标签:
1.OS模块
>>> os.getcwd()‘C:\\Users\\soft‘
>>> os.chdir("c:/")>>> os.getcwd()‘c:\\‘
>>> os.chdir("D:/")>>> os.getcwd()‘D:\\‘>>> os.makedirs("test1/test2")

>>> os.removedirs("test1/test2")>>> os.removedirs("test1")Traceback (most recent call last):File "<stdin>", line 1, in <module>File "C:\Python27\lib\os.py", line 170, in removedirsrmdir(name)WindowsError: [Error 145] : ‘test1‘不为空则报错
>>> os.rename("test3","test4")- 注:若新的文件名存在,执行不会成功,会报错。
>>> os.stat("test4")nt.stat_result(st_mode=16895, st_ino=0L, st_dev=0L, st_nlink=0, st_uid=0, st_gid=0, st_size=0L, st_atime=1456118359L, st_mtime=1456118359L, st_ctime=1456118359L)注:test4为目录>>> os.stat("test1/1.txt")nt.stat_result(st_mode=33206, st_ino=0L, st_dev=0L, st_nlink=0, st_uid=0, st_gid=0, st_size=0L, st_atime=1456113732L, st_mtime=1456113732L, st_ctime=1456113732L)注:默认返回的时间为时间戳,需要使用time模块进行格式转换>>> time.ctime(1456113732L) ‘Mon Feb 22 12:02:12 2016‘
>>> os.getcwd()‘C:\\Users\\soft‘>>> os.system("ping 127.0.0.1")正在 Ping 127.0.0.1 具有 32 字节的数据:来自 127.0.0.1 的回复: 字节=32 时间<1ms TTL=200来自 127.0.0.1 的回复: 字节=32 时间<1ms TTL=200来自 127.0.0.1 的回复: 字节=32 时间<1ms TTL=200来自 127.0.0.1 的回复: 字节=32 时间<1ms TTL=200127.0.0.1 的 Ping 统计信息:数据包: 已发送 = 4,已接收 = 4,丢失 = 0 (0% 丢失),往返行程的估计时间(以毫秒为单位):最短 = 0ms,最长 = 0ms,平均 = 0ms0>>> os.system("cd C:\")File "<stdin>", line 1os.system("cd C:\")^SyntaxError: EOL while scanning string literal>>> os.system("cd C:/")0 ————————————————————————————-反馈值注:这里的“/”和在windows执行命令正好相反>>> os.getcwd()‘C:\\Users\\soft‘>>>
>>> os.system("dir")驱动器 C 中的卷没有标签。卷的序列号是 CE06-B2DDC:\Users\yangrf 的目录2016/01/11 18:37 <DIR> .2016/01/11 18:37 <DIR> ..2015/07/28 19:22 <DIR> .android2015/12/26 12:22 <DIR> .PyCharm502016/01/11 20:56 <DIR> ARIS902015/08/17 12:11 <DIR> CMB2015/07/29 08:46 <DIR> Contacts2015/10/29 21:25 <DIR> Desktop2016/01/24 15:21 <DIR> Documents2016/01/05 08:54 <DIR> Downloads2015/07/29 08:46 <DIR> Favorites2015/07/28 18:39 <DIR> Intel2015/07/29 08:46 <DIR> Links2015/07/29 08:46 <DIR> Music2016/01/08 12:13 <DIR> Pictures2015/07/28 17:47 <DIR> Roaming2015/07/29 08:46 <DIR> Saved Games2015/08/24 09:06 <DIR> Searches2015/07/29 08:46 <DIR> Videos0 个文件 0 字节19 个目录 66,753,159,168 可用字节0 注:上面的内容为执行过程,只有这个才是执行结果,因此在下面的a的结果为0>>> a = os.system("dir")驱动器 C 中的卷没有标签。卷的序列号是 CE06-B2DDC:\Users\yangrf 的目录2016/01/11 18:37 <DIR> .2016/01/11 18:37 <DIR> ..2015/07/28 19:22 <DIR> .android2015/12/26 12:22 <DIR> .PyCharm502016/01/11 20:56 <DIR> ARIS902015/08/17 12:11 <DIR> CMB2015/07/29 08:46 <DIR> Contacts2015/10/29 21:25 <DIR> Desktop2016/01/24 15:21 <DIR> Documents2016/01/05 08:54 <DIR> Downloads2015/07/29 08:46 <DIR> Favorites2015/07/28 18:39 <DIR> Intel2015/07/29 08:46 <DIR> Links2015/07/29 08:46 <DIR> Music2016/01/08 12:13 <DIR> Pictures2015/07/28 17:47 <DIR> Roaming2015/07/29 08:46 <DIR> Saved Games2015/08/24 09:06 <DIR> Searches2015/07/29 08:46 <DIR> Videos0 个文件 0 字节19 个目录 66,753,155,072 可用字节>>> a0>>> a = os.popen("dir").read()>>> print a驱动器 C 中的卷没有标签。