标签:
这种技术的原理是什么?计算机怎么知道两张图片相似呢?
根据Neal Krawetz博士的解释,原理非常简单易懂。我们可以用一个快速算法,就达到基本的效果。
这里的关键技术叫做"感知哈希算法"(Perceptual hash algorithm),它的作用是对每张图片生成一个"指纹"(fingerprint)字符串,然后比较不同图片的指纹。结果越接近,就说明图片越相似。
下面是一个最简单的实现:
第一步,缩小尺寸。
将图片缩小到8x8的尺寸,总共64个像素。这一步的作用是去除图片的细节,只保留结构、明暗等基本信息,摒弃不同尺寸、比例带来的图片差异。


第二步,简化色彩。
将缩小后的图片,转为64级灰度。也就是说,所有像素点总共只有64种颜色。
第三步,计算平均值。
计算所有64个像素的灰度平均值。
第四步,比较像素的灰度。
将每个像素的灰度,与平均值进行比较。大于或等于平均值,记为1;小于平均值,记为0。
第五步,计算哈希值。
将上一步的比较结果,组合在一起,就构成了一个64位的整数,这就是这张图片的指纹。组合的次序并不重要,只要保证所有图片都采用同样次序就行了。
得到指纹以后,就可以对比不同的图片,看看64位中有多少位是不一样的。在理论上,这等同于计算"汉明距离"(Hamming distance)。如果不相同的数据位不超过5,就说明两张图片很相似;如果大于10,就说明这是两张不同的图片。
具体的代码实现,可以参见Wote用python语言写的imgHash.py。代码很短,只有53行。使用的时候,第一个参数是基准图片,第二个参数是用来比较的其他图片所在的目录,返回结果是两张图片之间不相同的数据位数量(汉明距离)。
这种算法的优点是简单快速,不受图片大小缩放的影响,缺点是图片的内容不能变更。如果在图片上加几个文字,它就认不出来了。所以,它的最佳用途是根据缩略图,找出原图。
实际应用中,往往采用更强大的pHash算法和SIFT算法,它们能够识别图片的变形。只要变形程度不超过25%,它们就能匹配原图。这些算法虽然更复杂,但是原理与上面的简便算法是一样的,就是先将图片转化成Hash字符串,然后再进行比较。
感谢@喜馒头找到了源头 。
【多图、多图】
正好刚刚完成相关必修课的一个课下环节作业,作业题目就是通过实际进行图像搜索,推测百度图像搜索用了什么原理。
在对百度图像检索原理调研的过程中,发现目前百度可能采用的原理有:(1)基于“信息指纹”;(2)基于颜色特征;(3)取阈值分割图像;(4)深度学习;(5)跨媒体检索。下面对各个原理进行简要的介绍、测试以及分析总结。
1、基于“信息指纹”
1.1 原理介绍
这种检索方法可以分为如下几个步骤进行:
① 缩小尺寸。
将图片缩小到8×8的尺寸,总共64个像素。这一步的作用是去除图片的细节,只保留结构、明暗等基本信息,摒弃不同尺寸、比例带来的图片差异。
②简化色彩。
将缩小后的图片,转为64级灰度。也就是说,所有像素点总共只有64种颜色。
③计算平均值。
计算所有64个像素的灰度平均值。
④比较像素的灰度。
将每个像素的灰度,与平均值进行比较。大于或等于平均值,记为1;小于平均值,记为0。
⑤计算哈希值。
将上一步的比较结果,组合在一起,就构成了一个64位的整数,这就是这张图片的指纹。组合的次序并不重要,只要保证所有图片都采用同样次序就行了。
得到指纹以后,就可以对比不同的图片,看看64位中有多少位是不一样的。在理论上,这等同于计算“汉明距离”(Hamming distance)。如果不相同的数据位不超过5,就说明两张图片很相似;如果大于10,就说明这是两张不同的图片。
1.2 分析
通过对“信息指纹”的原理介绍,我们发现这种方法比较看重检索图像的结构以及灰度值的分布情况,不能得到RGB值的分布情况,在检索时也不具有旋转、平移不变性。
1.3 测试
经过上述分析,我用MATLAB生成了几幅图像,然后利用百度识图进行检索测试,下面是测试的结果。
图1 原图a

