标签:
【项目愿景】系统基于智能爬虫方向对数据由原来的被动整理到未来的主动进攻的转变的背景下,将赋予”爬虫”自我认知能力,去主动寻找”进攻”目标。取代人工复杂而又单调的重复性工作。能够实现在人工智能领域的某一方向上独当一面的作用。
【项目进展】项目一期基本实现框架搭建,对数据的处理和简单爬取任务实现。
【项目说明】为了能够更好理解优秀框架的实现原理,本项目尽量屏蔽优秀开源第三方jar包实现,自定义实现后再去择优而食,形成对比。
【设计原则】依据形式跟进新技术,不断积累在不同业务场景下对各个开源技术的驾驭能力
【项目规划】
第一期 实现整个项目框架的搭建以及基础知识的积蓄!
第二期 完全实现爬虫在网络领域的各种需求运作
第三期 利用框架在特定领域内获取指定数据量后,通过”爬虫”自动批量处理海量数据,从中搜集(挖掘)有用数据或者通过各种识别技术(模式识别、图片识别、语音识别等)实现数据自动收集并高效化整理!跳转到第四、五期
第四期 平台框架升级,利用现有成熟数据处理以及数据可视化技术对平台相应功能点进行生产化(所谓生产话改造是指能够利用成熟框架快速适应生产化需求)改造。[成熟技术有Hadoop\Spark\Redis等优秀的各个方面的框架或技术、R语言],(注意:并且尽量使用开源框架,目的是研究优秀框架的实现源代码)
第五期 平台语言升级,因为数据处理方向python有着优秀的性能,故需要将开发好的平台部分功能用合适的语言实现[注意:平台在真正的运行过程当中必定存在多方面的性能问题,要不断的反思解决问题的方案,结合不同语言的优势和所做的业务逻辑的差别,采用不同的处理方式]
第六期 移动端开发,自选方向......
第七期 采用机器学习等技术深度解析数据中的自动化问题,是的数据史前时代的被动整理,成为未来数据的自动清洗,将成熟的识别技术应用到平台开发当中。
【项目设计忠告】
本着实现任何功能从jdk甚至更为基础的代码训练出发,使自己更加了解底层的实现细节,从而在尽可能短的时间里将jdk的80%能够实现自由使用,java只是与计算机沟通的一种工具或是手段!在编程过程当中自我实现某些功能必定不是最优的,你就要学会从中寻找利于更为合适的和计算机沟通的方式,不同语言又不同的优势,要在不断地实践中摸索,发挥出不同语言的优势出来!
如果说 Java 是自动档轿车,C 就是手动档吉普。数据结构呢?是变速箱的工作原理。你完全可以不知道变速箱怎样工作,就把自动档的车子从 A 开到 B,而且未必就比懂得的人慢。写程序这件事,和开车一样,经验可以起到很大作用,但如果你不知道底层是怎么工作的,就永远只能开车,既不会修车,也不能造车。如果你对这两件事都不感兴趣也就罢了,数据结构懂得用就好。但若你此生在编程领域还有点更高的追求,数据结构是绕不开的课题。
Java 替你做了太多事情,那么多动不动还支持范型的容器类,加上垃圾收集,会让你觉得编程很容易。但你有没有想过,那些容器类是怎么来的,以及它存在的意义是什么?最粗浅的,比如 ArrayList 这个类,你想过它的存在是多么大的福利吗——一个可以随机访问、自动增加容量的数组,这种东西 C 是没有的,要自己实现。但是,具体怎么实现呢?如果你对这种问题感兴趣,那数据结构是一定要看的。甚至,面向对象编程范式本身,就是个数据结构问题:怎么才能把数据和操作数据的方法封装到一起,来造出 class / prototype 这种东西?
此外,很重要的一点是,数据结构也是通向各种实用算法的基石,所以学习数据结构都是提升内力的事情。在全程设计的过程当中要不断坚持从错误中学习,有位名人曾说,我从别人的错误里去学习,而不是一直去学习别人是怎么成功的!这也就是说,我们要这爱bug,调试bug就是在自我超越中成长!