卷的序列号是 CE06-B2DDC:\Users\yangrf 的目录2016/01/11 18:37 <DIR> .2016/01/11 18:37 <DIR> ..2015/07/28 19:22 <DIR> .android2015/12/26 12:22 <DIR> .PyCharm502016/01/11 20:56 <DIR> ARIS902015/08/17 12:11 <DIR> CMB2015/07/29 08:46 <DIR> Contacts2015/10/29 21:25 <DIR> Desktop2016/01/24 15:21 <DIR> Documents2016/01/05 08:54 <DIR> Downloads2015/07/29 08:46 <DIR> Favorites2015/07/28 18:39 <DIR> Intel2015/07/29 08:46 <DIR> Links2015/07/29 08:46 <DIR> Music2016/01/08 12:13 <DIR> Pictures2015/07/28 17:47 <DIR> Roaming2015/07/29 08:46 <DIR> Saved Games2015/08/24 09:06 <DIR> Searches2015/07/29 08:46 <DIR> Videos0 个文件 0 字节19 个目录 66,753,150,976 可用字节
>>> sys.path[‘‘, ‘C:\\Windows\\system32\\python27.zip‘, ‘C:\\Python27\\DLLs‘, ‘C:\\Python27\\lib‘, ‘C:\\Python27\\lib\\plat-win‘, ‘C:\\Python27\\lib\\lib-tk‘, ‘C:\\Python27‘, ‘C:\\Python27\\lib\\site-packages‘, ‘C:\\Python27\\lib\\site-packages\\win32‘, ‘C:\\Python27\\lib\\site-packages\\win32\\lib‘, ‘C:\\Python27\\lib\\site-packages\\Pythonwin‘]
从源src复制到dst中去。当然前提是目标地址是具备可写权限。抛出的异常信息为IOException. 如果当前的dst已存在的话就会被覆盖掉。
注意这里是文件,若文件已经存在,将直接进行覆盖,若文件不在一个目录下,需要使用绝对路径。
>>> shutil.copyfile(‘1.txt‘,‘D:/test4/2.txt‘)>>>
3.8.shutil.ignore_patterns(*patterns)
shutil.ignore_patterns(*patterns) 为copytree的辅助函数,提供glob功能,示例:
shutil.copytree(src, dst, symlinks=False, ignore=None)
递归的去拷贝文件
例如:copytree(source, destination, ignore=ignore_patterns(‘*.pyc‘, ‘tmp*‘))
3.9.shutil.rmtree(path[, ignore_errors[, onerror]])
递归的去删除文件
3.10.shutil.move(src, dst)
递归的去移动文件
3.11.shutil.make_archive(base_name, format[, root_dir[, base_dir[, verbose[, dry_run[, owner[, group[, logger]]]]]]])
创建压缩包并返回文件路径,例如:zip、tar
参数:
base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
如:www =>保存至当前路径,如:/Users/www =>保存至/Users/
format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
root_dir: 要压缩的文件夹路径(默认当前目录)
base_dir开始压缩的目录(默认当前目录)
owner: 用户,默认当前用户
group: 组,默认当前组
logger: 用于记录日志,通常是logging.Logger对象
>>> shutil.make_archive("test111","gztar",root_dir=‘D:/test1‘)‘D:\\test1\\test111.tar.gz‘>>>- 注:把D:/test1目录下的所有文件都压缩成一个压缩包,压缩包名字为test111
4.1.ZipFile模块import zipfile
