标签:
你可以创建一个递归神经网络一个字符一个字符地学习语言特征。但是这个结果模型与为同样目的设计的马尔可夫链有什么不同呢?本文用R实现了一个字符-字符的马尔可夫链来一探究竟。
Andrej Karpathy的文章《递归神经网络不可思议的有效性》(The Unreasonable Effectiveness of Recurrent Neural Networks)在去年名噪一时。其基本假设是你可以创建一个递归神经网络一个字符一个字符地学习语言特征。但是这个结果模型与为同样目的设计的马尔可夫链有什么不同呢?我用R实现了一个字符-字符的马尔可夫链来一探究竟。
来源:@shakespeare
首先,我们来玩模仿游戏的一个变种游戏,使用Karpathy的微小莎士比亚数据集(tinyshakespeare dataset)生成的文本。哪些片段是来自于RNN,哪些又是来自于马尔可夫链?可以注意到Karpathy的例子来自于全集,而我的马尔可夫链来自于微小莎士比亚集(大约是前者的四分之一),因为我比较懒。
DUKE VINCENTIO:
Well, your wit is in the care of side and that.
FRIAR LAURENCE:
Or walk liest;
And the ears.
And hell!
In self.
PETRUCHIO:
Persuading to our the enemy, even woman, I‘ll afford show‘d and speaking of
England all out what least. Be satisfied! Now, sir.
Second Lord:
They would be ruled after this chamber, and
my fair nues begun out of the fact, to be conveyed,
Whose noble souls I‘ll have the heart of the wars.
如果你分辨不出,也不必苛求自己。不起眼的马尔可夫链在学习拼写(奥尔德)英语单词方面与最先进的RNN同样有效。这怎么可能?让我们看看这些系统如何工作的。两者都将字符序列作为输入,并试图“预测”出序列中下一个字符。RNN是这样实现的,调整权值向量,得到适合指定响应的输出向量。隐藏层在训练集上保持状态。最后,对于每个可能输出字符都计算出一个置信度值,它用来预测下一个字符。
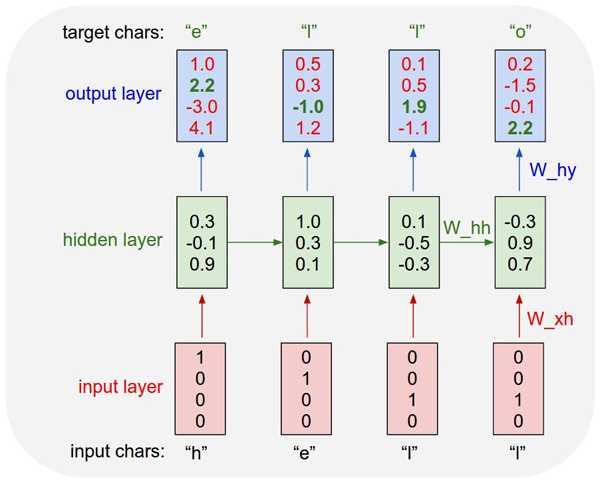
来源:Andrej Karpathy
在另一方面,训练马尔可夫链只是简单地构造一个概率密度函数,逐步跨越今后可能的状态。这意味着所得到的概率密度函数与RNN的输出置信度不会有太大区别。下面是概率密度函数跨越字符“walk”的例子:
> table(chain[[‘walk ‘]]) / length(chain[[‘walk ‘]])
a b i l m o u
0.4 0.1 0.1 0.1 0.1 0.1 0.1
这告诉我们,有40%的可能字符序列“walk”后跟着字母“a”。在生成文本时,我们可以把这个作为预测值,或者使用概率密度函数来支配采样。我选择后者因为它更有趣。
但是在马尔可夫链中状态如何捕获呢?因为马尔可夫链是无状态的。很简单:我们使用一个字符序列而不是单独字符作为输入。在这篇文章中,我使用了长度为5的序列,那么马尔可夫链基于前面5个状态来选择下一状态。这是在作弊吗?还是这就是RNN中隐藏层的作用吗?
虽然RNN机制与马尔可夫链大不相同,但基本概念非常相似。RNN和深度学习可能在这个领域非常酷,但不要忽视简单的东西。你可以从简单模型中学到许多知识,它们一般都经受住了时间的考验,很好理解并易于解释。
注:我没有使用包来训练和运行马尔可夫链,因为它低于20 LOC。这段代码的一个版本将会出现在我即将出版的一本书中
标签:
原文地址:http://www.cnblogs.com/itxxsd/p/5230441.html