标签:
在数据挖掘过程中,高维数据是非常棘手的研究对象。特别是在文本挖掘、图像处理和基因数据分析中,维度过高使很多学习器无法工作或效率降低,所以降维也是数据预处理过程的一项必要任务。降维大致有两大类别,一类是从原始维度中提取新的维度,例如主成分分析或因子分析,再或者是奇异值分解或是多维标度分析。另一类是从原始维度中选择一些子集,即称为特征选择(Feature Selection),或者叫作最佳子集选择。特征选择本质上继承了Occam‘s razor的思想,从一组特征中选出一些最有效的特征,使构造出来的模型更好。
进行特征选择的好处在于:
特征选择有三种基本的方法:
嵌入(embed):学习算法中本来就包含有特征选择的过程,例如决策树一类的分类器,它们在决定分枝点时就会选择最有效的特征来对数据进行划分。但这种方法是在局部空间中进行优选,效果相对有限。
封装(Wrapper): 特征选择过程与训练过程整合在一起,以模型的预测能力作为衡量特征子集的选择标准,例如分类精度,有时也可加入复杂度惩罚因子。多元线性回归中的前向搜索和后向搜索可以说是封装方法的一种简单实现。不同的学习算法要搭配不同的封装方法,如果是线性分类器,可以采用之前博文谈到的LASSO方法(glmnet包)。如果是非线性分类器,如树模型则可以采用随机森林封装(RRF包)。封装法可以选择出高质量的子集,但速度会比较慢。
过滤(Filter): 特征选择过程独立于训练过程,以分析特征子集内部特点来预先筛选,与学习器的选择无关。过滤器的评价函数通常包括了相关性、距离、信息增益等。在数据预处理过程中删除那些取值为常数的特征就是过滤方法的一种。过滤法速度快但有可能删除有用的特征。
在实务中进行特征选择可以先借由专家知识来初步筛选,再用过滤法快速筛选无关变量,最后采用封装法得到最优子集和模型结果。R语言中的caret包就提供了过滤和封装两种方法来进行特征选择。下面则是一个简单的示范:
# 加载扩展包和数据集mdrr,得到自变量集合mdrrDescr和因变量mdrrClass
library(caret) data(mdrr) # 先删去近似于常量的变量 zerovar <- nearZeroVar(mdrrDescr) newdata1 <- mdrrDescr[,-zerovar] # 再删去相关度过高的自变量 descrCorr <- cor(newdata1) highCorr <- findCorrelation(descrCorr, 0.90) newdata2 <- newdata1[, -highCorr] # 数据预处理步骤(标准化,缺失值处理) Process <- preProcess(newdata2)
newdata3 <- predict(Process, newdata2) # 用sbf函数实施过滤方法,这里是用随机森林来评价变量的重要性
data.filter <- sbf(newdata3,mdrrClass, sbfControl = sbfControl(functions=rfSBF, verbose=F, method=‘cv‘)) # 根据上面的过滤器筛选出67个变量
x <- newdata3[data.filter$optVariables] # 再用rfe函数实施封装方法,建立的模型仍是随机森林
profile <- rfe(x,mdrrClass, sizes = c(10,20,30,50,60), rfeControl = rfeControl(functions=rfFuncs ,method=‘cv‘)) # 将结果绘图,发现20-30个变量的模型精度最高 plot(profile,type=c(‘o‘,‘g‘))
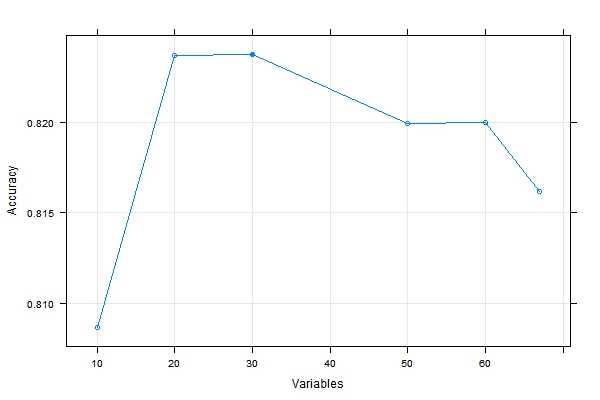
sbf和rfe函数都允许用户使用自定义的学习器进行特征选择,灵活度很高。另外在Rweka包中也有大量的特征选择方法可以使用。
标签:
原文地址:http://www.cnblogs.com/payton/p/5260239.html