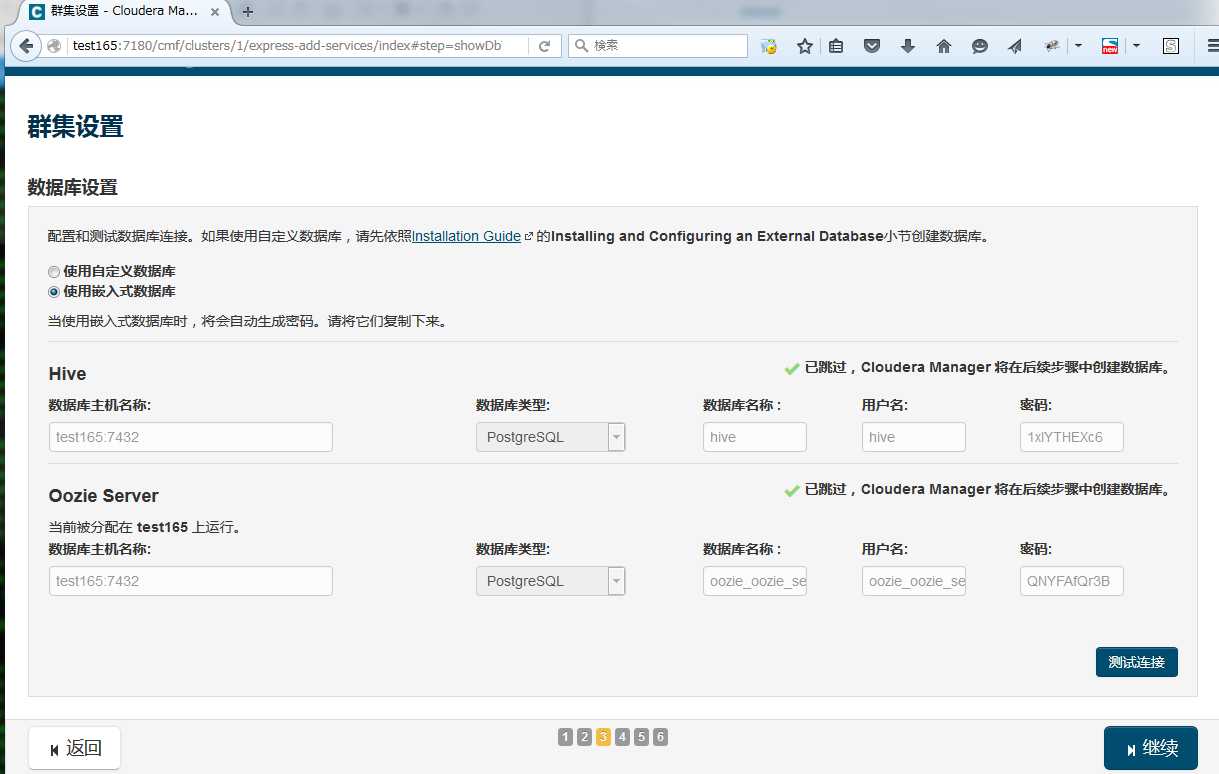
开始安装
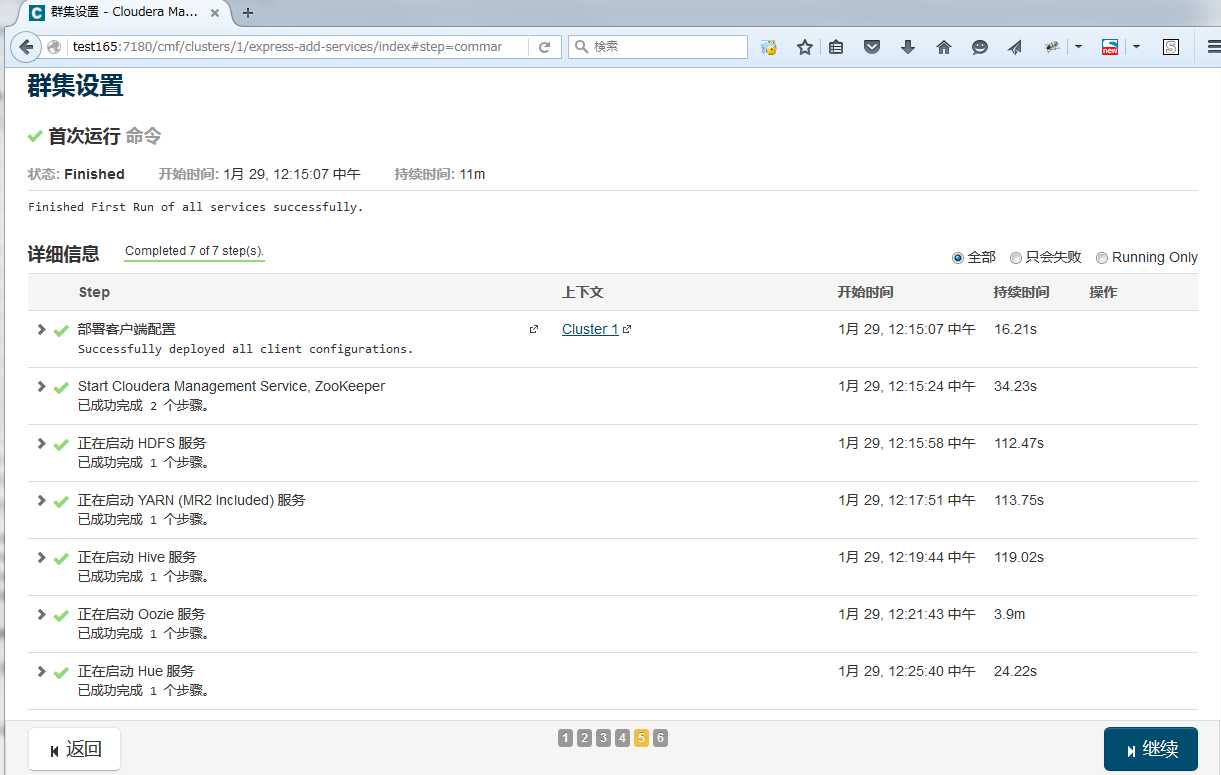
确认集群状态正常,动作正常
1. 在集群页面确认,所有服务状态正常
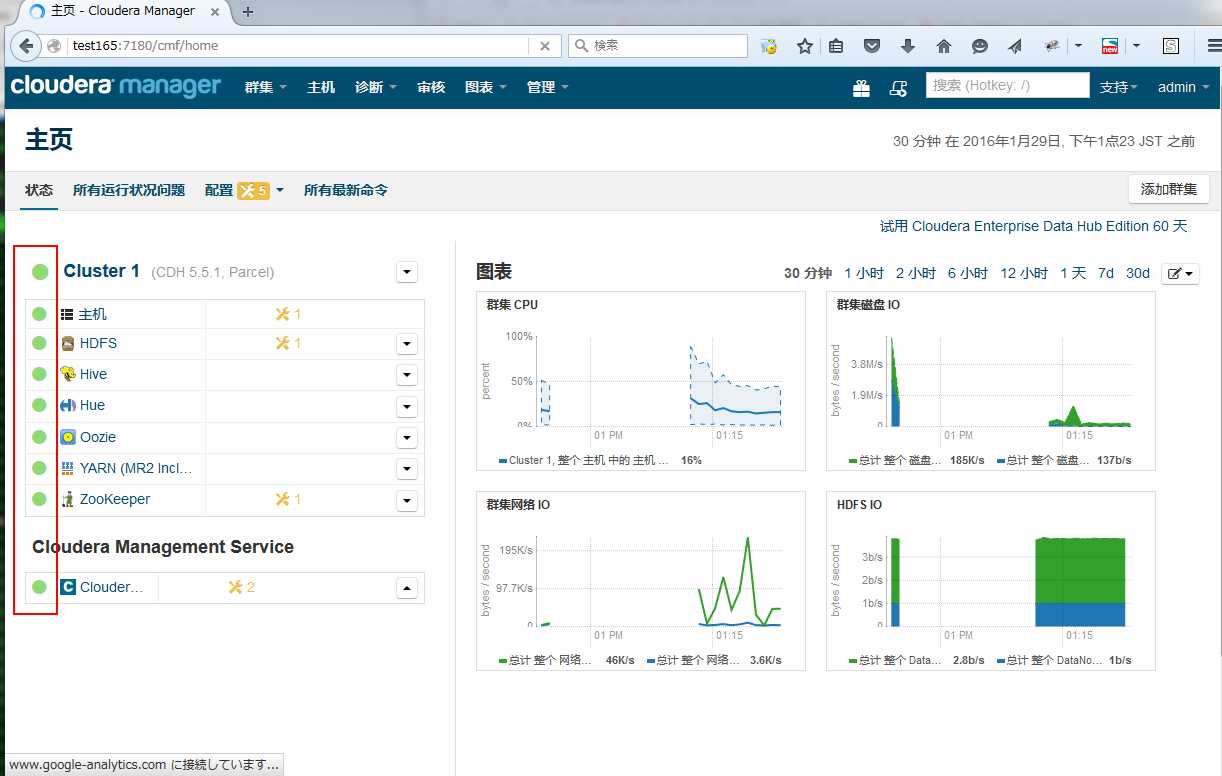
2. 在主机页面确认,各节点的Heartbeat状态正常,并且时间小于15秒

3. 运行任务进行测试