图2 图a的检索结果

图3 原图b
图4 图b的检索结果
图5 原图c
图6 图c的检索结果
经过上面三次检索测试,我们可以得到如下结论:
(1) 图a和图b之间只是旋转了90度,结果发现检索的结果也旋转了90度,说明百度图片检索对图片的结构的确很敏感,检索图像时不具有旋转不变性;
(2) 图c是在图b的基础上加上了一个RGB颜色分布,比较b和c的检索结果,发现检索出来图片的结构都比较相似,但是,后者明显比前者多了颜色信息,这说明百度在进行图片检索时,RGB颜色的分布也是检索的依据之一;
(3) 仔细观察图b的检索结果,发现排名第二的图片和检索出的其他图片差别其实是很大的,他们在整体结构上完全不一样,只是局部结构上有一些线条信息,这也是一个值得思考的地方。
2、基于颜色特征
2.1 原理介绍
基于颜色特征的图像检索原理的大致思想是:每张图像都可以转化成颜色分布直方图(color histogram),如果两张图片的直方图很接近,就可以认为它们很相似,如图: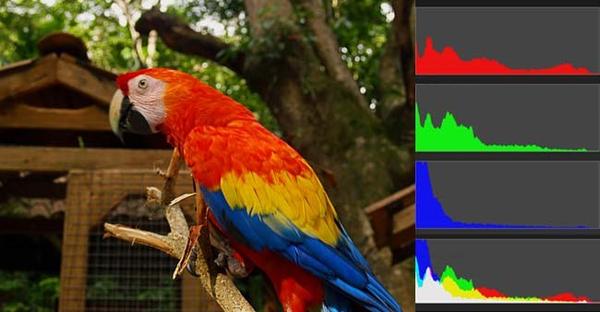
任何一种颜色都是由红绿蓝三原色(RGB)构成的,所以上图共有4张直方图(三原色直方图 + 最后合成的直方图)。将0~255分成四个区:0~63为第0区,64~127为第1区,128~191为第2区,192~255为第3区。这意味着红、绿、蓝分别有4个区,总共可以构成64种组合(4的3次方)。任何一种颜色必然属于这64种组合中的一种,这样就可以统计每一种组合包含的像素数量。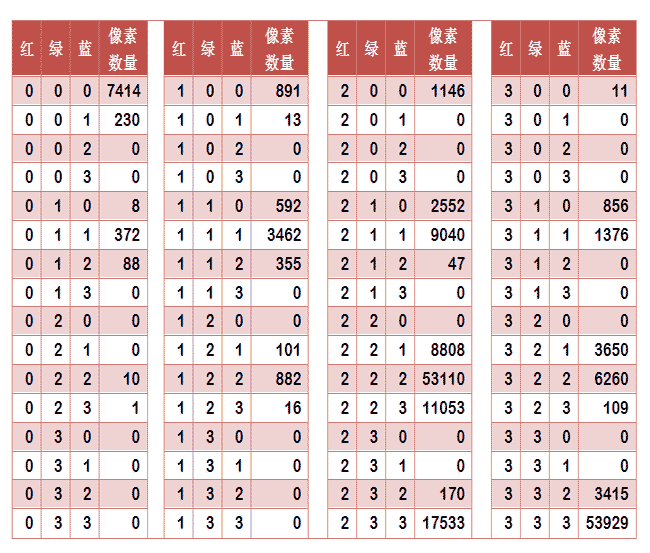
上图是某张图片的颜色分布表,将表中最后一栏提取出来,组成一个64维向量(7414, 230, 0, 0, 8, ..., 109, 0, 0, 3415, 53929)。这个向量就是这张图片的特征值。于是,寻找相似图片就变成了找出与其最相似的向量。这可以用皮尔逊相关系数或者余弦相似度算出。
2.2 分析
通过上述原理描述,我们发现基于这种原理的图像检索只关注图像在统计意义下的RGB颜色分布信息,并不关心图像本身的空间分布信息。
2.2 测试

