标签:
本文前面部分转自木-叶的博文,后面有本人自己的一些总结和体会。
如果有人问你,GET和POST,有什么区别?你会如何回答?
前几天有人问我这个问题。我说GET是用于获取数据的,POST,一般用于将数据发给服务器之用。
这个答案好像并不是他想要的。于是他继续追问有没有别的区别?我说这就是个名字而已,如果服务器支持,他完全可以把GET改个名字叫GET2。他反问道,那就是单纯的名字上的区别喽?我想了想,我觉得如果说再具体的区别,只能去看RFC文档了,还要取决于服务器(指Apache,IIS)的具体实现。但我不得不承认,我的确没有仔细看过HTTP的RFC文档。于是我说,我对HTTP协议不太熟悉。这个问题也就结束了。
回来之后寻思了很久,他到底是想问我什么?我一直就觉得GET和POST没有什么除了语义之外的区别,自打我开始学习Web编程开始就是这么理解的。
可能很多人都已经猜到了,他要的答案是:
1. GET使用URL或Cookie传参。而POST将数据放在BODY中。
2. GET的URL会有长度上的限制,则POST的数据则可以非常大。
3. POST比GET安全,因为数据在地址栏上不可见。
但是很不幸,这些区别全是错误的,更不幸的是,这个答案还是Google搜索的头版头条,然而我根本没想着这些是答案,因为在我看来他们都是错的。我来一一解释一下。
GET和POST是由HTTP协议定义的。在HTTP协议中,Method和Data(URL, Body, Header)是正交的两个概念,也就是说,使用哪个Method与应用层的数据如何传输是没有相互关系的。
HTTP没有要求,如果Method是POST数据就要放在BODY中。也没有要求,如果Method是GET,数据(参数)就一定要放在URL中而不能放在BODY中。
那么,网上流传甚广的这个说法是从何而来的呢?我在HTML标准中,找到了相似的描述。这和网上流传的说法一致。但是这只是HTML标准对HTTP协议的用法的约定。怎么能当成GET和POST的区别呢?
而且,现代的Web Server都是支持GET中包含BODY这样的请求。虽然这种请求不可能从浏览器发出,但是现在的Web Server又不是只给浏览器用,已经完全地超出了HTML服务器的范畴了。
知道这个有什么用?我不想解释了,有时候就得自己痛一次才记得住。
HTTP协议明确地指出了,HTTP头和Body都没有长度的要求。而对于URL长度上的限制,有两方面的原因造成:
1. 浏览器。据说早期的浏览器会对URL长度做限制。据说IE对URL长度会限制在2048个字符内(流传很广,而且无数同事都表示认同)。但我自己试了一下,我构造了90K的URL通过IE9访问live.com,是正常的。网上的东西,哪怕是Wikipedia上的,也不能信。
