标签:
大概敲了一遍基本命令,熟悉了redis的存储方式。现在开始进一步系统的学习。学习教程目前计划有三个,一个是github上的https://github.com/JasonLai256/the-little-redis-book/blob/master/cn/redis.md,一个是中文官方网站http://www.redis.cn/documentation.html,还有一个看起来像w3c风格的简单教程http://www.runoob.com/redis/redis-commands.html。
我一般喜欢看别人怎么学习的,然后再通过官方文档去学习。因此学习路线首先是github,然后runoob,最后看官方文档。
集合数据结构常常被用来存储只能唯一存在的值,并提供了许多的基于集合的操作,例如并集。集合数据结构没有对值进行排序,但是其提供了高效的基于值的操作。使用集合数据结构的典型用例是朋友名单的实现:
首先存储两个人leto,duncan的各自的好友set:
sadd friends:leto ghanima paul chani jessica miao
sadd frineds:duncan goku paul jessica alia rui
可以查看leto的好友:
127.0.0.1:6379> smembers friends:leto 1) "jessica" 2) "chani" 3) "paul" 4) "ghanima"
可以查看jessica是不是leto的好友O(1)
127.0.0.1:6379> sismember friends:leto jessica (integer) 1
可以查看leto和duncan的共同好友
127.0.0.1:6379> sinter friends:leto friends:duncan 1) "jessica" 2) "paul"
还可以将好友关系存储到新key
127.0.0.1:6379> sinterstore friends:leto_duncan friends:leto friends:duncan (integer) 2 127.0.0.1:6379> smembers friends:leto_duncan 1) "jessica" 2) "paul"
Sorted Sets提供了排序(sorting)和秩划分(ranking)的功能。如果我们想要一个秩分类的朋友名单,可以这样做:
127.0.0.1:6379> zadd friends:duncan 70 ghanima 95 paul 95 chani 75 jessica 1 vladimir
对于duncan的朋友,要怎样计算出标记(score)为90或更高的人数?
127.0.0.1:6379> zcount friends:duncan 90 100 (integer) 2
如何获取chani在名单里的秩(rank即排名)?
127.0.0.1:6379> zrevrank friends:duncan chani (integer) 1
首先,存储user:
127.0.0.1:6379> set users:9001 "{id:9001,email:leto@dune.gov,..}" OK
然后,根据id查询用户
127.0.0.1:6379> get users:9001 "{id:9001,email:leto@dune.gov,..}"
如果想要根据email来查询该怎么办呢,这里就要用散列数据结构:
127.0.0.1:6379> hset users:lookup:email leto@dune.gov 9001 (integer) 1
这里,通过域来作为一个二级索引,然后通过id去引用单个用户对象。
127.0.0.1:6379> hget users:lookup:email leto@dune.gov "9001" 127.0.0.1:6379> get users:9001 "{id:9001,email:leto@dune.gov,..}"
通俗的理解,用户是通过id标记的,即id相当于主键,然后email唯一,想通过email来实现该怎么办呢,那就把email链接到id。由于email的唯一性,可以把它当做field放入hset,id作为对应value。
同上面的用法,用一个hash的field来存储关键字,根据field来取值。我们知道redis有keys的命令,可以扫描所有的keys找出匹配项,但太慢了。比如将每个用户的bug存储起来,假设用户id为1233的bug类型为bug:1233,每个bug有唯一id,即bug:1233:id。如果将这个当做key存储到redis中,当想要查询用户bug或删除用户bug时可以这样:
keys bug:1233:*
但是用散列数据结构更好一些。
#记录1233的bug
127.0.0.1:6379> hset bugs:1233 1 "{id:1,account:1233,subject:‘...‘}" (integer) 1 127.0.0.1:6379> hset bugs:1233 2 "{id:1,account:1233,subject:‘...‘}" (integer) 1
#查看1233的所有bug
127.0.0.1:6379> hkeys bugs:1233
1) "1"
2) "2"
#删除id为2的bug
127.0.0.1:6379> hdel bugs:1233 2
(integer) 1
127.0.0.1:6379> hkeys bugs:1233
1) "1"
用户删除后删除对应的所有bug
127.0.0.1:6379> del bugs:1233
(integer) 1
redis对于list有lpop和rpop命令,是将list中的元素从一端取出并移除。还有另一个阻塞版本,即blpop、brpop。同样是取出并移除一端的元素,但如果list没有元素了就会阻塞,直到有元素为止。就是生产者-消费者模式。
BLPOP list [list ...] timeout :从list中取出并移除元素,没有元素则阻塞,timeout为超时时间,=0表示永不超时。如果超时后没有元素则返回一组nil ,若有元素则返回key,value,key为list名
打开多个redis-cli,第一个:
127.0.0.1:6379> lpush list1 1 (integer) 1 127.0.0.1:6379> lpush list1 12 (integer) 2 127.0.0.1:6379> lpush list1 123 (integer) 3 127.0.0.1:6379> lpush list2 1234 (integer) 1
第二个:
127.0.0.1:6379> blpop list list1 list2 0 1) "list1" 2) "123" 127.0.0.1:6379> blpop list list1 list2 0 1) "list1" 2) "12" 127.0.0.1:6379> blpop list list1 list2 0 1) "list1" 2) "1" 127.0.0.1:6379> blpop list list1 list2 0 1) "list2" 2) "1234" 127.0.0.1:6379> blpop list list1 list2 0
