标签:
ZooKeeper内部有一个in-memory DB,表示为一个树形结构。每个树节点称为Znode(代码在DataTree.java和DataNode.java中)。
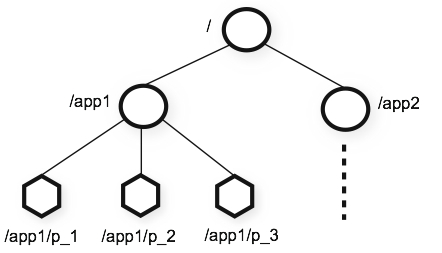
客户端可以连接到zookeeper集群中的任意一台。
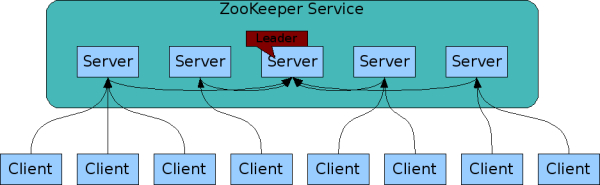 对于读请求,直接返回本地znode数据。写操作则转换为一个事务,并转发到集群的Leader处理。Zookeeper提交事务保证写操作(更新)对于zookeeper集群所有机器都是一致的。
对于读请求,直接返回本地znode数据。写操作则转换为一个事务,并转发到集群的Leader处理。Zookeeper提交事务保证写操作(更新)对于zookeeper集群所有机器都是一致的。
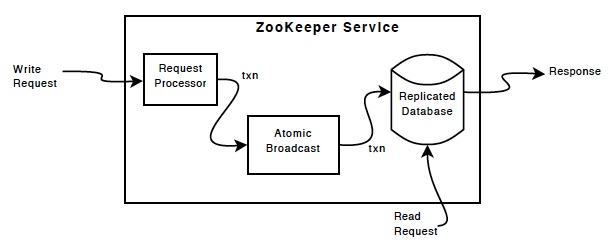
Zookeeper使用了一种称为Zab(Zookeeper Atomic Broadcast)的协议作为其一致性复制的核心,据其作者说这是一种新发算法,其特点是充分考虑了Yahoo的具体情况:高吞吐量、低延迟、健壮、简单,但不过分要求其扩展性。
(1)Zookeeper的实现是由Client、Server构成
① Server端提供了一个一致性复制、存储服务;
② Client端会提供一些具体的语义,比如分布式锁、选举算法、分布式互斥等;
(2)从存储内容来说,Server端更多的是存储一些数据的状态,而非数据内容本身,因此Zookeeper可以作为一个小文件系统使用。数据状态的存储量相对不大,完全可以全部加载到内存中,从而极大地消除了通信延迟。
(3)Server可以Crash后重启,考虑到容错性,Server必须“记住”之前的数据状态,因此数据需要持久化,但吞吐量很高时,磁盘的IO便成为系统瓶颈,其解决办法是使用缓存,把随机写变为连续写。☆☆☆
(4)安全属性
考虑到Zookeeper主要操作数据的状态,为了保证状态的一致性,Zookeeper提出了两个安全属性(Safety Property)
① 全序(Total order):如果消息a在消息b之前发送,则所有Server应该看到相同的结果
② 因果顺序(Causal order):如果消息a在消息b之前发生(a导致了b),并被一起发送,则a始终在b之前被执行。☆☆
(5)安全保证
为了保证上述两个安全属性,Zookeeper使用了TCP协议和Leader。
① 通过使用TCP协议保证了消息的全序特性(先发先到)
② 通过Leader解决了因果顺序问题:先到Leader的先执行。
因为有了Leader,Zookeeper的架构就变为:Master-Slave模式,但在该模式中Master(Leader)会Crash,因此,Zookeeper引入了Leader选举算法,以保证系统的健壮性。
(6)Zookeeper整个工作分两个阶段:
① Atomic Broadcast
② Leader选举
(7)Zab特性
ZooKeeper中提交事务的协议并不是Paxos,而是由二阶段提交协议改编的ZAB协议。Zab可以满足以下特性:
①可靠提交 Reliable delivery:如果消息m被一个server递交了,那么m也将最终被所有server递交。
②全局有序 Total order:如果server在递交b之前递交了a,那么所有递交了a、b的server也会在递交b之前递交a。
③因果有序 Casual order:对于两个递交了的消息a、b,如果a因果关系优先于(causally precedes)b,那么a将在b之前递交。
第三条的因果优先指的是同一个发送者发送的两个消息a先于b发送,或者上一个leader发送的消息a先于当前leader发送的消息。
Zab协议中Server有两个模式:broadcast模式、recovery模式
(1)恢复模式
Leader在开始broadcast之前,必须有一个同步更新过的follower的quorum。
Server在Leader服务期间恢复在线时,将进入recovery模式,与Leader进行同步。
(2)广播模式
Broadcast模式使用二阶段提交,但是简化了协议,不需要abort。follower要么ack,要么抛弃Leader,因为zookeeper保证了每次只有一个Leader。另外也不需要等待所有Server的ACK,只需要一个quorum应答就可以了。