# 压缩z = zipfile.ZipFile(‘test.zip‘, ‘w‘) 定义一个压缩文件 z.write(‘a.log‘) 添加里面压缩内容 z.write(‘data.data‘) 添加里面压缩内容 z.close() 完成压缩# 解压z = zipfile.ZipFile(‘test.zip‘, ‘r‘)z.extractall() 可设置解压地址 z.close()4.1.tarfile模块import tarfile# 压缩 tar = tarfile.open(‘test11.tar‘,‘w‘) tar.add(‘/Users/....../xxx.zip‘, arcname=‘xxx.zip‘) tar.add(‘/Users/....../yyy.zip‘, arcname=‘yyy.zip‘) tar.close() # 解压 tar = tarfile.open(‘test11.tar‘,‘r‘) tar.extractall() # 可设置解压地址 tar.close()5.json 和 pickle ,序列化import pickle,jsonpickle 只有python有,json是所有语言通用的。 使用“b”参数,进行二进制读写。pickle基本可以序列化列表、字典、元组、函数等,转换内容更多,而jsion仅能进行常用的内容转换Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
import pickle
data = {‘k1‘:123,‘k2‘,‘123‘}
p_str = pickle.dumps(data)
print (p_str)
pickle.dumps 将数据通过特殊的形式转换为只有python语言能识别的字符串。
with open(‘e:/test.txt‘,‘w‘) as ft:
pikcle.dump (data,fp)
pikcle.dump 将数据通过特殊的形式转换为只有python语言能识别的字符串。并写入文件。
json.dumps 将数据通过特殊的形式转换为所有程序语言都能认识的字符串
json.dump 将数据通过特殊的形式转换为所有程序语言都能认识的字符串,并写入文件。
load、loads 和dump、 dumps功能正好相反。
pikcle 和 json 的区别在于,pikcle能对python环境下任何格式文件存储到文件中,通过load/loads进行还原后仍是原有的格式。而json则只能对字符串等常见格式进行格式化存储,因此假若程序只在python环境下运行,使用pikcle最为合适,若需要与其他程序进行互通,则需要使用json,保障其他语言能读取。
dump多少次load就可以多少次,但读取必须按照dump的顺序读取
6.shelve 模块 是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式
可以一次写很多个文件,然后按照k进行选择性的读取,而和pickle区别在于,pickle虽然也能进行多个文件连续写,但是读的时候仅能进行顺序读取,不能选择性的读取。
dump多少次load就可以多少次,但读取必须按照dump的顺序读取
在shelve模块中,key必须为字符串,而值可以是python所支持的数据
import shelvet1 = [123]t2 = [‘test1‘,‘test2‘]t3 = {‘name‘:‘test‘,‘age‘:‘18‘}d = shelve.open(‘shelve_test‘) #打开一个文件- ########################将上面的数据写入shelve_test中################
d[‘t1‘] = t1d[‘t2‘] = t2d[‘t3‘] = t3d.close()###################################################################for i in d:print(i)- 获取结果如下:
- t2 t3 t1
- print(d[t1])
- 这时候就可以使用键值进行指定读取
print(dir(d))常用的方法:可以修改、删除、添加等等[‘_MutableMapping__marker‘, ‘__abstractmethods__‘, ‘__class__‘, ‘__contains__‘, ‘__del__‘, ‘__delattr__‘, ‘__delitem__‘, ‘__dict__‘, ‘__dir__‘, ‘__doc__‘, ‘__enter__‘, ‘__eq__‘, ‘__exit__‘, ‘__format__‘, ‘__ge__‘, ‘__getattribute__‘, ‘__getitem__‘, ‘__gt__‘, ‘__hash__‘, ‘__init__‘, ‘__iter__‘, ‘__le__‘, ‘__len__‘, ‘__lt__‘, ‘__module__‘, ‘__ne__‘, ‘__new__‘, ‘__reduce__‘, ‘__reduce_ex__‘, ‘__repr__‘, ‘__setattr__‘, ‘__setitem__‘, ‘__sizeof__‘, ‘__slots__‘, ‘__str__‘, ‘__subclasshook__‘, ‘__weakref__‘, ‘_abc_cache‘, ‘_abc_negative_cache‘, ‘_abc_negative_cache_version‘, ‘_abc_registry‘, ‘_protocol‘, ‘cache‘, ‘clear‘, ‘close‘, ‘dict‘, ‘get‘, ‘items‘, ‘keyencoding‘, ‘keys‘, ‘pop‘, ‘popitem‘, ‘setdefault‘, ‘sync‘, ‘update‘, ‘values‘, ‘writeback‘]
7.xml处理模块,xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多
例子:
