标签:
见:http://r.photo.store.qq.com/psb?/V12VvuOZ2vxbmG/M2gzPWfnBLS8buBT*16Y2xm9QkAAp8TmePOlIPC1MlM!/r/dFMAAAAAAAAA
流程:
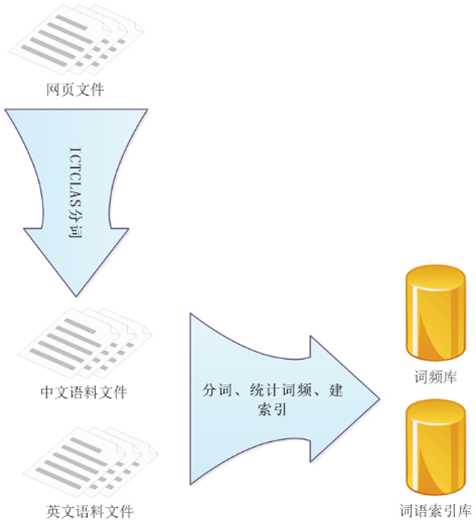
项目包:

主要流程:
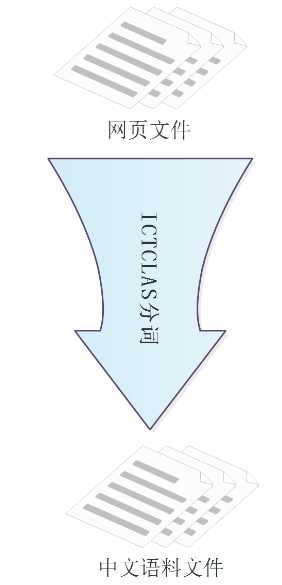
中科院分词系统 ICTCLAS 的使用,例子:
杭州市长春药店。 -》 杭州市/ns 长春/nz 药店/n 。

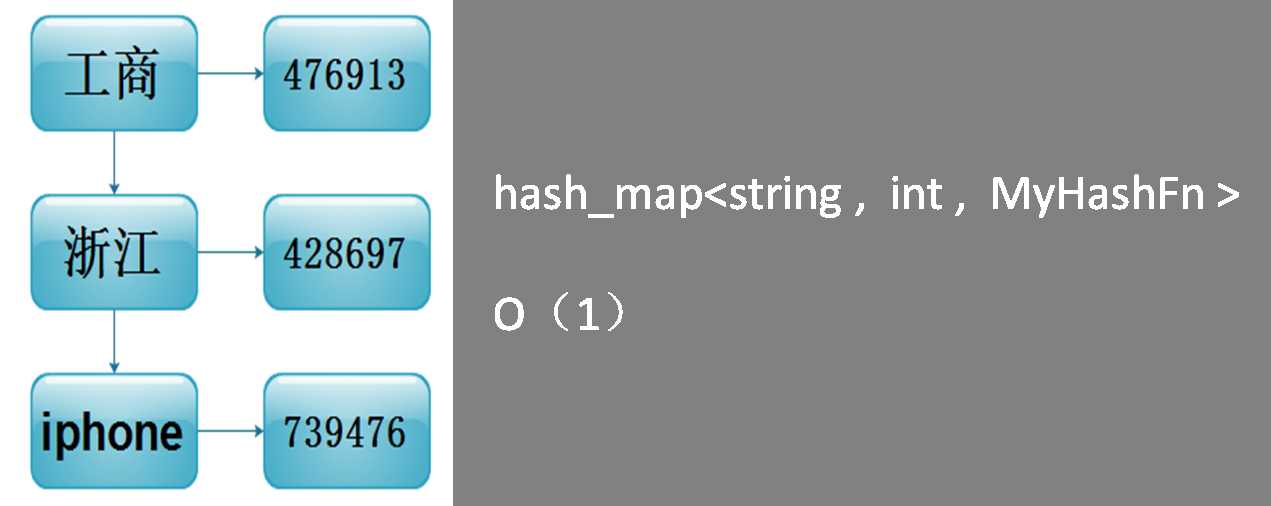
数据结构:
1 hash_map<string , int , MyHashFn >
例子:

