标签:
相关的类:
java.util.regex.Pattern
static Pattern compile(String regex) //编译模式
static Pattern compile(String regex, int flags) //编译模式并指定标志
Matcher matcher(CharSequence input) //根据这个模式创建matcher对象
String pattern() //返回这个对象的模式匹配字符串
String[] split(CharSequence input) //根据指定的模式分隔字符串为数组
java.util.regex.Matcher
boolean find() //尝试查找下一个匹配的子串,找到返回true
int start() //上一个匹配的子串开始的索引位置
int end() //上一个匹配的子串的结尾的后一个位置索引
String group() //返回上一个匹配的子串
int groupCount() //返回匹配组模式的个数
Pattern pattern() //返回模式匹配字符串
思路:
这么要求肯定是要用正则的了,然后以字母开头,"\\b[A-Za-z]", 然后呢单词里可以包含字母数组"[A-Za-z0-9]",不要用"\\w", 这个里还有个下划线,然后单词长度大于等于4, 组合一下就是"\\b[A-Za-z][A-Za-z0-9]{3,}\\b", 结尾肯定是字母或数字无疑了。然后就是根据模式查找匹配的子串,转换为小写存入Map中。提取映射的键名到集合中,最后用一个迭代器根据键名的集合循环读出映射中的值。
源程序:
贴个程序吧:
1 import java.util.regex.Matcher; 2 import java.util.regex.Pattern; 3 import java.util.Scanner; 4 import java.util.Map; 5 import java.util.HashMap; 6 import java.util.Iterator; 7 import java.util.Set; 8 9 public class countcha { 10 11 public static void main(String[] args) 12 { 13 Map<String,Integer> numcount=new HashMap<String,Integer>(); 14 //regex 15 Pattern pat=Pattern.compile("\\b[A-Za-z][A-Za-z0-9]{3,}\\b"); 18 Scanner in=new Scanner(System.in); 19 System.out.print("please input a string:"); 20 String sda=in.nextLine(); 21 in.close(); 22 Matcher mth=pat.matcher(sda); 23 boolean tf=mth.find(); 24 while(tf) 25 { 26 String buffer=mth.group().toLowerCase(); 29 numcount.put(buffer, numcount.get(buffer)==null?1:numcount.get(buffer)+1); 30 tf=mth.find(); 31 } 32 33 Set<String> countSet=numcount.keySet(); 35 //output 36 Iterator<String> point=countSet.iterator(); 37 while(point.hasNext()) 38 { 39 String value=(String)point.next(); 40 System.out.println(value+":"+numcount.get(value)); 41 } 42 } 43 }
运行结果:
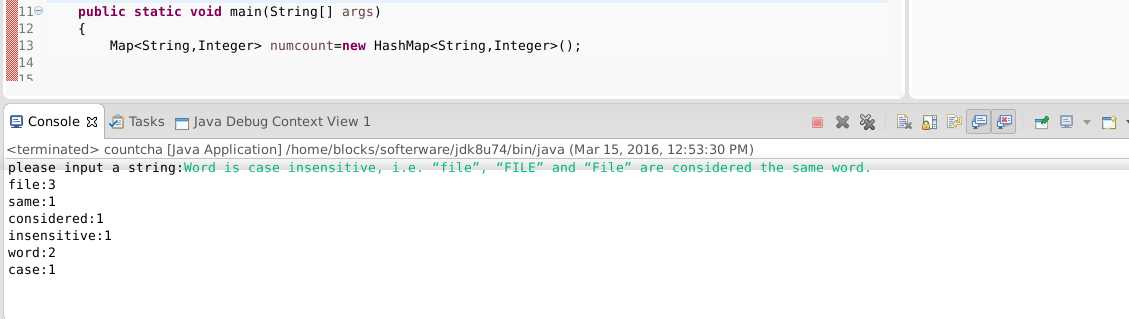
附加:
另外还有个说从文本读入数据统计单词个数的,这个差不多,按行读取,然后模式循环匹配直到文件结尾,如果发现单词则查询已存在的映射中是否已有,有则加1, 没有则置1。最后输出映射中的内容。我用的数据是“because of you”这首歌词,命名为becauseofyou.txt放在项目根目录下了。测试结果:
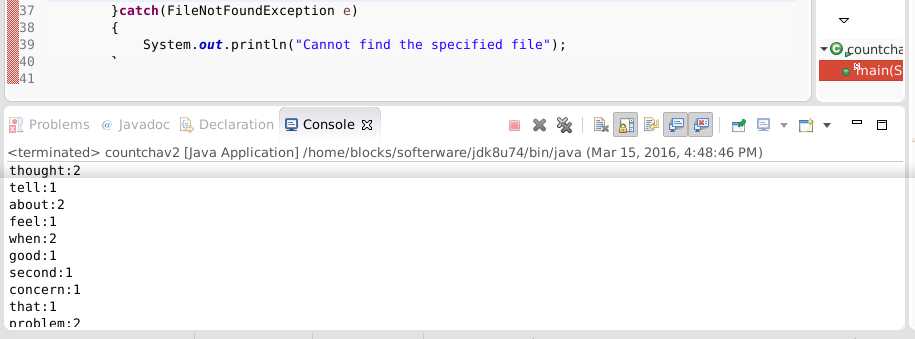
结论:
预计用时1h, 结果正则卡死我了,不太熟悉,用时4h+。
具体源码地址:https://github.com/blocksmz/task3
标签:
原文地址:http://www.cnblogs.com/blocksmz/p/5279925.html