标签:
CAP原则又称CAP定理,指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。
CAP原则是NOSQL数据库的基石。Consistency(一致性)。 Availability(可用性)。Partition tolerance(分区容错性)。
It states, that though its desirable to have Consistency, High-Availability and Partition-tolerance in every system, unfortunately no system can achieve all three at the same time.
在分布式系统的设计中,没有一种设计可以同时满足一致性,可用性,分区容错性 3个特性
注意:不要将弱一致性,最终一致性放到CAP理论里混为一谈(混淆概念的坑真多)
弱一致性,最终一致性 你可以认为和CAP的C一点关系也没有,因为CAP的C是更新操作完成后,任何节点看到的数据完全一致, 弱一致性。最终一致性本身和CAP的C一致性是违背的,所以你可以看到那些谎称自己系统同时具备CAP 3个特性是多么的可笑,可能国内更多的场景是:一个开放人员一旦走上讲台演讲,就立马转变为了营销人员,连最基本的理念也不要了。
这里有一篇标题很大的文章 cap-twelve-years-later-how-the-rules-have-changed ,实际上本文的changed更多的是在思考方式上,而本身CAP理论是没有changed的
我们来看一个简单的问题, 一个DB服务 搭建在两个机房(北京,广州),两个DB实例同时提供写入和读取
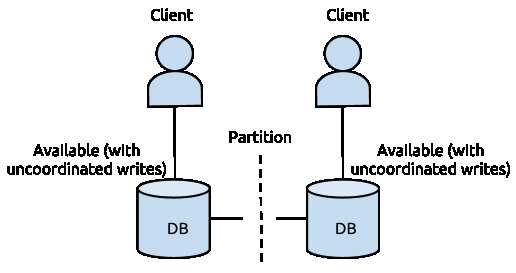
1. 假设DB的更新操作是同时写北京和广州的DB都成功才返回成功
在没有出现网络故障的时候,满足CA原则,C 即我的任何一个写入,更新操作成功并返回客户端完成后,分布式的所有节点在同一时间的数据完全一致, A 即我的读写操作都能够成功,但是当出现网络故障时,我不能同时保证CA,即P条件无法满足
2. 假设DB的更新操作是只写本地机房成功就返回,通过binlog/oplog回放方式同步至侧边机房
这种操作保证了在出现网络故障时,双边机房都是可以提供服务的,且读写操作都能成功,意味着他满足了AP ,但是它不满足C,因为更新操作返回成功后,双边机房的DB看到的数据会存在短暂不一致,且在网络故障时,不一致的时间差会很大(仅能保证最终一致性)
3. 假设DB的更新操作是同时写北京和广州的DB都成功才返回成功且网络故障时提供降级服务
降级服务,如停止写入,只提供读取功能,这样能保证数据是一致的,且网络故障时能提供服务,满足CP原则,但是他无法满足可用性原则
通过上面的例子,我们得知,我们永远无法同时得到CAP这3个特性,那么我们怎么来权衡选择呢?
选择的关键点取决于业务场景
对于大多数互联网应用来说(如网易门户),因为机器数量庞大,部署节点分散,网络故障是常态,可用性是必须需要保证的,所以只有设置一致性来保证服务的AP,通常常见的高可用服务吹嘘5个9 6个9服务SLA稳定性就本都是放弃C选择AP
对于需要确保强一致性的场景,如银行,通常会权衡CA和CP模型,CA模型网络故障时完全不可用,CP模型具备部分可用性,实际的选择需要通过业务场景来权衡(并不是所有情况CP都好于CA,只能查看信息不能更新信息有时候从产品层面还不如直接拒绝服务)
BASE(Basically Available, Soft State, Eventual Consistency 基本可用、软状态、最终一致性) 对CAP AP理论的延伸, Redis等众多系统构建与这个理论之上
ACID 传统数据库常用的设计理念, ACID和BASE代表了两种截然相反的设计哲学,分处一致性-可用性分布图谱的两极。
标签:
原文地址:http://www.cnblogs.com/duanxz/p/5229352.html