默认XML文件<?xml version="1.0"?><test_xml><country name="soft"><test1 updated="yes">2</test1><test2 updated="yes">5</test2><year>2008</year><rank>30</rank><gdppc>1111</gdppc></country><country name="test2"><test2 updated="yes">5</test2><year>2011</year><gdppc>59900</gdppc><rank>61</rank></country></test_xml>增、删、改、查XML文件操作:
#!/usr/bin/env python# -*-coding:utf-8 -*-import xml.etree.ElementTree as ET #导入xml中的模块并定义个别名tree = ET.parse("xml_base.xml") #打开xml文件root = tree.getroot() #获取root节点print(root.tag) #打印xml的root节点名字- 执行结果:
- test_xml
#遍历xml文档for i in root:print(i.tag, i.attrib) #获取第一级节点名字for i2 in i:print(‘---->‘,i2.tag,i2.text) #获取第一级节点内容执行结果:country {‘name‘: ‘soft‘} ----> test1 2 ----> test2 5 ----> year 2008 ----> rank 30 ----> gdppc 1111 country {‘name‘: ‘test2‘} ----> test2 5 ----> year 2011 ----> gdppc 59900 ----> rank 61# 只遍历包括year的 节点for node in root.iter(‘year‘):print(node.tag,node.text)- 执行结果:
- year 2008 year 2011
#修改for node in root.iter(‘year‘):new_year = int(node.text) + 1 #修改‘year’的值node.text = str(new_year)node.set("updated","yes") #同时增加内容tree.write("xmltest.xml")# 修改完成后的结果:# 原来:<year>2008</year># 修改后:<year updated="yes">2009</year>#删除nodefor country in root.findall(‘country‘): #查找所有"country"的节点rank = int(country.find(‘rank‘).text) #获取rank的值if rank > 50: #若rank值大于50,进行删除操作。root.remove(country)tree.write(‘output.xml‘) #生成一个新的文件
#新建文件import xml.etree.ElementTree as ETnew_xml = ET.Element("test") #定义root节点名字name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"}) #定义一级节点名字及赋值age = ET.SubElement(name,"age",attrib={"checked":"no"}) #定义二级节点名字及赋值sex = ET.SubElement(name,"sex") 定义二级目录下键值并赋值sex.text = ‘33‘name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"})age = ET.SubElement(name2,"age")age.text = ‘19‘et = ET.ElementTree(new_xml) #生成文档对象et.write("test.xml", encoding="utf-8",xml_declaration=True)ET.dump(new_xml) #打印生成的格式
<?xml version=‘1.0‘ encoding=‘utf-8‘?><test><name enrolled="yes"><age checked="no" /><sex>33</sex></name><name enrolled="no"><age>19</age></name></test>
9.ConfigParser模块
用于生成和修改常见配置文档,当前模块的名称在 python 3.x 版本中变更为 configparser。
生成一个配置文件
import configparser #导入模块config = configparser.ConfigParser()config["DEFAULT"] = {‘Servername‘: ‘soft‘,‘port‘: ‘8888‘,‘defaultname‘: ‘9‘}config[‘soft.com‘] = {}config[‘soft.com‘][‘defaultdir‘] = ‘/usr/soft‘config[‘test.server.com‘] = {}topsecret = config[‘test.server.com‘]topsecret[‘Host Port‘] = ‘50022‘ # mutates the parsertopsecret[‘Forward‘] = ‘no‘ # same hereconfig[‘DEFAULT‘][‘ForwardX11‘] = ‘yes‘with open(‘example.ini‘, ‘w‘) as configfile:config.write(configfile)
生成格式如下:
[DEFAULT]defaultname = 9port = 8888servername = softforwardx11 = yes[soft.com]defaultdir = /usr/soft[test.server.com]host port = 50022forward = no