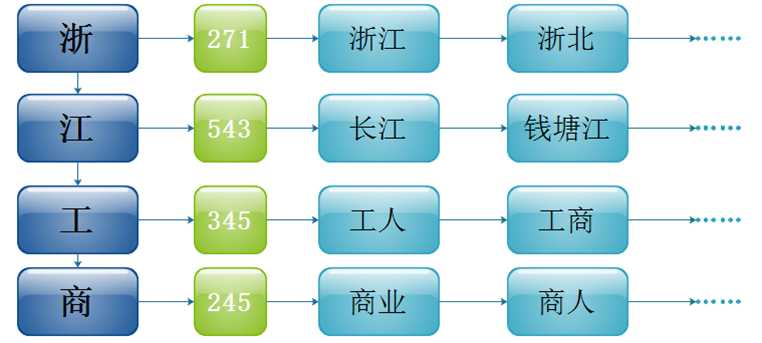
数据结构:
1 hash_map<string , set<string> , MyHashFn >
例子:
截取一个汉字,UTF-8可根据汉字的第一个字节移位推出长度
1字节 0xxxxxxx
2字节 110xxxxx 10xxxxxx
3字节 1110xxxx 10xxxxxx 10xxxxxx
4字节 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
1 if(word[i] & (1 << 4)) 2 key = word.substr(i, 4); 3 else if(word[i] & (1 << 5)) 4 key = word.substr(i, 3); 5 else if(word[i] & (1 << 6)) 6 key = word.substr(i, 2); 7 else 8 key = word.substr(i, 1);
流程:

项目包:


网页记录:
一行一条网页记录( string )
网页记录格式:
<doc><docid>网页号</docid>
<docurl>网页URL</docurl>
<doctitle>网页标题</doctitle>
<doccontent>网页内容</doccontent></doc>
数据结构:
1 struct Page 2 { 3 int ID; 4 string url,title,content; 5 };
1 hash_map< int , Page>
例子:

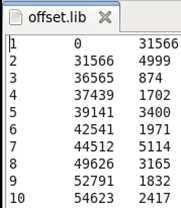
偏移记录:
一行一条偏移记录
偏移记录格式:
Page_ID 偏移量 本页大小
数据结构:
1 hash_map<int, std::pair<int, int> >
例子:
流程:
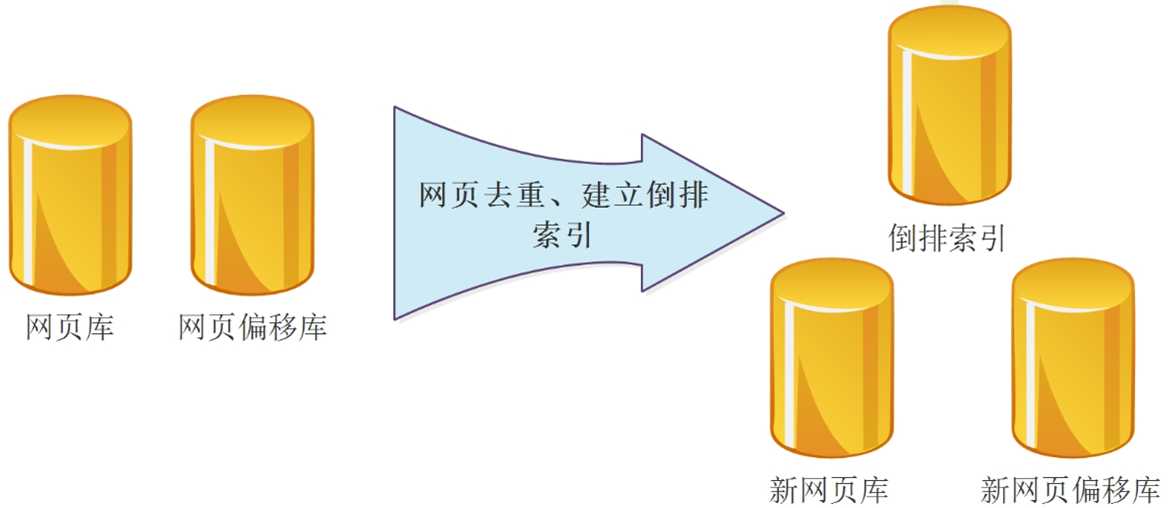
项目包:

Top-K 算法:

索引:
一行一条索引
索引格式:
词语 Page_ID 词频 权值 Page_ID 词频 权值 ……
数据结构:
1 hash_map<std::string, std::set<std::pair<int, double> >, MyHashFn>
例子:

