标签:
《深入理解Spark:核心思想与源码分析》一书前言的内容请看链接《深入理解SPARK:核心思想与源码分析》一书正式出版上市
《深入理解Spark:核心思想与源码分析》一书第一章的内容请看链接《第1章 环境准备》
《深入理解Spark:核心思想与源码分析》一书第二章的内容请看链接《第2章 SPARK设计理念与基本架构》
由于本书的第3章内容较多,所以打算分别开辟三篇随笔分别展现。
《深入理解Spark:核心思想与源码分析》一书第三章第一部分的内容请看链接《深入理解Spark:核心思想与源码分析》——SparkContext的初始化(上)》
本文展现第3章第二部分的内容:
任何系统都需要提供监控功能,用浏览器能访问具有样式及布局,并提供丰富监控数据的页面无疑是一种简单、高效的方式。SparkUI就是这样的服务,它的构成如图3-1所示。
在大型分布式系统中,采用事件监听机制是最常见的。为什么要使用事件监听机制?假如SparkUI采用Scala的函数调用方式,那么随着整个集群规模的增加,对函数的调用会越来越多,最终会受到Driver所在JVM的线程数量限制而影响监控数据的更新,甚至出现监控数据无法及时显示给用户的情况。由于函数调用多数情况下是同步调用,这就导致线程被阻塞,在分布式环境中,还可能因为网络问题,导致线程被长时间占用。将函数调用更换为发送事件,事件的处理是异步的,当前线程可以继续执行后续逻辑,线程池中的线程还可以被重用,这样整个系统的并发度会大大增加。发送的事件会存入缓存,由定时调度器取出后,分配给监听此事件的监听器对监控数据进行更新。
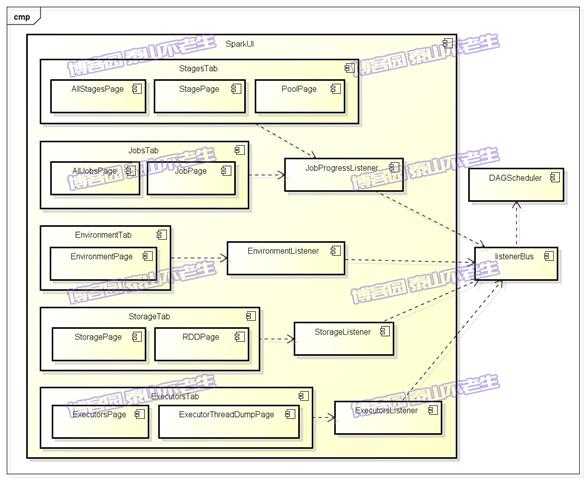
图3-1 SparkUI架构
我们先将图3-1中的各个组件作简单介绍:DAGScheduler是主要的产生各类SparkListenerEvent的源头,它将各种SparkListenerEvent发送到listenerBus的事件队列中,listenerBus通过定时器将SparkListenerEvent事件匹配到具体的SparkListener,改变SparkListener中的统计监控数据,最终由SparkUI的界面展示。从图3-1中还可以看到Spark里定义了很多监听器SparkListener的实现,包括JobProgressListener、EnviromentListener、StorageListener、ExecutorsListener几种,它们的类继承体系如图3-2所示。
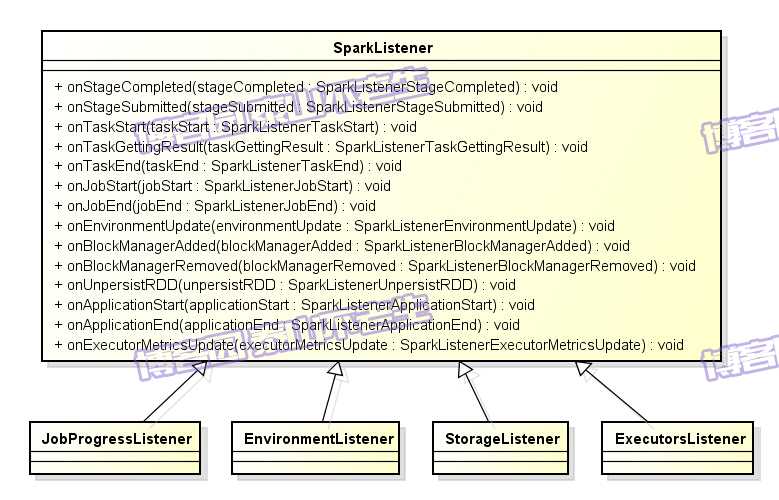
图3-2 SparkListener继承体系
listenerBus的类型是LiveListenerBus,LiveListenerBus实现了监听器模型,通过监听事件触发对各种监听器监听状态信息的修改,达到UI界面的数据刷新效果。LiveListenerBus由以下部分组成:
q 事件阻塞队列:类型为LinkedBlockingQueue[SparkListenerEvent],固定大小是10000;
q 监听器数组:类型为ArrayBuffer[SparkListener],存放各类监听器SparkListener。SparkListener是;
q 事件匹配监听器的线程:此Thread不断拉取LinkedBlockingQueue中的事情,遍历监听器,调用监听器的方法。任何事件都会在LinkedBlockingQueue中存在一段时间,然后Thread处理了此事件后,会将其清除。因此使用listener bus这个名字再合适不过了,到站就下车。listenerBus的实现,见代码清单3-15。
代码清单3-15 LiveListenerBus的事件处理实现
private val EVENT_QUEUE_CAPACITY = 10000 private val eventQueue = new LinkedBlockingQueue[SparkListenerEvent](EVENT_QUEUE_CAPACITY) private var queueFullErrorMessageLogged = false private var started = false // A counter that represents the number of events produced and consumed in the queue private val eventLock = new Semaphore(0) private val listenerThread = new Thread("SparkListenerBus") { setDaemon(true) override def run(): Unit = Utils.logUncaughtExceptions { while (true) { eventLock.acquire() // Atomically remove and process this event LiveListenerBus.this.synchronized { val event = eventQueue.poll if (event == SparkListenerShutdown) { // Get out of the while loop and shutdown the daemon thread return } Option(event).foreach(postToAll) } } } } def start() { if (started) { throw new IllegalStateException("Listener bus already started!") } listenerThread.start() started = true } def post(event: SparkListenerEvent) { val eventAdded = eventQueue.offer(event) if (eventAdded) { eventLock.release() } else { logQueueFullErrorMessage() } } def listenerThreadIsAlive: Boolean = synchronized { listenerThread.isAlive } def queueIsEmpty: Boolean = synchronized { eventQueue.isEmpty } def stop() { if (!started) { throw new IllegalStateException("Attempted to stop a listener bus that has not yet started!") } post(SparkListenerShutdown) listenerThread.join() }
LiveListenerBus中调用的postToAll方法实际定义在父类SparkListenerBus中,如代码清单3-16所示。
代码清单3-16 SparkListenerBus中的监听器调用