配置文件增删改查
import configparserconfig = configparser.ConfigParser()config.read(‘example.ini‘) #读取example.ini文件#########查询操作#####################
test = config.sections()print(test)执行结果:[‘soft.com‘, ‘test.server.com‘, ‘test1.server.com‘]#这里获取的文件没有[DEFAULT],因为[DEFAULT]为全局变量(这个名字是固定的),具体获取方式如下:test2 = config.defaults()print(test2)- 执行结果:
- OrderedDict([(‘defaultname‘, ‘9‘), (‘port‘, ‘8888‘), (‘servername‘, ‘soft‘), (‘forwardx11‘, ‘yes‘)])
print(‘bitbucket.org‘ in config)执行结果:Falseprint(‘soft.com‘ in config)- 执行结果:True
test3 = config.options(‘soft.com‘)print(‘test3‘,test3) #读取‘soft.com‘下面的所有文件,这个时候会把全局变量全部加入进入。- 执行结果:
- test3 [‘defaultdir‘, ‘defaultname‘, ‘port‘, ‘servername‘, ‘forwardx11‘]
test4 = config[‘soft.com‘][‘defaultdir‘]print(‘test4‘,test4) #读取‘soft.com‘下的‘defaultdir‘值执行结果:test4 /usr/softval = config.get(‘test.server.com‘,‘host port‘)print(val) #获得结果和上面一样- 执行结果:
- 50022
test5 = config.items(‘test.server.com‘) #以列表形式读取‘test.server.com‘下的所有内容print(‘test5‘,test5)执行结果:test5 [(‘defaultname‘, ‘9‘), (‘port‘, ‘8888‘), (‘servername‘, ‘soft‘), (‘forwardx11‘, ‘yes‘), (‘host port‘, ‘50022‘), (‘forward‘, ‘no‘)]- #########添加#####################
sec = config.has_section(‘test1.server.com‘) #判断值是否已经存在配置文件中sec = config.add_section(‘test1.server.com‘) #新添加一个键值config.write(open(‘example.ini‘, "w"))- #########修改#####################
config.set(‘test1.server.com‘,‘timeout‘,‘30‘) #在配置文件下添加一个键值config.write(open(‘example.ini‘, "w"))- #########键值删除#####################
config.remove_option(‘test1.server.com‘,‘timeout‘) #删除一个键值config.write(open(‘example.ini‘, "w"))#########整体值删除#####################sec = config.remove_section(‘timeout‘) #删除值,若不存在不会报错config.write(open(‘example.ini‘, "w"))
“Unicode-objects must be encoded before hashing”,意思是在进行md5哈希运算前,需要对数据进行编码。对于只要输入结果一致,使用同一算法加密后输出的结果是一致的。
import hashlib# ######## md5 ########m = hashlib.md5()m.update(b"Hello") #加密字符串,加密过程中,可以不断传入新的值进去m.update(b"It‘s me")print(m.digest()) #显示加密结果m.update(b"It‘s been a long time since last time we ...")- #假如不假如“b”会报“Unicode-objects must be encoded before hashing”错误。
print(m.digest()) #2进制格式hashprint(len(m.hexdigest())) #16进制格式hash- #可以使用以下方式对编码进行修改。
data = "Hello"m = hashlib.md5(data.encode("gb2312"))print(m.hexdigest())data = "你好"m = hashlib.md5(data.encode("gb2312"))print(m.hexdigest())
#只要输出的结果是一样,计算出的hash结果是一样的。# ######## sha1 ########hash = hashlib.sha1()hash.update(b‘admin‘)print(hash.hexdigest())# ######## sha256 ########hash = hashlib.sha256()hash.update(b‘admin‘)print(hash.hexdigest())# ######## sha384 ########hash = hashlib.sha384()hash.update(b‘admin‘)print(hash.hexdigest())# ######## sha512 ########hash = hashlib.sha512()hash.update(b‘admin‘)print(hash.hexdigest())python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密,更多的用于消息加密