权值的计算:
![]()
IDF反映了一个特征词在整个文档集合中的情况,出现的愈多IDF值越低,这个词区分不同文档的能力越差。
大量实验表明使用以下公式效果更好:
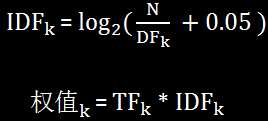
向量空间模型:
若词语W在包含100个词语的A网页中出现了50次,在包含1000个词语的B网页出现了100次,显然A中W的权值应该更大,但是计算结果却相反。因此,应该对权值进行标准化:

1 hash_map< int , Page>
1 hash_map<int, std::pair<int, int> >
1 hash_map<std::string, std::set<std::pair<int, double> >, MyHashFn>
1 map<string , int>
1 map<string , set<string>>
1 hash_map<std::string, std::string, MyHashFn>
1 class Task 2 { 3 public: 4 int fd; //Socket描述符 5 Task *next; //下一个任务 6 };
1 vector<Task>
指两个字串之间,由一个转成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
例子:
计算X字符串 与 Y字符串 的 编辑距离
dp[i][j] 为 X串的前i个字符 和 Y串的前j个字符 的编辑距离
1 if(X [i - 1] == Y[j - 1]) 2 dp[i][j] = dp[i - 1][j - 1]; //最后字符相同 3 else 4 { 5 int t1 = dp[i - 1][j]; // 删除X第i个字符 6 t1 = t1 < dp[i][j - 1] ? t1 : dp[i][j - 1]; //删除Y第j个字符 7 t1 = t1 < dp[i - 1][j - 1] ? t1 : dp[i - 1][j - 1];//最后字符改相同 8 dp[i][j] = t1 + 1; 9 }
由于需要进行汉语的编辑距离计算,这里的char转变为string,string转变为vector<string>。
ICTCLAS分词系统进行分词后的结果可能导致错误,例如:
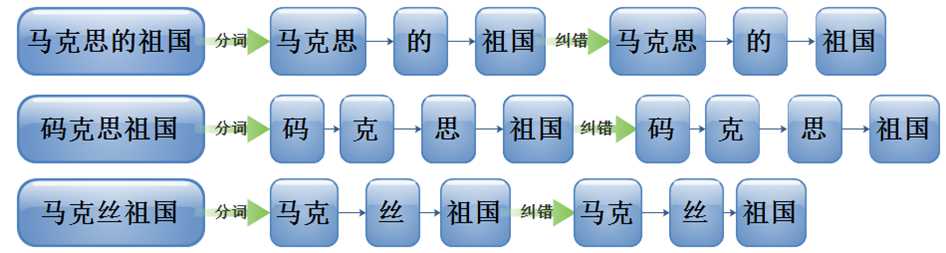
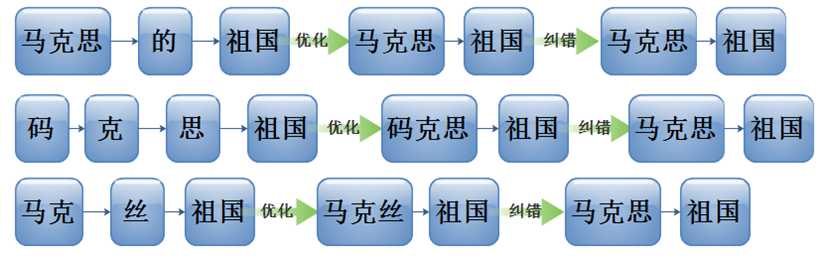
1、对分词结果去停用词,如“的”“了”“呢”
2、简单的错别字分词优化算法
(1)当出现连续的单个汉字时,将其合并成一个词语
(2)当出现不连续单个汉字,且不是第一个字时,把 它并入左边词语
优化结果:
将查询语句的特征词的权值组成向量 a
网页中对应的特征词的权值组成向量 b
查询语句与该网页的Cosine相似度:

1 hash_map<string , string , MyHashFn > //纠错前,纠错后
1 map< set<string> ,vector<pair<int, vector<double> > > > // 关键词集合,查询结果
标签:
原文地址:http://www.cnblogs.com/xiaoyesoso/p/5246536.html