【架构及核心模块实现】
【分布式爬虫架构原理图】
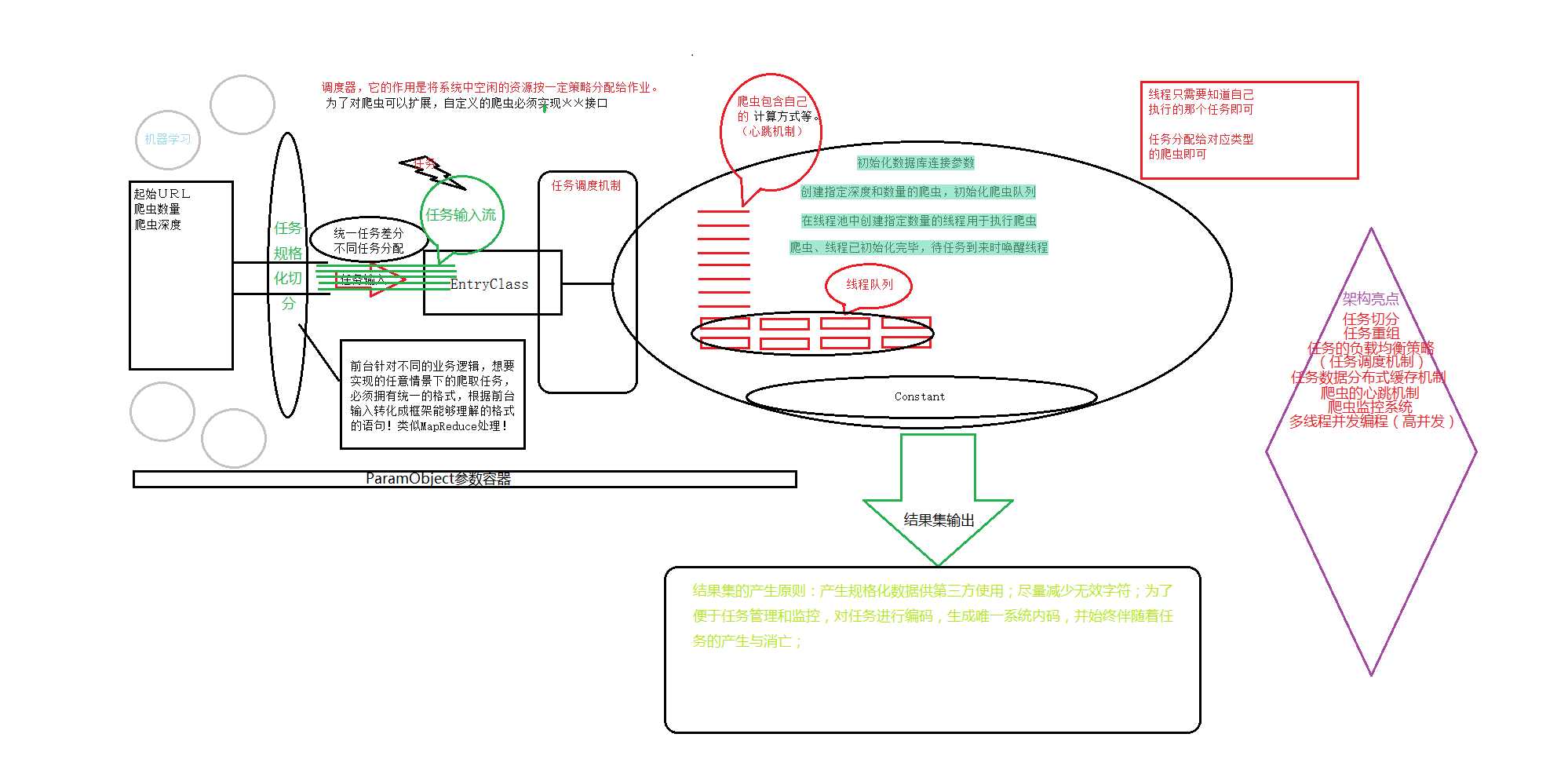
【项目地址】https://github.com/chenkai1100/SpiderFrame/
欢迎各路大神批评指正。
标签:
原文地址:http://www.cnblogs.com/aidou/p/5264382.html