登陆到集群中任意一台主机,执行下面任务(用Hadoop计算PI值,圆周率)
后面2个数字参数的含义: 10指的是要运行10次map任务,10000指的是每个map任务,要投掷多少次,2个参数的乘积就是总的投掷次数。
# sudo -u hdfs hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar pi 10 10000
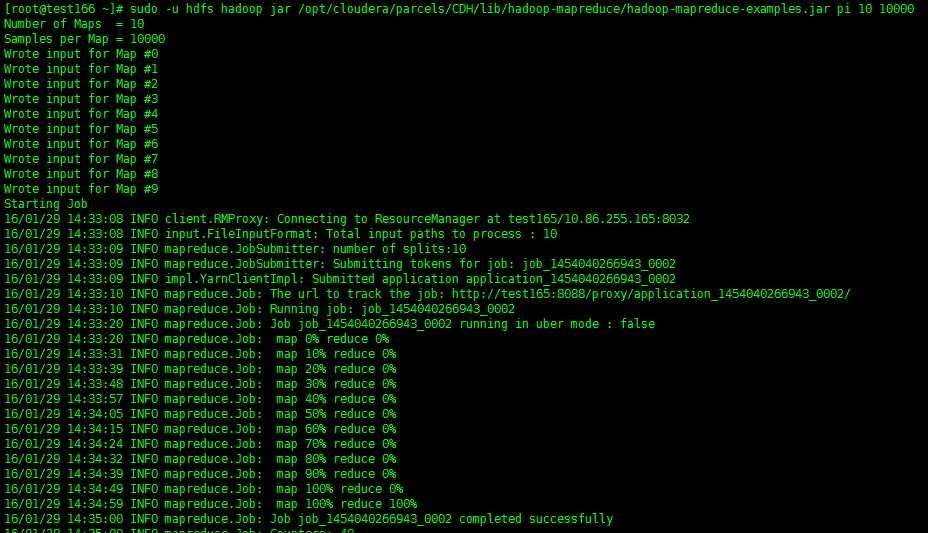