import hmach = hmac.new(b‘wueiqi‘) #首先生成一个keyh.update(b‘hellword‘) #输入加密的数据print (h.hexdigest())11.Subprocess模块subprocess包中定义有数个创建子进程的函数,这些函数分别以不同的方式创建子进程,所以我们可以根据需要来从中选取一个使用。另外subprocess还提供了一些管理标准流(standard stream)和管道(pipe)的工具,从而在进程间使用文本通信。subprocess.call("df -h ",shell=True)subproceess返回结果为0为成功,否则报异常,若想获取还行过程结果获取执行结果方法:a = subprocess.Popen("df -h ",shell = True,stdout=subprocess.PIPE)stdout=subprocess.PIPE 为管道,若不添加是无法获取结果的a.stdout.read()
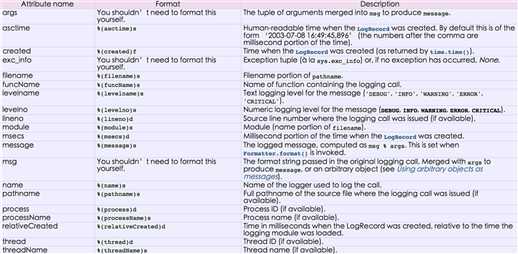
debug(), info(), warning(), error() and critical() 5个级别logging.getLogger(‘TEST-LOG‘) # 默认全局的level,全局优先级最高。
import subprocess,logginglogging.warning("password long")输出结果:WARNING:root:password long
import subprocess,logginglogging.basicConfig(filename="example.log",level=logging.INFO,format=‘%(asctime)s %(message)s‘, datefmt=‘%Y-%m-%d %H:%M:%S %p‘)#"filename"指定生成文件的名字,"level"指定存入的级别,"format"对于输出信息的格式要求(默认参数),"datefmt"默认格式要求。logging.debug(‘This message should go to the log file‘)logging.info(‘So should this‘)logging.warning(‘And this, too‘)输出结果:
2016-02-22 22:17:37 PM So should this2016-02-22 22:17:37 PM And this, too2016-02-22 22:17:37 PM is when this event was logged.格式要求:对于格式,有如下属性可是配置:
同时把log打印在屏幕和文件日志里
特别注意:logging.getLogger中设置的为全局配置,高于 logging.StreamHandler和logging.FileHandler中的设置,当 logging.StreamHandler和logging.FileHandler低于logging.getLogger时显示和记录logging.StreamHandler和logging.FileHandler内容,当logging.StreamHandler和logging.FileHandler高于logging.getLogger时,以logging.getLogger为准。
import logging#create loggerlogger = logging.getLogger(‘TEST-LOG‘) #设置默认全局的level,全局优先级最高,定义个名字为"TEST-LOG"logger.setLevel(logging.DEBUG) #设置默认级别# create console handler and set level to debugch = logging.StreamHandler() #定义一个输出到屏幕的loggingch.setLevel(logging.INFO) #定义输出级别# create file handler and set level to warningfh = logging.FileHandler("access.log") #定义一个输出到文件中的loggingfh.setLevel(logging.WARNING) #定义输出级别# create formatterformatter = logging.Formatter(‘%(asctime)s - %(name)s - %(levelname)s - %(message)s‘) #定义给一个格式# add formatter to ch and fhch.setFormatter(formatter) #导入格式fh.setFormatter(formatter) #导入格式# add ch and fh to loggerlogger.addHandler(ch) #在ch头部加入logger.addHandler(fh) #在fh头部加入# ‘application‘ codelogger.debug(‘debug message‘)logger.info(‘info message‘)logger.warn(‘warn message‘)logger.error(‘error message‘)logger.critical(‘critical message‘)
标签:
原文地址:http://www.cnblogs.com/worter991/p/5219899.html