标签:blog http strong 数据 art re c ar
似然函数:似然函数在形式上就概率密度函数。 似然函数用来估计某个参数。
最大似然函数:就是求似然函数的最大值。 最大似然函数用于估计最好的参数。
最小二乘法:它通过最小化误差的平方和寻找数据的最佳函数匹配。就是求 y=a1+a2x的系数。通过最小化误差的平方,然后求系数的偏导数,令导数为0,求解。
梯度下降法,基于这样的观察:如果实值函数  在点
在点 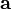 处可微且有定义,那么函数 在 点沿着梯度相反的方向
处可微且有定义,那么函数 在 点沿着梯度相反的方向  下降最快。就是求最低点。
下降最快。就是求最低点。
局部加权回归:它的中心思想是在对参数进行求解的过程中,每个样本对当前参数值的影响是有不一样的权重的,自己上网搜吧。
标签:blog http strong 数据 art re c ar
原文地址:http://www.cnblogs.com/GuoJiaSheng/p/3866487.html