标签:

来自 http://datartisan.com/article/detail/74.html
提升一个模型的表现有时很困难。如果你们曾经纠结于相似的问题,那我相信你们中很多人会同意我的看法。你会尝试所有曾学习过的策略和算法,但模型正确率并没有改善。你会觉得无助和困顿,这是90%的数据科学家开始放弃的时候。
不过,这才是考验真本领的时候!这也是普通的数据科学家跟大师级数据科学家的差距所在。你是否曾经梦想过成为大师级的数据科学家呢?
如果是的话,你需要这 8 个经过证实的方法来重构你的模型。建立预测模型的方法不止一种。这里没有金科玉律。但是,如果你遵循我的方法(见下文),(在提供的数据足以用来做预测的前提下)你的模型会拥有较高的准确率。
我从实践中学习了到这些方法。相对于理论,我一向更热衷于实践。这种学习方式也一直在激励我。本文将分享 8 个经过证实的方法,使用这些方法可以建立稳健的机器学习模型。希望我的知识可以帮助大家获得更高的职业成就。.
模型的开发周期有多个不同的阶段,从数据收集开始直到模型建立。
不过,在通过探索数据来理解(变量的)关系之前,建议进行假设生成(hypothesis generation)步骤(如果想了解更多有关假设生成的内容,推荐阅读 why-and-when-is-hypothesis-generation-important )。我认为,这是预测建模过程中最被低估的一个步骤。
花时间思考要回答的问题以及获取领域知识也很重要。这有什么帮助呢?它会帮助你随后建立更好的特征集,不被当前的数据集误导。这是改善模型正确率的一个重要环节。
在这个阶段,你应该对问题进行结构化思考,即进行一个把此问题相关的所有可能的方面纳入考虑范围的思考过程。
现在让我们挖掘得更深入一些。让我们看看这些已被证实的,用于改善模型准确率的方法。
持有更多的数据永远是个好主意。相比于去依赖假设和弱相关,更多的数据允许数据进行“自我表达”。数据越多,模型越好,正确率越高。
我明白,有时无法获得更多数据。比如,在数据科学竞赛中,训练集的数据量是无法增加的。但对于企业项目,我建议,如果可能的话,去索取更多数据。这会减少由于数据集规模有限带来的痛苦。
训练集中缺失值与异常值的意外出现,往往会导致模型正确率低或有偏差。这会导致错误的预测。这是由于我们没能正确分析目标行为以及与其他变量的关系。所以处理好缺失值和异常值很重要。
仔细看下面一幅截图。在存在缺失值的情况下,男性和女性玩板球的概率相同。但如果看第二张表(缺失值根据称呼“Miss”被填补以后),相对于男性,女性玩板球的概率更高。
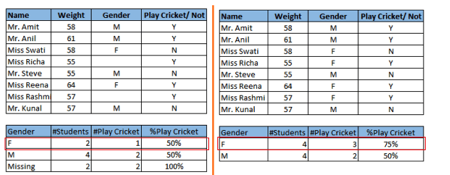
左侧:缺失值处理前;右侧:缺失值处理后
从上面的例子中,我们可以看出缺失值对于模型准确率的不利影响。所幸,我们有各种方法可以应对缺失值和异常值:
这一步骤有助于从现有数据中提取更多信息。新信息作为新特征被提取出来。这些特征可能会更好地解释训练集中的差异变化。因此能改善模型的准确率。
假设生成对特征工程影响很大。好的假设能带来更好的特征集。这也是我一直建议在假设生成上花时间的原因。特征工程能被分为两个步骤:
特征选择是寻找众多属性的哪个子集合,能够最好的解释目标变量与各个自变量的关系的过程。
你可以根据多种标准选取有用的特征,例如:
使用正确的机器学习算法是获得更高准确率的理想方法。但是说起来容易做起来难。
这种直觉来自于经验和不断尝试。有些算法比其他算法更适合特定类型数据。因此,我们应该使用所有有关的模型,并检测其表现。
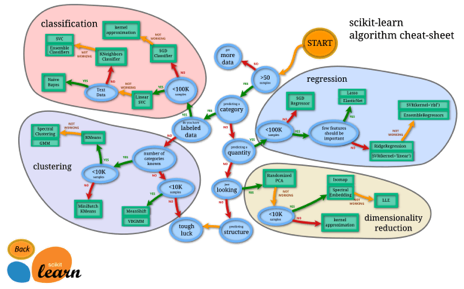
来源:Scikit-Learn 算法选择图
我们都知道机器学习算法是由参数驱动的。这些参数对学习的结果有明显影响。参数调整的目的是为每个参数寻找最优值,以改善模型正确率。要调整这些参数,你必须对它们的意义和各自的影响有所了解。你可以在一些表现良好的模型上重复这个过程。
例如,在随机森林中,我们有 max_features, number_trees, random_state, oob_score 以及其他参数。优化这些参数值会带来更好更准确的模型。
想要详细了解调整参数带来的影响,可以查阅《Tuning the parameters of your Random Forest model》。下面是随机森林算法在scikit learn中的全部参数清单:
RandomForestClassifier(n_estimators=10, criterion=‘gini‘, max_depth=None,min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=‘auto‘, max_leaf_nodes=None,bootstrap=True, oob_score=False, n_jobs=1, random_state=None, verbose=0, warm_start=False,class_weight=None)
在数据科学竞赛获胜方案中最常见的方法。这个技术就是把多个弱模型的结果组合在一起,获得更好的结果。它能通过许多方式实现,如:
想了解更多这方面内容,可以查阅《Introduction to ensemble learning》。
使用集成方法改进模型正确率永远是个好主意。主要有两个原因:
1)集成方法通常比传统方法更复杂;
2)传统方法提供好的基础,在此基础上可以建立集成方法。
到目前为止,我们了解了改善模型准确率的方法。但是,高准确率的模型不一定(在未知数据上)有更好的表现。有时,模型准确率的改善是由于过度拟合。
如果想解决这个问题,我们必须使用交叉验证技术(cross validation)。交叉验证是数据建模领域最重要的概念之一。它是指,保留一部分数据样本不用来训练模型,而是在完成模型前用来验证。
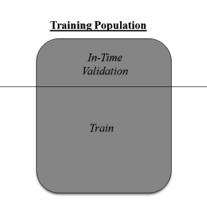
这种方法有助于得出更有概括性的关系。想了解更多有关交叉检验的内容,建议查阅《Improve model performance using cross validation》。
预测建模的过程令人疲惫。但是,如果你能灵活思考,就可以轻易胜过其他人。简单地说,多考虑上面这8个步骤。获得数据集以后,遵循这些被验证过的方法,你就一定会得到稳健的机器学习模型。不过,只有当你熟练掌握了这些步骤,它们才会真正有帮助。比如,想要建立一个集成模型,你必须对多种机器学习算法有所了解。
本文分享了 8 个经过证实的方法。这些方法用来改善模型的预测表现。它们广为人知,但不一定要按照文中的顺序逐个使用。
原作者:Sunil Ray
翻译:王鹏宇
原文链接:
8 Proven Ways for improving the “Accuracy” of a Machine Learning Model
标签:
原文地址:http://www.cnblogs.com/hhh5460/p/5186232.html