标签:des style blog http os strong io width
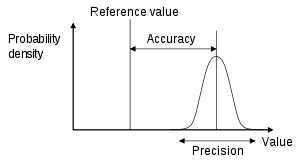 :Accuracy is the proximity of measurement results to the true value; precision, the repeatability, or reproducibility of the measurement
:Accuracy is the proximity of measurement results to the true value; precision, the repeatability, or reproducibility of the measurement
In the fields of science, engineering, industry, and statistics, the accuracy of ameasurement system is the degree of closeness of measurements of a quantity to that quantity‘s actual (true) value.[1] The precision of a measurement system, related to reproducibility and repeatability, is the degree to which repeated measurements under unchanged conditions show the same results.[1][2] Although the two words precision and accuracy can be synonymous in colloquial use, they are deliberately contrasted in the context of the scientific method.
A measurement system can be accurate but not precise, precise but not accurate, neither, or both. For example, if an experiment contains a systematic error, then increasing the sample size generally increases precision but does not improve accuracy. The result would be a consistent yet inaccurate string of results from the flawed experiment. Eliminating the systematic error improves accuracy but does not change precision.
A measurement system is considered valid if it is both accurate and precise. Related terms include bias (non-random or directed effects caused by a factor or factors unrelated to the independent variable) and error (random variability).
The terminology is also applied to indirect measurements—that is, values obtained by a computational procedure from observed data.
In addition to accuracy and precision, measurements may also have a measurement resolution, which is the smallest change in the underlying physical quantity that produces a response in the measurement.
In numerical analysis, accuracy is also the nearness of a calculation to the true value; while precision is the resolution of the representation, typically defined by the number of decimal or binary digits.
Ideally a measurement device is both accurate and precise, with measurements all close to and tightly clustered around the true value. The accuracy and precision of a measurement process is usually established by repeatedly measuring some traceable reference standard. Such standards are defined in the International System of Units (abbreviated SI from French: Système international d‘unités) and maintained by national standards organizations such as the National Institute of Standards and Technology in the United States.
This also applies when measurements are repeated and averaged. In that case, the term standard error is properly applied: the precision of the average is equal to the known standard deviation of the process divided by the square root of the number of measurements averaged. Further, the central limit theorem shows that the probability distribution of the averaged measurements will be closer to a normal distribution than that of individual measurements.
With regard to accuracy we can distinguish:
A common convention in science and engineering is to express accuracy and/or precision implicitly by means of significant figures. Here, when not explicitly stated, the margin of error is understood to be one-half the value of the last significant place. For instance, a recording of 843.6 m, or 843.0 m, or 800.0 m would imply a margin of 0.05 m (the last significant place is the tenths place), while a recording of 8,436 m would imply a margin of error of 0.5 m (the last significant digits are the units).
A reading of 8,000 m, with trailing zeroes and no decimal point, is ambiguous; the trailing zeroes may or may not be intended as significant figures. To avoid this ambiguity, the number could be represented in scientific notation: 8.0 × 103 m indicates that the first zero is significant (hence a margin of 50 m) while 8.000 × 103 m indicates that all three zeroes are significant, giving a margin of 0.5 m. Similarly, it is possible to use a multiple of the basic measurement unit: 8.0 km is equivalent to 8.0 × 103 m. In fact, it indicates a margin of 0.05 km (50 m). However, reliance on this convention can lead to false precision errors when accepting data from sources that do not obey it.
Precision is sometimes stratified into:
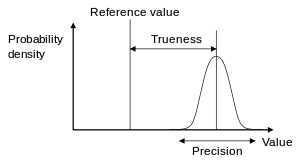 :According to ISO 5725-1, Accuracy consists of Trueness (proximity of measurement results to the true value) and Precision (repeatability or reproducibility of the measurement)
:According to ISO 5725-1, Accuracy consists of Trueness (proximity of measurement results to the true value) and Precision (repeatability or reproducibility of the measurement)
A shift in the meaning of these terms appeared with the publication of the ISO 5725 series of standards, which is also reflected in the 2008 issue of the "BIPM International Vocabulary of Metrology" (VIM), items 2.13 and 2.14. [1]
According to ISO 5725-1,[3] the terms trueness and precision are both used to describe the accuracy of a measurement. Trueness refers to the closeness of the mean of the measurement results to the actual (true) value and precision refers to the closeness of agreement within individual results. Therefore, according to the ISO standard, the term "accuracy" refers to both trueness and precision.