protected val sparkListeners = new ArrayBuffer[SparkListener] with mutable.SynchronizedBuffer[SparkListener] def addListener(listener: SparkListener) { sparkListeners += listener } def postToAll(event: SparkListenerEvent) { event match { case stageSubmitted: SparkListenerStageSubmitted => foreachListener(_.onStageSubmitted(stageSubmitted)) case stageCompleted: SparkListenerStageCompleted => foreachListener(_.onStageCompleted(stageCompleted)) case jobStart: SparkListenerJobStart => foreachListener(_.onJobStart(jobStart)) case jobEnd: SparkListenerJobEnd => foreachListener(_.onJobEnd(jobEnd)) case taskStart: SparkListenerTaskStart => foreachListener(_.onTaskStart(taskStart)) case taskGettingResult: SparkListenerTaskGettingResult => foreachListener(_.onTaskGettingResult(taskGettingResult)) case taskEnd: SparkListenerTaskEnd => foreachListener(_.onTaskEnd(taskEnd)) case environmentUpdate: SparkListenerEnvironmentUpdate => foreachListener(_.onEnvironmentUpdate(environmentUpdate)) case blockManagerAdded: SparkListenerBlockManagerAdded => foreachListener(_.onBlockManagerAdded(blockManagerAdded)) case blockManagerRemoved: SparkListenerBlockManagerRemoved => foreachListener(_.onBlockManagerRemoved(blockManagerRemoved)) case unpersistRDD: SparkListenerUnpersistRDD => foreachListener(_.onUnpersistRDD(unpersistRDD)) case applicationStart: SparkListenerApplicationStart => foreachListener(_.onApplicationStart(applicationStart)) case applicationEnd: SparkListenerApplicationEnd => foreachListener(_.onApplicationEnd(applicationEnd)) case metricsUpdate: SparkListenerExecutorMetricsUpdate => foreachListener(_.onExecutorMetricsUpdate(metricsUpdate)) case SparkListenerShutdown => } } private def foreachListener(f: SparkListener => Unit): Unit = { sparkListeners.foreach { listener => try { f(listener) } catch { case e: Exception => logError(s"Listener ${Utils.getFormattedClassName(listener)} threw an exception", e) } } }
我们以JobProgressListener为例来讲解SparkListener。JobProgressListener是SparkContext中一个重要的组成部分,通过监听listenerBus中的事件更新任务进度。SparkStatusTracker和SparkUI实际上也是通过JobProgressListener来实现任务状态跟踪的。创建JobProgressListener的代码如下。
private[spark] val jobProgressListener = new JobProgressListener(conf) listenerBus.addListener(jobProgressListener) val statusTracker = new SparkStatusTracker(this)
JobProgressListener的作用是通过HashMap、ListBuffer等数据结构存储JobId及对应的JobUIData信息,并按照激活、完成、失败等job状态统计。对于StageId、StageInfo等信息按照激活、完成、忽略、失败等stage状态统计。并且存储StageId与JobId的一对多关系。这些统计信息最终会被JobPage和StagePage等页面访问和渲染。JobProgressListener的数据结构见代码清单3-17。
代码清单3-17 JobProgressListener维护的信息
class JobProgressListener(conf: SparkConf) extends SparkListener with Logging { import JobProgressListener._ type JobId = Int type StageId = Int type StageAttemptId = Int type PoolName = String type ExecutorId = String // Jobs: val activeJobs = new HashMap[JobId, JobUIData] val completedJobs = ListBuffer[JobUIData]() val failedJobs = ListBuffer[JobUIData]() val jobIdToData = new HashMap[JobId, JobUIData] // Stages: val activeStages = new HashMap[StageId, StageInfo] val completedStages = ListBuffer[StageInfo]() val skippedStages = ListBuffer[StageInfo]() val failedStages = ListBuffer[StageInfo]() val stageIdToData = new HashMap[(StageId, StageAttemptId), StageUIData] val stageIdToInfo = new HashMap[StageId, StageInfo] val stageIdToActiveJobIds = new HashMap[StageId, HashSet[JobId]] val poolToActiveStages = HashMap[PoolName, HashMap[StageId, StageInfo]]() var numCompletedStages = 0 // 总共完成的Stage数量 var numFailedStages = 0 / 总共失败的Stage数量 // Misc: val executorIdToBlockManagerId = HashMap[ExecutorId, BlockManagerId]() def blockManagerIds = executorIdToBlockManagerId.values.toSeq var schedulingMode: Option[SchedulingMode] = None // number of non-active jobs and stages (there is no limit for active jobs and stages): val retainedStages = conf.getInt("spark.ui.retainedStages", DEFAULT_RETAINED_STAGES) val retainedJobs = conf.getInt("spark.ui.retainedJobs", DEFAULT_RETAINED_JOBS)
