标签:
【转】http://www.jb51.net/article/29693.htm
在《数据库原理》里面,对聚簇索引的解释是:聚簇索引的顺序就是数据的物理存储顺序,而对非聚簇索引的解释是:索引顺序与数据物理排列顺序无关。正式因为如此,所以一个表最多只能有一个聚簇索引。
不过这个定义太抽象了。在SQL Server中,索引是通过二叉树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。如下图:
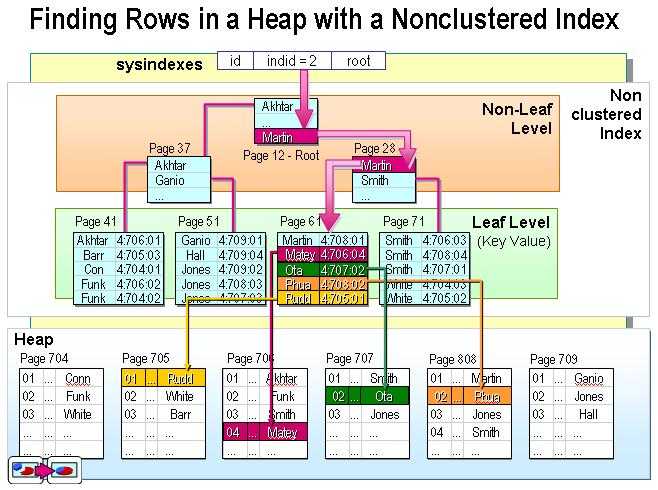
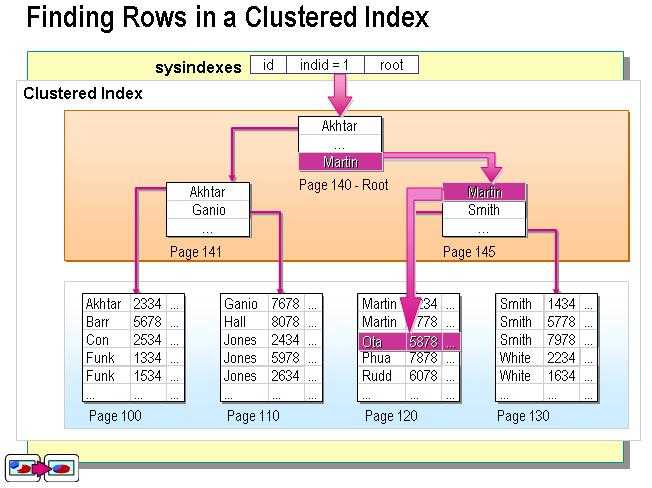
一、索引块与数据块的区别
大家都知道,索引可以提高检索效率,因为它的二叉树结构以及占用空间小,所以访问速度块。
让我们来算一道数学题:如果表中的一条记录在磁盘上占用 1000字节的话,我们对其中10字节的一个字段建立索引,那么该记录对应的索引块的大小只有10字节。我们知道,SQL Server的最小空间分配单元是“页(Page)”,一个页在磁盘上占用8K空间,那么这一个页可以存储上述记录8条,但可以存储索引800条。现在我 们要从一个有8000条记录的表中检索符合某个条件的记录,如果没有索引的话,我们可能需要遍历8000条×1000字节/8K字节=1000个页面才能 够找到结果。如果在检索字段上有上述索引的话,那么我们可以在8000条×10字节/8K字节=10个页面中就检索到满足条件的索引块,然后根据索引块上 的指针逐一找到结果数据块,这样IO访问量要少的多。
二、聚簇索引与非聚簇索引的区别
聚簇索引的叶节点就是数据节点,而非聚簇索引的页节点仍然是索引检点,并保留一个链接指向对应数据块。
标签:
原文地址:http://www.cnblogs.com/plxx/p/5241525.html