标签:blog http re c html 代码 div 算法
折半查找也就是二叉查找,其查找时间复杂度为O(logn),比顺序查找的效率高得多,唯一的要求就是待查表已经有序。
1、等值折半查找比较简单,算法如下:

def binarySearch(data,value):
low = 0
high = len(data) - 1
while low <= high:
middle = (high-low) / 2 + low#这个处理可以防止整数相加溢出
if data[middle] == value:
return middle #找到,返回下标
if data[middle] < value:
low = middle + 1
else:
high = middle - 1
return -1#没找到返回-1
等值折半查找需要注意几个地方:
1)循环条件是low <= high,不是low < high,少了=符号,会造成有些实际在data中存在的value找不到而返回-1。如下图在表中查找4

查找过程如下:

经过两次查找后,low==high 等于1,于是跳出循环,而返回-1,事实上应该返回1,因为data[1]==4
2)low = middle + 1,而不是low = middle,如果写成low = middle会造成死循环。作为示例,我们在上面的data表中查找8,
查找过程如下:
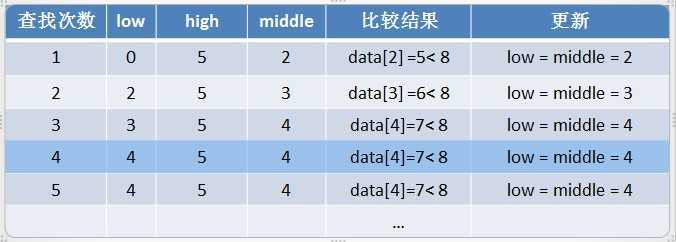
可以看到从第4次查找后,就陷入了死循环,low始终等于4。
3)high = middle - 1,这里跟2)类似,写成high = middle一样会导致死循环,你可以试着在data表中查找3看看。
4)middle = (high-low) / 2 + low,为什么不直接写成middle = (high + low) / 2,试想一下,如果high和low都是int类型,high=30000,low=20000,high+low=50000已经超出int类型的范围,你再除以2,得到的middle已经不是你想要的数了,而middle = (high-low) / 2 + low可以很好的处理这个潜在 溢出错误。
2、非等值折半查找
很多时候我们需要在顺序表中进行范围查找,如在data中找小于某个值的数,data[index]<value,这与等值折半查找不同,在非等值查找时,即使在有序表data中没有找到值value仍然可能返回一个下标,而不是-1,如在前面的data中查找<4.5,我们应该让折半查找返回1,因为所有i <= 1 满足data[i] < 4.5,尽管4.5不在data中。
事实上非等值折半查找只需要在等值折半查找上添加几个判断条件,便可以实现,以下是python算法:
1 #折半范围查找 2 #若查找成功,返回最大的下标,满足data[i]<value或data[i]<=value 3 #若不存在指定的范围,则返回-1 4 def binarySearch(data,compare,value): 5 length = len(data) 6 low = 0 7 high = length - 1 8 while low <= high:#等值折半查找value 9 middle = (high-low) / 2 + low 10 if data[middle] == value: 11 break#找到value,跳出循环 12 if data[middle] < value: 13 low = middle + 1 14 else: 15 high = middle - 1 16 if low <= high:#value在data中 17 if compare == ‘<=‘ or compare == ‘>=‘ or compare == ‘=‘:#包含‘=’的比较,直接返回值value的下标 18 return middle 19 elif compare == ‘<‘:#‘<‘需要返回前面一个下标,有可能为-1 20 return middle - 1 21 else: 22 #(compare == ‘>‘) ‘>‘需要返回后面一个下标 23 if middle == length -1:#middle等于有序表长度时,表示不存在data[i]>value,返回-1 24 return -1 25 else: 26 return middle + 1#返回后面一个下标 27 else:#value不在data中,此时high = low - 1,如果查找成功,value 在(high,low)的开区间中 28 if compare == ‘=‘: 29 return -1#等值查找,返回-1,查找失败 30 elif compare == ‘<‘ or compare == ‘<=‘:#返回区间左边端点,有可能返回-1 31 return high 32 else: 33 #compare == ‘>‘ or compare == ‘>=‘ 34 if low >= length:#不存在区间,返回-1 35 return -1 36 else: 37 return low#返回区间右端点
上面的算法实现了一个通用的不等值折半查找,首先进行等值折半查找找到value的位置或者区间,如在上面的表中查找<4.5,等值折半查找的区间为(high,low)= (1,2),所有找到的index为1,即返回值为1。
由于value是否在data中影响"<=",">="和"="的查找结果,所有分情况处理。
调用:
1 data = [5,6,7,8,9,10,11,12,13,14,15,16] 2 print binarySearch(data,‘>‘,11) 3 print binarySearch(data,‘<=‘,5)
[转载]
http://www.cnblogs.com/fengfenggirl/archive/2013/06/14/3136816.html
标签:blog http re c html 代码 div 算法
原文地址:http://www.cnblogs.com/renzimu/p/3868581.html