JobProgressListener 实现了onJobStart、onJobEnd、onStageCompleted、onStageSubmitted、onTaskStart、onTaskEnd等方法,这些方法正是在listenerBus的驱动下,改变JobProgressListener中的各种Job、Stage相关的数据。
创建SparkUI的实现,见代码清单3-18。
代码清单3-18 SparkUI的声明
private[spark] val ui: Option[SparkUI] = if (conf.getBoolean("spark.ui.enabled", true)) { Some(SparkUI.createLiveUI(this, conf, listenerBus, jobProgressListener, env.securityManager,appName)) } else { None } ui.foreach(_.bind())
可以看到如果不需要提供SparkUI服务,可以将属性spark.ui.enabled修改为false。其中createLiveUI实际是调用了create方法,见代码清单3-19。
代码清单3-19 SparkUI的创建
def createLiveUI( sc: SparkContext, conf: SparkConf, listenerBus: SparkListenerBus, jobProgressListener: JobProgressListener, securityManager: SecurityManager, appName: String): SparkUI = { create(Some(sc), conf, listenerBus, securityManager, appName, jobProgressListener = Some(jobProgressListener)) }
在create方法里,除了JobProgressListener是外部传入的之外,又增加了一些SparkListener。例如,用于对JVM参数、Spark属性、Java系统属性、classpath等进行监控的EnvironmentListener;用于维护executor的存储状态的StorageStatusListener;用于准备将executor的信息展示在ExecutorsTab的ExecutorsListener;用于准备将executor相关存储信息展示在BlockManagerUI的StorageListener等。最后创建SparkUI,参见代码清单3-20。
代码清单3-20 create方法的实现
private def create( sc: Option[SparkContext], conf: SparkConf, listenerBus: SparkListenerBus, securityManager: SecurityManager, appName: String, basePath: String = "", jobProgressListener: Option[JobProgressListener] = None): SparkUI = { val _jobProgressListener: JobProgressListener = jobProgressListener.getOrElse { val listener = new JobProgressListener(conf) listenerBus.addListener(listener) listener } val environmentListener = new EnvironmentListener val storageStatusListener = new StorageStatusListener val executorsListener = new ExecutorsListener(storageStatusListener) val storageListener = new StorageListener(storageStatusListener) listenerBus.addListener(environmentListener) listenerBus.addListener(storageStatusListener) listenerBus.addListener(executorsListener) listenerBus.addListener(storageListener) new SparkUI(sc, conf, securityManager, environmentListener, storageStatusListener, executorsListener, _jobProgressListener, storageListener, appName, basePath) }
SparkUI服务默认是可以被杀掉的,通过修改属性spark.ui.killEnabled为false可以保证不被杀死。initialize方法,会组织前端页面各个Tab和Page的展示及布局,参见代码清单3-21。
代码清单3-21 SparkUI的初始化
private[spark] class SparkUI private ( val sc: Option[SparkContext], val conf: SparkConf, val securityManager: SecurityManager, val environmentListener: EnvironmentListener, val storageStatusListener: StorageStatusListener, val executorsListener: ExecutorsListener, val jobProgressListener: JobProgressListener, val storageListener: StorageListener, var appName: String, val basePath: String) extends WebUI(securityManager, SparkUI.getUIPort(conf), conf, basePath, "SparkUI") with Logging { val killEnabled = sc.map(_.conf.getBoolean("spark.ui.killEnabled", true)).getOrElse(false) /** Initialize all components of the server. */ def initialize() { attachTab(new JobsTab(this)) val stagesTab = new StagesTab(this) attachTab(stagesTab) attachTab(new StorageTab(this)) attachTab(new EnvironmentTab(this)) attachTab(new ExecutorsTab(this)) attachHandler(createStaticHandler(SparkUI.STATIC_RESOURCE_DIR, "/static")) attachHandler(createRedirectHandler("/", "/jobs", basePath = basePath)) attachHandler( createRedirectHandler("/stages/stage/kill", "/stages", stagesTab.handleKillRequest)) } initialize()
SparkUI究竟是如何实现页面布局及展示的?JobsTab展示所有Job的进度、状态信息,这里我们以它为例来说明。JobsTab会复用SparkUI的killEnabled、SparkContext、jobProgressListener,包括AllJobsPage和JobPage两个页面,见代码清单3-22。