发现当list都没有值的时候,线程阻塞。这时候在第一个客户端追加:
127.0.0.1:6379> lpush list 12345 (integer) 1
然后另一个阻塞的客户端会立即响应:
127.0.0.1:6379> blpop list list1 list2 0 1) "list" 2) "12345" (248.85s)
打开第一个客户端和第二个客户端,都输入subscribe warnings。意思是订阅一个叫做warnings的管道。
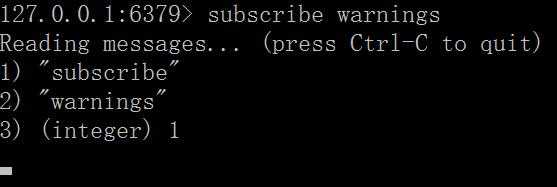
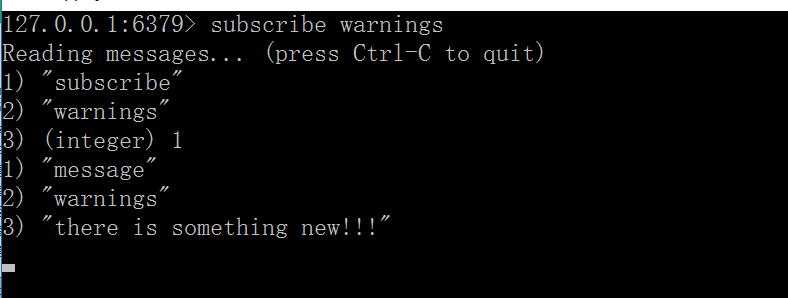
然后打开第三个客户端输入:publish warnings "there is something new!!!",下面的2表示两个客户端收到通知。

这时会,前两个客户端都会受到消息:
sort命令是Redis最强大的命令之一。它让你可以在一个列表、集合或者分类集合里对值进行排序(分类集合是通过标记来进行排序,而不是集合里的成员)SORT key [BY pattern] [LIMIT offset count] [GET pattern [GET pattern ...]] [ASC|DESC] [ALPHA] [STORE destination]
summary: Sort the elements in a list, set or sorted set
127.0.0.1:6379> rpush users:leto:guesses 5 9 10 2 4 10 19 2 (integer) 8 127.0.0.1:6379> sort users:leto:guesses 1) "2" 2) "2" 3) "4" 4) "5" 5) "9" 6) "10" 7) "10" 8) "19"
127.0.0.1:6379> sadd friends:ghanima leto paul chani jessica alia duncan (integer) 6 127.0.0.1:6379> sort friends:ghanima limit 0 3 desc alpha 1) "paul" 2) "leto" 3) "jessica"
sort命令的真正力量是其基于引用对象来进行排序的能力例如,假设我们有一个Bug追踪器能让用户看到各类已存在问题。我们可能使用一个集合数据结构去追踪正在被监视的问题:
127.0.0.1:6379> sadd watch:leto 12339 1282 228 9338 (integer) 4
#set bug编号 bug_level
127.0.0.1:6379> set serverity:12339 3
OK
127.0.0.1:6379> set serverity:1282 2
OK
127.0.0.1:6379> set serverity:228 5
OK
127.0.0.1:6379> ser serverity:9388 4
(error) ERR unknown command ‘ser‘
127.0.0.1:6379> set serverity:9388 4
OK
要通过问题的严重性来降序排序这些Bug,你可以这样做:
127.0.0.1:6379> sort watch:leto by serverity:* desc 1) "228" 2) "12339" 3) "1282" 4) "9338"
Redis将会用存储在列表(集合或分类集合)中的值去替代模式中的*(通过by)。这会创建出关键字名字,Redis将通过查询其实际值来排序。
先插入散列:
127.0.0.1:6379> hset bug:12339 severity 3 (integer) 1 127.0.0.1:6379> hset bug:12339 priority 1 (integer) 1 127.0.0.1:6379> hset bug:12339 detail "{id:12339,...}" (integer) 1 127.0.0.1:6379> hmset bug:1382 severity 2 priority 2 detail "{id:1382,...}" OK 127.0.0.1:6379> hmset bug:338 severity 5 priority 3 detail "{id:338,...}" OK 127.0.0.1:6379> hmset bug:9338 severity 4 priority 2 detail "{id:9338}" OK
再插入bug set
127.0.0.1:6379> del watch:leto (integer) 1 127.0.0.1:6379> sadd watch:leto 12339 1382 338 (integer) 3
现在知道bug集合watch:leto,知道bug的详细信息bug:*,要求将bug集合的bug信息打印出来,并根据priority排序:
127.0.0.1:6379> sort watch:leto by bug:*->priority get bug:*->detail 1) "{id:12339,...}" 2) "{id:1382,...}" 3) "{id:338,...}"
当然,还可以获取多个参数:
127.0.0.1:6379> sort watch:leto by bug:*->priority get bug:*->detail get bug:*->priority get bug:*->severity 1) "{id:12339,...}" 2) "1" 3) "3" 4) "{id:1382,...}" 5) "2" 6) "2" 7) "{id:338,...}" 8) "3" 9) "5"
也可以获取到*当前所代表的值,即set中取出的值:用get #
127.0.0.1:6379> sort watch:leto by bug:*->priority get bug:*->detail get bug:*->priority get bug:*->severity get # 1) "{id:12339,...}" 2) "1" 3) "3" 4) "12339" 5) "{id:1382,...}" 6) "2" 7) "2" 8) "1382" 9) "{id:338,...}" 10) "3" 11) "5" 12) "338"
使用我们已经看过的
expiration命令,再结合sort命令的store能力,这是一个美妙的组合。
标签:
原文地址:http://www.cnblogs.com/woshimrf/p/5205749.html