执行结果如下:

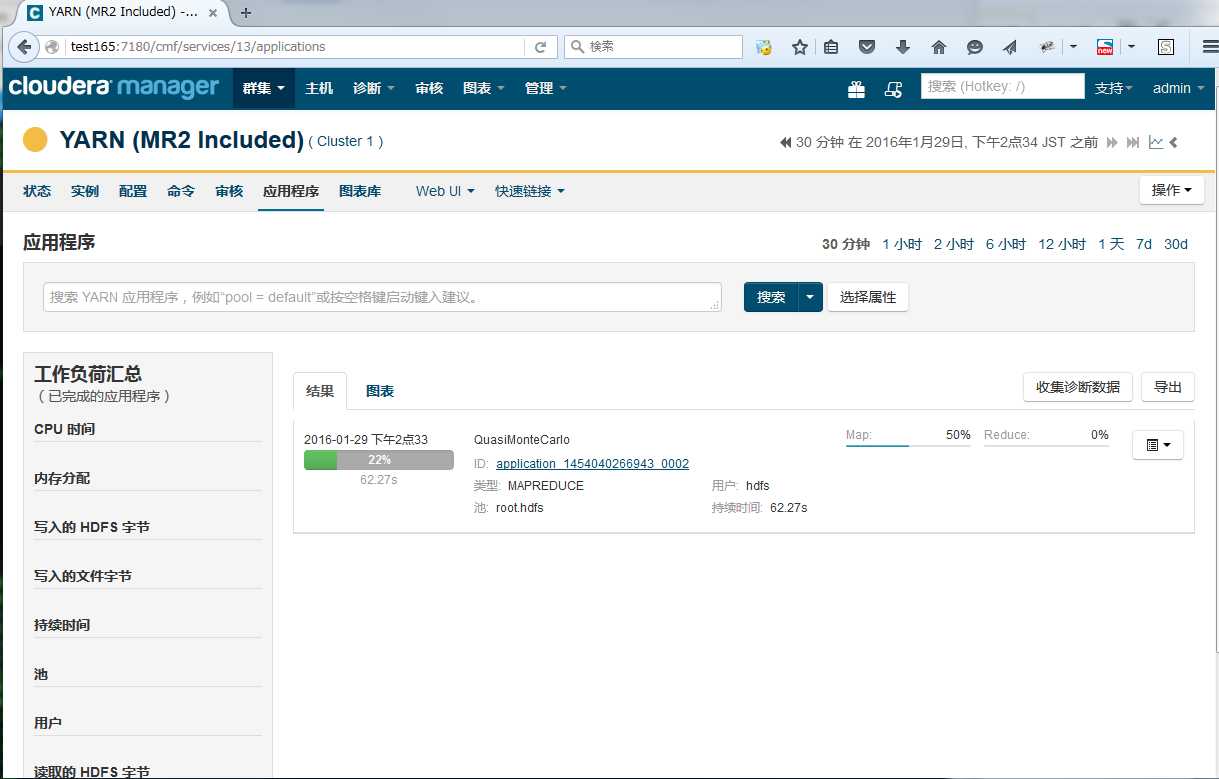
任务的执行情况可以在YARN页面上进行确认
群集 -> Cluster 1 -> YARN -> 应用程序
在Cloudrea Manager页面上,可以向集群中添加/删除主机,添加服务到集群等。
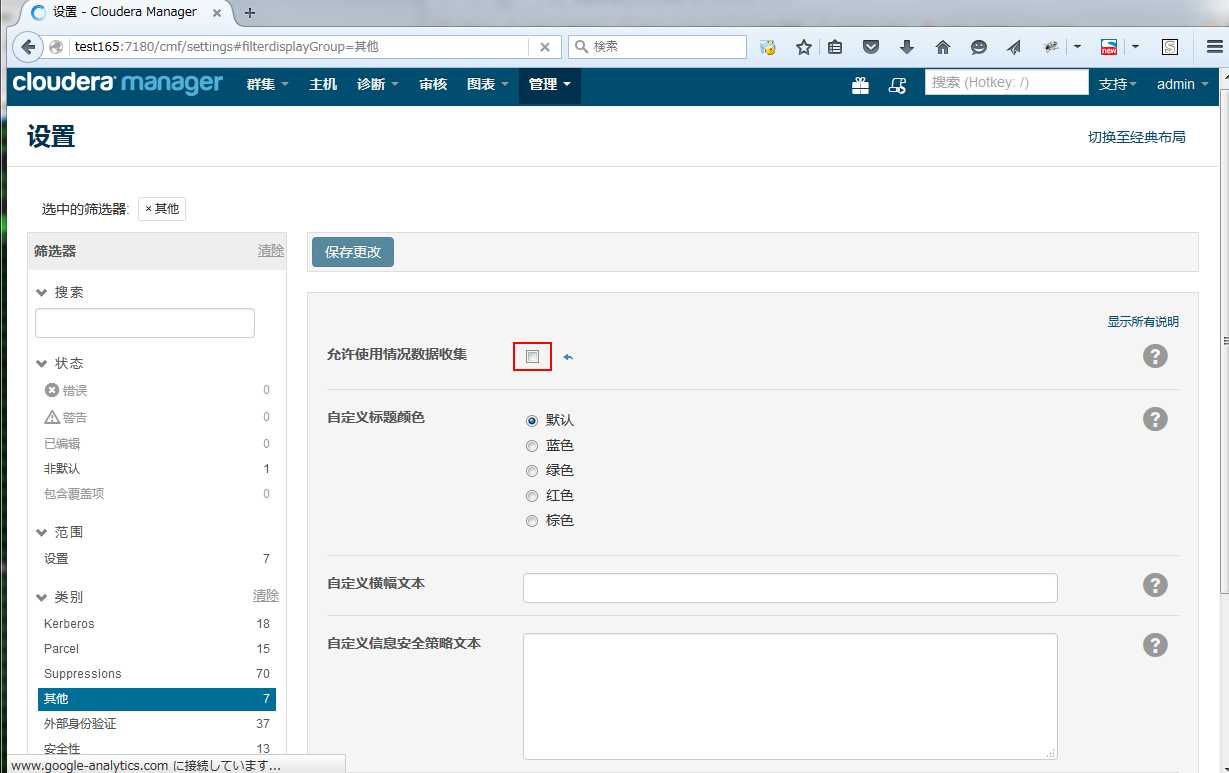
Cloudrea Manager页面开启了google-analytics,因为从国内访问很慢,可以关闭google-analytics
管理 -> 设置 -> 其他 -> 允许使用情况数据收集 不选
工欲善其事必先利其器,管理Hadoop 集群,Cloudrea 是个不错的选择。
Hadoop系列之(三):使用Cloudera部署,管理Hadoop集群
标签:
原文地址:http://www.cnblogs.com/ee900222/p/hadoop_3.html