代码清单3-22 JobsTab的实现
private[ui] class JobsTab(parent: SparkUI) extends SparkUITab(parent, "jobs") { val sc = parent.sc val killEnabled = parent.killEnabled def isFairScheduler = listener.schedulingMode.exists(_ == SchedulingMode.FAIR) val listener = parent.jobProgressListener attachPage(new AllJobsPage(this)) attachPage(new JobPage(this)) }
AllJobsPage由render方法渲染,利用jobProgressListener中的统计监控数据生成激活、完成、失败等状态的Job摘要信息,并调用jobsTable方法生成表格等html元素,最终使用UIUtils的headerSparkPage封装好css、js、header及页面布局等,见代码清单3-23。
代码清单3-23 AllJobsPage的实现
def render(request: HttpServletRequest): Seq[Node] = { listener.synchronized { val activeJobs = listener.activeJobs.values.toSeq val completedJobs = listener.completedJobs.reverse.toSeq val failedJobs = listener.failedJobs.reverse.toSeq val now = System.currentTimeMillis val activeJobsTable = jobsTable(activeJobs.sortBy(_.startTime.getOrElse(-1L)).reverse) val completedJobsTable = jobsTable(completedJobs.sortBy(_.endTime.getOrElse(-1L)).reverse) val failedJobsTable = jobsTable(failedJobs.sortBy(_.endTime.getOrElse(-1L)).reverse) val summary: NodeSeq = <div> <ul class="unstyled"> {if (startTime.isDefined) { // Total duration is not meaningful unless the UI is live <li> <strong>Total Duration: </strong> {UIUtils.formatDuration(now - startTime.get)} </li> }} <li> <strong>Scheduling Mode: </strong> {listener.schedulingMode.map(_.toString).getOrElse("Unknown")} </li> <li> <a href="#active"><strong>Active Jobs:</strong></a> {activeJobs.size} </li> <li> <a href="#completed"><strong>Completed Jobs:</strong></a> {completedJobs.size} </li> <li> <a href="#failed"><strong>Failed Jobs:</strong></a> {failedJobs.size} </li> </ul> </div>
jobsTable用来生成表格数据,见代码清单3-24。
代码清单3-24 jobsTable处理表格的实现
private def jobsTable(jobs: Seq[JobUIData]): Seq[Node] = { val someJobHasJobGroup = jobs.exists(_.jobGroup.isDefined) val columns: Seq[Node] = { <th>{if (someJobHasJobGroup) "Job Id (Job Group)" else "Job Id"}</th> <th>Description</th> <th>Submitted</th> <th>Duration</th> <th class="sorttable_nosort">Stages: Succeeded/Total</th> <th class="sorttable_nosort">Tasks (for all stages): Succeeded/Total</th> } <table class="table table-bordered table-striped table-condensed sortable"> <thead>{columns}</thead> <tbody> {jobs.map(makeRow)} </tbody> </table> }
表格中每行数据又是通过makeRow方法渲染的,参见代码清单3-25。
代码清单3-25 生成表格中的行
def makeRow(job: JobUIData): Seq[Node] = { val lastStageInfo = Option(job.stageIds) .filter(_.nonEmpty) .flatMap { ids => listener.stageIdToInfo.get(ids.max) } val lastStageData = lastStageInfo.flatMap { s => listener.stageIdToData.get((s.stageId, s.attemptId)) } val isComplete = job.status == JobExecutionStatus.SUCCEEDED val lastStageName = lastStageInfo.map(_.name).getOrElse("(Unknown Stage Name)") val lastStageDescription = lastStageData.flatMap(_.description).getOrElse("") val duration: Option[Long] = { job.startTime.map { start => val end = job.endTime.getOrElse(System.currentTimeMillis()) end - start } } val formattedDuration = duration.map(d => UIUtils.formatDuration(d)).getOrElse("Unknown") val formattedSubmissionTime = job.startTime.map(UIUtils.formatDate).getOrElse("Unknown") val detailUrl = "%s/jobs/job?id=%s".format(UIUtils.prependBaseUri(parent.basePath), job.jobId) <tr> <td sorttable_customkey={job.jobId.toString}> {job.jobId} {job.jobGroup.map(id => s"($id)").getOrElse("")} </td> <td> <div><em>{lastStageDescription}</em></div> <a href={detailUrl}>{lastStageName}</a> </td> <td