ISO 5725-1 and VIM also avoid the use of the term "bias", previously specified in BS 5497-1,[4] because it has different connotations outside the fields of science and engineering, as in medicine and law
| Accuracy according to BIPM and ISO 5725 | ||||
|---|---|---|---|---|
|
Accuracy is also used as a statistical measure of how well a binary classification test correctly identifies or excludes a condition.
| Condition (as determined by "Gold standard") |
|||||
| Total population | Condition positive | Condition negative | Prevalence = Σ Condition positive Σ Total population
|
||
| Test outcome |
Test outcome positive |
True positive | False positive (Type I error) |
Positive predictive value(PPV, Precision) = Σ True positive Σ Test outcome positive
|
False discovery rate (FDR) = Σ False positive Σ Test outcome positive
|
| Test outcome negative |
False negative (Type II error) |
True negative | False omission rate (FOR) = Σ False negative Σ Test outcome negative
|
Negative predictive value(NPV) = Σ True negative Σ Test outcome negative
|
|
| Positive likelihood ratio (LR+) = TPR/FPR |
True positive rate (TPR,Sensitivity, Recall) = Σ True positive Σ Condition positive
|
False positive rate (FPR,Fall-out) = Σ False positive Σ Condition negative
|
Accuracy (ACC) = Σ True positive + Σ True negative Σ Total population
|
||
| Negative likelihood ratio(LR−) = FNR/TNR |
False negative rate (FNR) = |
True negative rate (TNR,Specificity, SPC) = Σ True negative Σ Condition negative
|
|||
| Diagnostic odds ratio (DOR) = LR+/LR− |
|||||
That is, the accuracy is the proportion of true results (both true positives and true negatives) in the population. To make the context clear by the semantics, it is often referred to as the "Rand Accuracy". It is a parameter of the test.
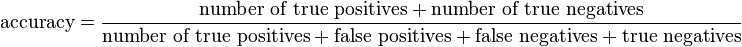
On the other hand, precision or positive predictive value is defined as the proportion of the true positives against all the positive results (both true positives and false positives)
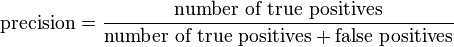
An accuracy of 100% means that the measured values are exactly the same as the given values.
Also see Sensitivity and specificity.
Accuracy may be determined from Sensitivity and Specificity, provided Prevalence is known, using the equation:
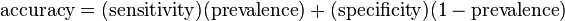
The accuracy paradox for predictive analytics states that predictive models with a given level of accuracy may have greater predictive power than models with higher accuracy. It may be better to avoid the accuracy metric in favor of other metrics such as precision and recall.[citation needed] In situations where the minority class is more important, F-measure may be more appropriate, especially in situations with very skewed class imbalance.
Another useful performance measure is the balanced accuracy which avoids inflated performance estimates on imbalanced datasets. It is defined as the arithmetic mean of sensitivity and specificity, or the average accuracy obtained on either class:
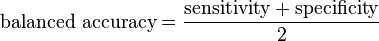
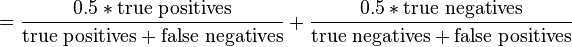
If the classifier performs equally well on either class, this term reduces to the conventional accuracy (i.e., the number of correct predictions divided by the total number of predictions). In contrast, if the conventional accuracy is above chance only because the classifier takes advantage of an imbalanced test set, then the balanced accuracy, as appropriate, will drop to chance.[5] A closely related chance corrected measure is:
A direct approach to debiasing and renormalizing Accuracy is Cohen‘s kappa, whilst Informedness has been shown to be a Kappa-family debiased renormalization of Recall.[7] Informedness and Kappa have the advantage that chance level is defined to be 0, and they have the form of a probability. Informedness has the stronger property that it is the probability that an informed decision is made (rather than a guess), when positive. When negative this is still true for the absolutely value of Informedness, but the information has been used to force an incorrect response.[6]
In psychometrics and psychophysics, the term accuracy is interchangeably used with validity and constant error. Precision is a synonym forreliability and variable error. The validity of a measurement instrument or psychological test is established through experiment or correlation with behavior. Reliability is established with a variety of statistical techniques, classically through an internal consistency test like Cronbach‘s alpha to ensure sets of related questions have related responses, and then comparison of those related question between reference and target population.
In logic simulation, a common mistake in evaluation of accurate models is to compare a logic simulation model to a transistor circuit simulation model. This is a comparison of differences in precision, not accuracy. Precision is measured with respect to detail and accuracy is measured with respect to reality.[8][9]
Further information: Precision and recallThe concepts of accuracy and precision have also been studied in the context of data bases, information systems and their sociotechnical context. The necessary extension of these two concepts on the basis of theory of science suggests that they (as well as data quality andinformation quality) should be centered on accuracy defined as the closeness to the true value seen as the degree of agreement of readings or of calculated values of one same conceived entity, measured or calculated by different methods, in the context of maximum possible disagreement.[10]
Accuracy and precision,布布扣,bubuko.com
标签:des style blog http os strong io width
原文地址:http://www.cnblogs.com/liulunyang/p/3868912.html


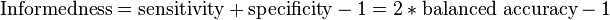 [6]
[6]