① Follower收到proposal后,写到磁盘(尽可能批处理),返回ACK。
② Leader收到大多数ACK后,广播COMMIT消息,自己也deliver该消息。
③ Follower收到COMMIT之后,deliver该消息。
(4)面临问题
然而,这个简化的二阶段提交不能处理Leader失效的情况,所以增加了recovery模式。切换Leader时,需要解决下面两个问题。 ZooKeeper的主要功能是维护一个高可用且一致的数据库,数据库内容复制在多个节点上,总共2f+1个节点中只要不超过f个失效,系统就可用。实现这一点的核心是ZAB,一种Atomic Broadcast协议。所谓Atomic Broadcast协议,形象的说就是能够保证发给各复本的消息顺序相同。
由于Paxos的名气太大,所以我看ZAB的时候首先就想为什么要搞个 ZAB,ZAB相比Paxos有什么优点?这里首要一点是Paxos的一致性不能达到ZooKeeper的要求。举个例子。
假设一开始Paxos系统中的 leader是P1,他发起了两个事务<t1, v1>(表示序号为t1的事务要写的值是v1)和<t2, v2>的过程中挂了。新来个leader是P2,他发起了事务<t1, v1‘>。而后又来个新leader是P3,他汇总了一下,得出最终的执行序列<t1, v1‘>和<t2, v2>,即P2的t1在前,P1的t2在后。
注意:在这我们可以看出,对于序号为t1的事务,Leader2将Leader1的覆盖了
这样的序列为什么不能满足ZooKeeper的需求呢?ZooKeeper是一个树形结构,很多操作都要先检查才能确定能不能执行,比如P1的事务t1可能是创建节点“/a”,t2可能是创建节点“/a/aa”,只有先创建了父节点“/a”,才能创建子节点“/a/aa”。而P2所发起的事务t1可能变成了创建“/b”。这样P3汇总后的序列是先创建“/b”再创建“/a/aa”,由于“/a”还 没建,创建“a/aa”就搞不定了。
为了保证这一点,ZAB要保证同一个leader的发起的事务要按顺序被apply,同时还要保证只有先前的leader的所有事务都被apply之后,新选的leader才能在发起事务。
ZAB 的核心思想,形象的说就是保证任意时刻只有一个节点是leader,所有更新事务由leader发起去更新所有复本(称为follower),更新时用的就是两阶段提交协议,只要多数节点prepare成功,就通知他们commit。各follower要按当初leader让他们prepare的顺序来 apply事务。因为ZAB处理的事务永远不会回滚,ZAB的2PC做了点优化,多个事务只要通知zxid最大的那个commit,之前的各 follower会统统commit。☆☆☆
如果没有节点失效,那ZAB上面这样搞下就完了,麻烦在于leader失效或leader得不到多数节点的支持时怎么处理。这里有几个关键点:
① leader所follower之间通过心跳来检测异常;
② 检测到异常之后的节点若试图成为新的leader,首先要获得大多数节点的支持,然后从状态最新的节点同步事务,完成后才可正式成为leader发起事务;
③区分新老leader的关键是一个会一直增长的epoch;当然细节很多了,这里就不说了因为我也没完全搞懂,要了解详情请看《Zab: High-performance broadcast for primary-backup systems.》这篇论文。
除了能保证顺序外,ZAB的性能也能不错,基于千兆网络的测试,一般的5节点部署的TPS达到25000左右,而响应时间只有约6ms。
Because multiple leaders can propose a value for a given instance two problems arise. First, proposals can conflict. Paxos uses ballots to detect and resolve conflicting proposals. Second, it is not enough to know that a given instance number has been committed, processes must also be able to fi gure out which value has been committed.
标签:
原文地址:http://www.cnblogs.com/lee-mj/p/5191921.html