sorttable_customkey={job.startTime.getOrElse(-1).toString}> {formattedSubmissionTime} </td> <td sorttable_customkey={duration.getOrElse(-1).toString}>{formattedDuration}</td> <td class="stage-progress-cell"> {job.completedStageIndices.size}/{job.stageIds.size - job.numSkippedStages} {if (job.numFailedStages > 0) s"(${job.numFailedStages} failed)"} {if (job.numSkippedStages > 0) s"(${job.numSkippedStages} skipped)"} </td> <td class="progress-cell"> {UIUtils.makeProgressBar(started = job.numActiveTasks, completed = job.numCompletedTasks, failed = job.numFailedTasks, skipped = job.numSkippedTasks, total = job.numTasks - job.numSkippedTasks)} </td> </tr> }
代码清单3-22中的attachPage方法存在于JobsTab的父类WebUITab中,WebUITab维护有ArrayBuffer[WebUIPage]的数据结构,AllJobsPage和JobPage将被放入此ArrayBuffer中,参见代码清单3-26。
代码清单3-26 WebUITab的实现
private[spark] abstract class WebUITab(parent: WebUI, val prefix: String) { val pages = ArrayBuffer[WebUIPage]() val name = prefix.capitalize /** Attach a page to this tab. This prepends the page‘s prefix with the tab‘s own prefix. */ def attachPage(page: WebUIPage) { page.prefix = (prefix + "/" + page.prefix).stripSuffix("/") pages += page } /** Get a list of header tabs from the parent UI. */ def headerTabs: Seq[WebUITab] = parent.getTabs def basePath: String = parent.getBasePath }
JobsTab创建之后,将被attachTab方法加入SparkUI的ArrayBuffer[WebUITab]中,并且通过attachPage方法,给每一个page生成org.eclipse.jetty.servlet.ServletContextHandler,最后调用attachHandler方法将ServletContextHandler绑定到SparkUI,即加入到handlers :ArrayBuffer[ServletContextHandler]和样例类ServerInfo样例类的rootHandler(ContextHandlerCollection)中。SparkUI继承自WebUI,attachTab方法在WebUI中实现,参见代码清单3-27。
代码清单3-27 WebUI的实现
private[spark] abstract class WebUI( securityManager: SecurityManager, port: Int, conf: SparkConf, basePath: String = "", name: String = "") extends Logging { protected val tabs = ArrayBuffer[WebUITab]() protected val handlers = ArrayBuffer[ServletContextHandler]() protected var serverInfo: Option[ServerInfo] = None protected val localHostName = Utils.localHostName() protected val publicHostName = Option(System.getenv("SPARK_PUBLIC_DNS")).getOrElse(localHostName) private val className = Utils.getFormattedClassName(this) def getBasePath: String = basePath def getTabs: Seq[WebUITab] = tabs.toSeq def getHandlers: Seq[ServletContextHandler] = handlers.toSeq def getSecurityManager: SecurityManager = securityManager /** Attach a tab to this UI, along with all of its attached pages. */ def attachTab(tab: WebUITab) { tab.pages.foreach(attachPage) tabs += tab } /** Attach a page to this UI. */ def attachPage(page: WebUIPage) { val pagePath = "/" + page.prefix attachHandler(createServletHandler(pagePath, (request: HttpServletRequest) => page.render(request), securityManager, basePath)) attachHandler(createServletHandler(pagePath.stripSuffix("/") + "/json", (request: HttpServletRequest) => page.renderJson(request), securityManager, basePath)) } /** Attach a handler to this UI. */ def attachHandler(handler: ServletContextHandler) { handlers += handler serverInfo.foreach { info => info.rootHandler.addHandler(handler) if (!handler.isStarted) { handler.start() } } }
由于代码清单3-27所在的类中使用import org.apache.spark.ui.JettyUtils._导入了JettyUtils的静态方法,所以createServletHandler方法实际是JettyUtils 的静态方法createServletHandler。createServletHandler实际创建了javax.servlet.http.HttpServlet的匿名内部类实例,此实例实际使用(request: HttpServletRequest) => page.render(request)这个函数参数来处理请求,进而渲染页面呈现给用户。有关createServletHandler的实现,及Jetty的相关信息,请参阅附录C。
parkUI创建好后,需要调用父类WebUI的bind方法,绑定服务和端口,bind方法中主要的代码实现如下。
serverInfo = Some(startJettyServer("0.0.0.0", port, handlers, conf, name))
