标签:
页面访问量统计,可能在上学的时候就讲过如何简单实现,例如在servletContext中保存一个页页面访问次数,然后每访问一次加1;或者每访问一次就把操作记录保存到数据库,这样的处理方式,做做实验就算了,在实际应用中这样应用对系统性能影响特别大。
第一种方式,因为页面访问次数属于一个公共变量,在对公共变量进行修改的时候,往往需要加上同步锁;同步锁会导致访问速度明显变慢;第二种方式也一样,而且频繁访问数据库也不是一种合理的方式。
前不久,我一个朋友要我帮他们写一个简单的页面统计代码。1、需求是保存页面访问IP、时间、以及其他一些可用的信息,以后需要保存的访问信息可扩展 2、不能影响当前的访问速度 3、能支持一定量的并发访问
接到朋友给的这个需求,我想到了一下几点:1、如何筛选我们需要统计的页面;2、需要将访问和统计分离,不在访问的线程中来保存访问信息,另外起一个线程将访问信息保存到数据库;3、可以使用一个公共的队列来保存这个访问信息;4、可以批量的保存一定量的访问信息
解决方案:
1、针对第一个问题,我给出了两个方法。1、使用一个集合保存所有的需要统计的页面,然后再在Filter里面判断当前请求是否在在统计之列;2、在JSP页面中引入一段公共代码,在代码中使用类似这种CounterUtils.addCounter(request);这种方法有一个好处,维护需要统计的页面比较方便,而且感觉上更加高效,不需要Filter拦截。但是朋友坚决用第一种方式,也是没有办法。
2、每访问一次,我们将需要保存的信息保存成一个对象,然后放入到队列当中,然后另起一个线程定期进行保存。
于是我就写了一个简单的demo给朋友,没过多久,就被退货了。经过测试并发还没到200就突然不保存数据库了,访问也变得特慢,最后竟然堆内存溢出了。
没有办法只能再在本机用loadRunner进行测试,同时通过jconsole java自带工具来检测内存变化情况。测试情况与朋友说的一样,刚开始能够正常运行,当并发达到一定量,就开始出现保存缓慢,最后不知道怎么整的保存线程不再运行,就这样队列越来越大,自然堆内存大到溢出了。
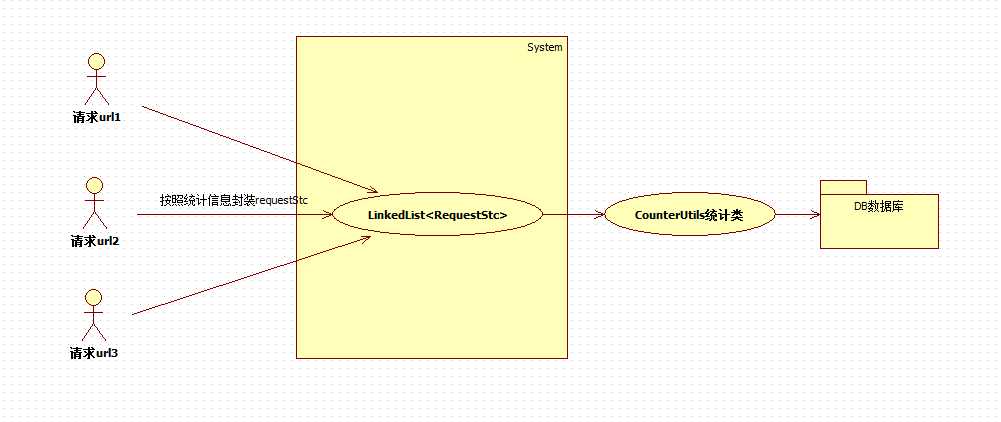
从上面的情况也可以想到,一个队列有可能无法支持这么大的并发访问,于是就想使用多个队列来进行保存,使用类似分表分库的方法,将不同请求分配到不同的队列中去,于是就变成了下面这种方式:
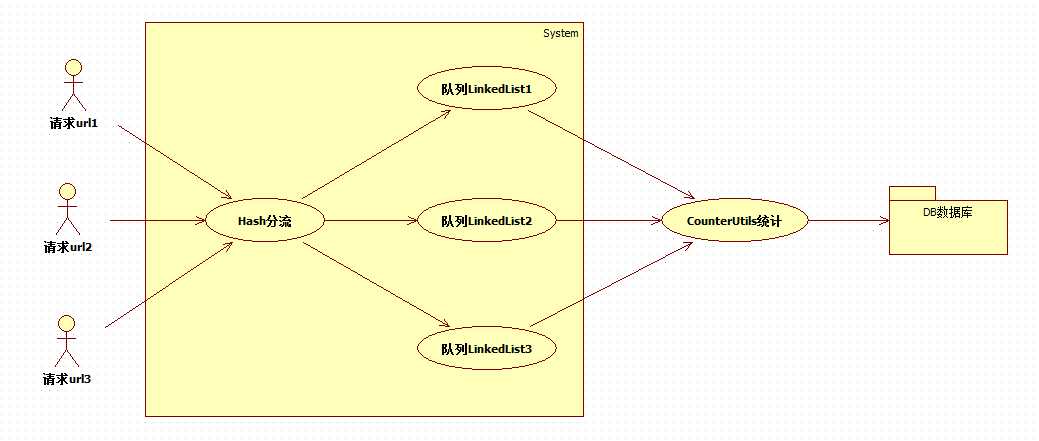
部分代码如下:
1、初始化生成linkedList集合列表

/**
* 根据urls生成队列数组
* @return
*/
private static LinkedList<RequestStc>[] initUris() {
Digester digester = new Digester();
String path = null;
try {
path = CounterUtils.class.getClassLoader().getResource("urls.xml").toURI().getPath();
} catch (URISyntaxException e1) {
e1.printStackTrace();
}
UriRuleSet ruleSet = new UriRuleSet();
ruleSet.addRuleInstances(digester);
try {
// uri集合
uris = digester.parse(new File(path));
// hashCode基数
BaseHash = uris!=null?uris.size()/3:1;
LinkedList<RequestStc>[] listArr = new LinkedList[BaseHash];
for(int i=0; i<listArr.length; i++)
listArr[i] = new LinkedList<RequestStc>();
return listArr;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
2、将请求封装成统计所需对象
/**
* 添加一次请求统计
* @param request
*/
public static void addCounter(HttpServletRequest request) {
// 封装用户统计的request,并且用hash算法分布到不同的队列当中