2. 服务器。URL长了,对服务器处理也是一种负担。原本一个会话就没有多少数据,现在如果有人恶意地构造几个几M大小的URL,并不停地访问你的服务器。服务器的最大并发数显然会下降。另一种攻击方式是,把告诉服务器Content-Length是一个很大的数,然后只给服务器发一点儿数据,嘿嘿,服务器你就傻等着去吧。哪怕你有超时设置,这种故意的次次访问超时也能让服务器吃不了兜着走。有鉴于此,多数服务器出于安全啦、稳定啦方面的考虑,会给URL长度加限制。但是这个限制是针对所有HTTP请求的,与GET、POST没有关系。
我觉得这真是中国特色。我讲个小段子,大家应该可以体会出这个说法多么的可笑。
觉得POST数据比GET数据安全的人会说
“防君子不防小人;中国小白多,能防小白用户就行了。”
“哼,”我不以为然,“那你怎么不说,URL参数都Encode过了,或是Base64一下,小白也看不懂啊。”
那人反驳道,“Encode太简单了,聪明点儿的小白很容易就可以Decode并修改掉。”
我笑道,“五十步笑百步耳,再聪明点儿的小白还会截包并重发呢,Opera就有这功能。”
那人阴险地祭出神器——最终解释权,说,“这个不算小白。”
我日啊。
我之前一直做Windows桌面应用,对Web开发无甚了解,直到一年多前转做服务器端开发,才开始接触到HTTP。(注意,我说的是HTTP,不是HTML。服务器开放接口是基于REST理念设计的,使用的协议是HTTP,但是传输的内容不是HTML。这不是Web Server,而是一个Web Service)
所以我对于GET和POST的理解,是纯粹地来源于HTTP协议。他们只有一点根本区别,简单点儿说,一个用于获取数据,一个用于修改数据。具体的请参考RFC文档。
如果一个人一开始就做Web开发,很可能把HTML对HTTP协议的使用方式,当成HTTP协议的唯一的合理使用方式。从而犯了以偏概全的错误。
可能有人会觉得我钻牛角尖。我只是不喜欢模棱两可,不喜欢边界不清、概念不明,不喜欢“拿来主义”,也不喜欢被其它喜欢钻牛角尖的人奚落得无地自容。
“知之为知之,不知为不知,是知也。”
首先在使用上,还是严格遵守
POST
至于URL的长度限制,有转载文章中指出了,服务器为了避免恶意url请求可能会做限制,标准中并没有限制条款。
另外url中不允许出现ASCII字符类型以外的字符,body中的数据则没有要求
安全性上来说,实际上两者的数据都可以被截取,只是get直接就在url就可截取,post麻烦一些而已,正如转文所说,防君子而不防小人。
get请求能够被缓存的这个特点实际上被浏览器用的很好,比如我们平常看到的标签<img src=‘xxx‘/>就是使用的get请求,然后缓存图片,下次请求就不用在从服务器端传递图片过来了。下面两张图片对比第一次请求图片和第二次请求图片(刷一次页面)
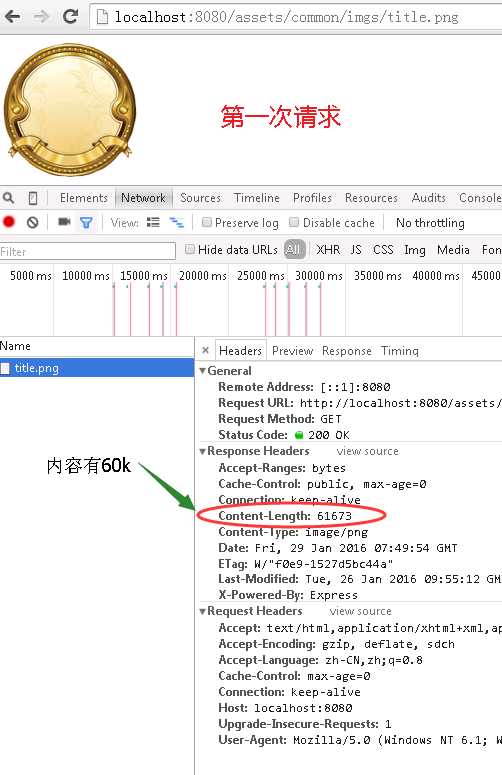
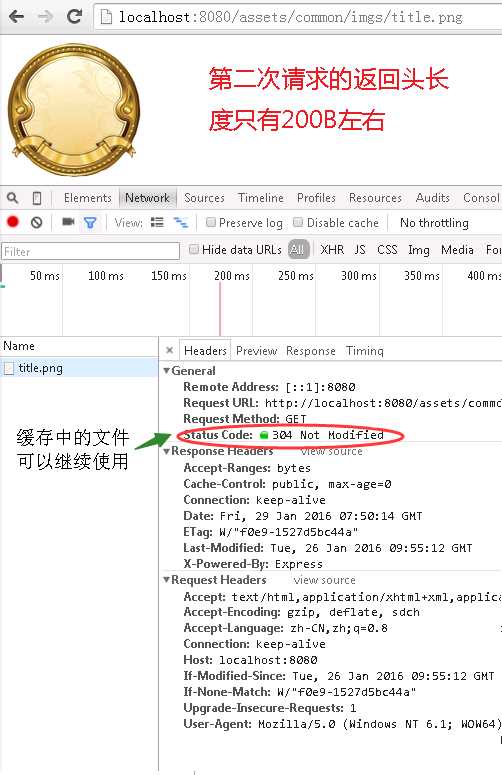
对比两次60k和200b差距何其大。所以使用的时候综合考虑get和post的优缺点来使用,让网站更加高效。
如果觉得本文不错,请点击右下方【推荐】!
标签:
原文地址:http://www.cnblogs.com/chuaWeb/p/5169173.html