JettyUtils的静态方法startJettyServer的实现请参阅附录C。最终启动了Jetty提供的服务,默认端口是4040。
默认情况下,Spark使用HDFS作为分布式文件系统,所以需要获取Hadoop相关配置信息的代码如下。
val hadoopConfiguration = SparkHadoopUtil.get.newConfiguration(conf)
获取的配置信息包括:
q Amazon S3文件系统AccessKeyId和SecretAccessKey加载到Hadoop的Configuration;
q 将SparkConf中所有spark.hadoop.开头的属性都复制到Hadoop的Configuration;
q 将SparkConf的属性spark.buffer.size复制为Hadoop的Configuration的配置io.file.buffer.size。
注意:如果指定了SPARK_YARN_MODE属性,则会使用YarnSparkHadoopUtil,否则默认为SparkHadoopUtil。
对Executor的环境变量的处理,参见代码清单3-28。executorEnvs 包含的环境变量将会在7.2.2节中介绍的注册应用的过程中发送给Master,Master给Worker发送调度后,Worker最终使用executorEnvs提供的信息启动Executor。可以通过配置spark.executor.memory指定Executor占用的内存大小,也可以配置系统变量SPARK_EXECUTOR_MEMORY或者SPARK_MEM对其大小进行设置。
代码清单3-28 Executor 环境变量的处理
private[spark] val executorMemory = conf.getOption("spark.executor.memory") .orElse(Option(System.getenv("SPARK_EXECUTOR_MEMORY"))) .orElse(Option(System.getenv("SPARK_MEM")).map(warnSparkMem)) .map(Utils.memoryStringToMb) .getOrElse(512) // Environment variables to pass to our executors. private[spark] val executorEnvs = HashMap[String, String]() for { (envKey, propKey) <- Seq(("SPARK_TESTING", "spark.testing")) value <- Option(System.getenv(envKey)).orElse(Option(System.getProperty(propKey)))} { executorEnvs(envKey) = value } Option(System.getenv("SPARK_PREPEND_CLASSES")).foreach { v => executorEnvs("SPARK_PREPEND_CLASSES") = v } // The Mesos scheduler backend relies on this environment variable to set executor memory. executorEnvs("SPARK_EXECUTOR_MEMORY") = executorMemory + "m" executorEnvs ++= conf.getExecutorEnv // Set SPARK_USER for user who is running SparkContext. val sparkUser = Option { Option(System.getenv("SPARK_USER")).getOrElse(System.getProperty("user.name")) }.getOrElse { SparkContext.SPARK_UNKNOWN_USER } executorEnvs("SPARK_USER") = sparkUser
TaskScheduler也是SparkContext的重要组成部分,负责任务的提交,并且请求集群管理器对任务调度。TaskScheduler也可以看做任务调度的客户端。创建TaskScheduler的代码如下。
private[spark] var (schedulerBackend, taskScheduler) = SparkContext.createTaskScheduler(this, master)
createTaskScheduler方法会根据master的配置匹配部署模式,创建TaskSchedulerImpl,并生成不同的SchedulerBackend。本章为了使读者更容易理解Spark的初始化流程,故以local模式为例,其余模式将在第6章详解。master匹配local模式的代码如下。
master match { case "local" => val scheduler = new TaskSchedulerImpl(sc, MAX_LOCAL_TASK_FAILURES, isLocal = true) val backend = new LocalBackend(scheduler, 1) scheduler.initialize(backend) (backend, scheduler)
TaskSchedulerImpl的构造过程如下:
1) 从SparkConf中读取配置信息,包括每个任务分配的CPU数、调度模式(调度模式有FAIR和FIFO两种,默认为FIFO,可以修改属性spark.scheduler.mode来改变)等。
2) 创建TaskResultGetter,它的作用是通过线程池(Executors.newFixedThreadPool创建的,默认4个线程,线程名字以task-result-getter开头,线程工厂默认是Executors.defaultThreadFactory),对slave发送的task的执行结果进行处理。
TaskSchedulerImpl的主要组成,见代码清单3-29。
代码清单3-29 TaskSchedulerImpl的实现
var dagScheduler: DAGScheduler = null var backend: SchedulerBackend = null val mapOutputTracker = SparkEnv.get.mapOutputTracker var schedulableBuilder: SchedulableBuilder = null var rootPool: Pool = null // default scheduler is FIFO private val schedulingModeConf = conf.get("spark.scheduler.mode", "FIFO") val schedulingMode: SchedulingMode = try { SchedulingMode.withName(schedulingModeConf.toUpperCase) } catch { case e: java.util.NoSuchElementException => throw new SparkException(s"Unrecognized spark.scheduler.mode: $schedulingModeConf") } // This is a var so that we can reset it for testing purposes. private[spark] var taskResultGetter = new TaskResultGetter(sc.env, this)