RequestStc stc = new RequestStc();
stc.setIp(request.getRemoteAddr());
stc.setUri(request.getRequestURI());
stc.setNow(Calendar.getInstance().getTime());
buffers[request.hashCode()%BaseHash].push(stc);
}
3、轮询LinkedList队列集合
/**
* 执行统计
*/
private void processCount() {
try {
// 轮询队列
while(true) {
Thread.sleep(Sleep_MS);
if(buffers==null) {
break;
}
Thread th = null;
for(int i=0,len = buffers.length; i<len; i++) {
LinkedList<RequestStc> stcList = null;
if(buffers[i].size()>=Execute_Base) {
// 复制buffers数组元素,然后清空,启动一个线程对队列进行保存
synchronized (buffers[i]) {
stcList = (LinkedList<RequestStc>) buffers[i].clone();
buffers[i].clear();
}
th = new Thread(new ExecuteThread(stcList));
th.start();
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
4、ExecuteThread线程用于批量保存访问日志
// 批量保存数据库
这个分两种方式1、保存详细的访问记录,例如,某某时候某个IP对某个页面进行了访问 2、只保存某天每个页面访问的总数
对于第一种方式,使用批量保存即可。对于第二种方式可以使用一个hashTable来维护所有页面某个时间段内的对应页面的访问增量,具体维护方式可以如下:
将reqestStc信息维护进HashTable当中,其中维护过程省略;再写一个定时器,定时将HashTable中的增量数据flush到数据库中;
/**
* 将数据刷出,保存到数据库
*/
public void flush() {
Hashtable<String, RequestParam> saveTable = null;
// 这个地方为什么不用同步锁,因为HashTable本身就是线程安全的,clone方法上加了同步锁
saveTable = (Hashtable) counterTables.clone();
counterTables.clear();
if(saveTable.isEmpty())
return;
for(Entry<String, RequestParam> ent:saveTable.entrySet()) {
String url = ent.getKey();
RequestParam param = ent.getValue();
System.out.println("url:" + url);
System.out.println("pv:" + param.getPv());
requestCount += param.getPv();
}
System.out.println("ip:" + ips.size());
System.out.println("访问总数为:" + requestCount);
}
5、如何拦截需要统计的访问请求
方法一:通过判断uri是否在需要统计之列
方法二:在需要统计的jsp中添加JAVA代码例如:CounterUtils.addCounter(request);
方法三:JS异步访问,类似百度统计的这种方式,这种方式有个好处,就是不影响页面加载速度
经过修改,在loadRunner和tomcat的测试下,基本上能够达到tomcat最大的并发以上用户,并且占用少量资源。
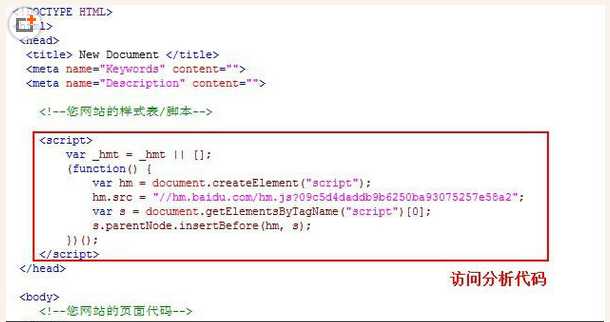
还有一种方式就是百度统计那种方式,在js端使用异步统计代码,这样做的好处是不影响页面的加载速度,代码如下图,具体实现没有去深究:
标签:
原文地址:http://www.cnblogs.com/shouce/p/5206039.html