TaskSchedulerImpl的调度模式有FAIR和FIFO两种。任务的最终调度实际都是落实到接口SchedulerBackend的具体实现上的。为方便分析,我们先来看看local模式中SchedulerBackend的实现LocalBackend。LocalBackend依赖于LocalActor与ActorSystem进行消息通信。LocalBackend参见代码清单3-30。
代码清单3-30 LocalBackend的实现
private[spark] class LocalBackend(scheduler: TaskSchedulerImpl, val totalCores: Int) extends SchedulerBackend with ExecutorBackend { private val appId = "local-" + System.currentTimeMillis var localActor: ActorRef = null override def start() { localActor = SparkEnv.get.actorSystem.actorOf( Props(new LocalActor(scheduler, this, totalCores)), "LocalBackendActor") } override def stop() { localActor ! StopExecutor } override def reviveOffers() { localActor ! ReviveOffers } override def defaultParallelism() = scheduler.conf.getInt("spark.default.parallelism", totalCores) override def killTask(taskId: Long, executorId: String, interruptThread: Boolean) { localActor ! KillTask(taskId, interruptThread) } override def statusUpdate(taskId: Long, state: TaskState, serializedData: ByteBuffer) { localActor ! StatusUpdate(taskId, state, serializedData) } override def applicationId(): String = appId }
创建完TaskSchedulerImpl和LocalBackend后,对TaskSchedulerImpl调用方法initialize进行初始化。初始化过程如下:
1) 使TaskSchedulerImpl持有LocalBackend的引用。
2) 创建Pool,Pool中缓存了调度队列、调度算法及TaskSetManager集合等信息。
3) 创建FIFOSchedulableBuilder,FIFOSchedulableBuilder用来操作Pool中的调度队列。
Initialize方法的实现见代码清单3-31。
代码清单3-31 TaskSchedulerImpl的初始化
def initialize(backend: SchedulerBackend) { this.backend = backend rootPool = new Pool("", schedulingMode, 0, 0) schedulableBuilder = { schedulingMode match { case SchedulingMode.FIFO => new FIFOSchedulableBuilder(rootPool) case SchedulingMode.FAIR => new FairSchedulableBuilder(rootPool, conf) } } schedulableBuilder.buildPools() }
DAGScheduler主要用于在任务正式交给TaskSchedulerImpl提交之前做一些准备工作,包括:创建Job,将DAG中的RDD划分到不同的Stage、提交Stage,等等。创建DAGScheduler的代码如下。
@volatile private[spark] var dagScheduler: DAGScheduler = _ dagScheduler = new DAGScheduler(this)
DAGScheduler的数据结构主要维护jobId和stageId的关系、Stage、ActiveJob,以及缓存的RDD的partitions的位置信息,见代码清单3-32。
代码清单3-32 DAGScheduler维护的数据结构
private[scheduler] val nextJobId = new AtomicInteger(0) private[scheduler] def numTotalJobs: Int = nextJobId.get() private val nextStageId = new AtomicInteger(0) private[scheduler] val jobIdToStageIds = new HashMap[Int, HashSet[Int]] private[scheduler] val stageIdToStage = new HashMap[Int, Stage] private[scheduler] val shuffleToMapStage = new HashMap[Int, Stage] private[scheduler] val jobIdToActiveJob = new HashMap[Int, ActiveJob] // Stages we need to run whose parents aren‘t done private[scheduler] val waitingStages = new HashSet[Stage] // Stages we are running right now private[scheduler] val runningStages = new HashSet[Stage] // Stages that must be resubmitted due to fetch failures private[scheduler] val failedStages = new HashSet[Stage] private[scheduler] val activeJobs = new HashSet[ActiveJob] // Contains the locations that each RDD‘s partitions are cached on private val cacheLocs = new HashMap[Int, Array[Seq[TaskLocation]]] private val failedEpoch = new HashMap[String, Long] private val dagSchedulerActorSupervisor = env.actorSystem.actorOf(Props(new DAGSchedulerActorSupervisor(this))) private val closureSerializer = SparkEnv.get.closureSerializer.newInstance()
在构造DAGScheduler的时候会调用initializeEventProcessActor方法创建DAGSchedulerEventProcessActor,见代码清单3-33。
代码清单3-33 DAGSchedulerEventProcessActor的初始化
private[scheduler] var eventProcessActor: ActorRef = _ private def initializeEventProcessActor() { // blocking the thread until supervisor is started, which ensures eventProcessActor is // not null before any job is submitted implicit val timeout = Timeout(30 seconds) val initEventActorReply = dagSchedulerActorSupervisor ? Props(new DAGSchedulerEventProcessActor(this)) eventProcessActor = Await.result(initEventActorReply, timeout.duration). asInstanceOf[ActorRef] } initializeEventProcessActor()
这里的DAGSchedulerActorSupervisor主要作为DAGSchedulerEventProcessActor的监管者,负责生成DAGSchedulerEventProcessActor。从代码清单3-34可以看出,DAGSchedulerActorSupervisor对于DAGSchedulerEventProcessActor采用了Akka的一对一监管策略。DAGSchedulerActorSupervisor一旦生成DAGSchedulerEventProcessActor,并注册到ActorSystem,ActorSystem就会调用DAGSchedulerEventProcessActor的preStart,taskScheduler于是就持有了dagScheduler,见代码清单3-35。从代码清单3-35我们还看到DAGSchedulerEventProcessActor所能处理的消息类型,比如handleJobSubmitted、handleBeginEvent、handleTaskCompletion等。DAGSchedulerEventProcessActor接受这些消息后会有不同的处理动作,在本章,读者只需要理解到这里即可,后面章节用到时会详细分析。
代码清单3-34 DAGSchedulerActorSupervisor的监管策略
private[scheduler] class DAGSchedulerActorSupervisor(dagScheduler: DAGScheduler) extends Actor with Logging { override val supervisorStrategy = OneForOneStrategy() { case x: Exception => logError("eventProcesserActor failed; shutting down SparkContext", x) try { dagScheduler.doCancelAllJobs() } catch { case t: Throwable => logError("DAGScheduler failed to cancel all jobs.", t) } dagScheduler.sc.stop() Stop } def receive = { case p: Props => sender ! context.actorOf(p) case _ => logWarning("received unknown message in DAGSchedulerActorSupervisor") } }
代码清单3-35 DAGSchedulerEventProcessActor的实现
private[scheduler] class DAGSchedulerEventProcessActor(dagScheduler: DAGScheduler) extends Actor with Logging { override def preStart() { dagScheduler.taskScheduler.setDAGScheduler(dagScheduler) } /** * The main event loop of the DAG scheduler. */ def receive = { case JobSubmitted(jobId, rdd, func, partitions, allowLocal, callSite, listener, properties) => dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, allowLocal, callSite, listener, properties) case StageCancelled(stageId) => dagScheduler.handleStageCancellation(stageId) case JobCancelled(jobId) => dagScheduler.handleJobCancellation(jobId) case JobGroupCancelled(groupId) => dagScheduler.handleJobGroupCancelled(groupId) case AllJobsCancelled => dagScheduler.doCancelAllJobs() case ExecutorAdded(execId, host) => dagScheduler.handleExecutorAdded(execId, host) case ExecutorLost(execId) => dagScheduler.handleExecutorLost(execId, fetchFailed = false) case BeginEvent(task, taskInfo) => dagScheduler.handleBeginEvent(task, taskInfo) case GettingResultEvent(taskInfo) => dagScheduler.handleGetTaskResult(taskInfo) case completion @ CompletionEvent(task, reason, _, _, taskInfo, taskMetrics) => dagScheduler.handleTaskCompletion(completion) case TaskSetFailed(taskSet, reason) => dagScheduler.handleTaskSetFailed(taskSet, reason) case ResubmitFailedStages => dagScheduler.resubmitFailedStages() } override def postStop() { // Cancel any active jobs in postStop hook dagScheduler.cleanUpAfterSchedulerStop() }
未完待续。。。
后记:自己牺牲了7个月的周末和下班空闲时间,通过研究Spark源码和原理,总结整理的《深入理解Spark:核心思想与源码分析》一书现在已经正式出版上市,目前亚马逊、京东、当当、天猫等网站均有销售,欢迎感兴趣的同学购买。我开始研究源码时的Spark版本是1.2.0,经过7个多月的研究和出版社近4个月的流程,Spark自身的版本迭代也很快,如今最新已经是1.6.0。目前市面上另外2本源码研究的Spark书籍的版本分别是0.9.0版本和1.2.0版本,看来这些书的作者都与我一样,遇到了这种问题。由于研究和出版都需要时间,所以不能及时跟上Spark的脚步,还请大家见谅。但是Spark核心部分的变化相对还是很少的,如果对版本不是过于追求,依然可以选择本书。

京东(现有满100减30活动):http://item.jd.com/11846120.html
当当:http://product.dangdang.com/23838168.html
《深入理解SPARK:核心思想与源码分析》——SparkContext的初始化(中)
标签:
原文地址:http://www.cnblogs.com/jiaan-geng/p/5206760.html