图7 原图d
图8 图d的检索结果
图9 原图e
图10 图e的检索结果
观察上诉测试结果,我们可以得到如下几个结论:
(1) 还是验证了百度图像检索对结构比较看重,检索出来的图像和原图在整体结构上保持一致;
(2) 原图d和原图e只是改变了一下色块的位置,所以如果做它们的颜色分布直方图应该是完全一致的,但是这两张图片的检索结果很相似但是并不完全相同,因此基本可以判断百度图像检索肯定不可能只采用颜色分布直方图来进行检索;
(3) 原图d和原图e唯一的差别就是色块的位置改变了,但是检索出来的结果并不相同,说明百度进行图像检索时应该也是考虑了颜色在空间位置上的分布信息的。
3、取阈值分割图像
3.1 原理介绍
首先,将原图转成一张较小的灰度图片,假定为50×50像素。然后,确定一个阈值,将灰度图片转成黑白图片。如果两张图片很相似,它们的黑白轮廓应该是相近的。确定阈值可以采用“穷举法”,将阈值从灰度的最低值到最高值,依次取一遍,使得“类内差异最小”或“类间差异最大”的那个值,就是最终的阈值。

有了50×50像素的黑白缩略图,就等于有了一个50×50的0-1矩阵。矩阵的每个值对应原图的一个像素,0表示黑色,1表示白色。这个矩阵就是一张图片的特征矩阵。
两个特征矩阵的不同之处越少,就代表两张图片越相似。这可以用“异或运算”实现(即两个值之中只有一个为1,则运算结果为1,否则运算结果为0)。对不同图片的特征矩阵进行“异或运算”,结果中的1越少,就是越相似的图片。
3.2 分析
可以看出这种方法和第一种“信息指纹”的原理是很相似的,因此也具有相似的特点,就是都对图像的结构比较看重,忽视RGB颜色的分布,并且检索图像不具有旋转、平移不变性。
3.3 测试
 图11 原图f
图11 原图f
 图12 图f的检索结果
图12 图f的检索结果
 图13 原图g
图13 原图g
 图14 图g的检索结果
图14 图g的检索结果
 图15 原图h
图15 原图h
 图16 图h的检索结果
图16 图h的检索结果
通过上述检索测试,我们可以得到如下结论:
(1) 图f和图h唯一的区别是f是彩色图像,h是它的二值图像,但是我们发现他们的检索结果有很大的差别,彩色图像检索出来依然是彩色图像,二值图像检索出来也都是二值图像,至少可以说明百度图片检索不可能只靠取阈值分割图像来作为检索依据;
(2) 图g是在图f 的基础上进行了一个90度的旋转,发现两者的检索结果差别还是挺大的,再一次验证了百度图片检索不具有旋转不变性;
(3) 当用彩色人脸进行检索时得到的几乎都是人脸,但是二值化后进行检索,发现检索结果并不完全是人脸,有动物甚至毛笔字,还是说明原图像RGB的分布在做检索时还是比较重要的;
4、深度学习(Deep Learning)
4.1 原理介绍
自从Hinton在2012年将深度卷积神经网络(CNN)带入到图像分类领域后,深度学习在图像处理相关领域的研究一下子变得异常火热起来。从2012年开始,每年ILSVRC比赛的最好成绩都有比较大的进步,特别是最近2015年百度刚宣布他们已经将ImageNet图像分类的top-5错误率降低到5.98%,达到了目前公开的最好成绩,基于百度对将深度学习应用在图像处理领域的如此强烈的兴趣和技术能力,百度很有可能已经将深度学习的技术应用在了图像搜索方面。
由于现在关于深度卷积神经网络的资料挺多的,并且基本都还没脱离Hinton在2012年提出的结构,所以这里不准备详细展开CNN的原理介绍。简单概括就是:利用多个隐藏层、每层多个卷积核对输入图像进行卷积,每层的输出作为下一层的输入,最后连接一个分类器进行分类,通过不断的训练修改各层的参数,最后在每个隐藏层训练得到一些抽象的特征图谱,网络训练好后就可以对输入图像进行分类了。
4.2 分析
基于深度学习原理的图像检索,更多的是从一种图像理解的角度来进行的,得到的是一种更加抽象的描述,也可以理解为“语义”,它更多的是在解释这个图像描绘的是什么物体或者什么场景之类的。
4.3 测试
 图17 原图i
图17 原图i
 图18 图i的检索结果
图18 图i的检索结果
 图19 原图j
图19 原图j
 图20 图j的检索结果
图20 图j的检索结果
 图21 原图k
图21 原图k
 图22 图k的检索结果
图22 图k的检索结果
 图23 原图l
图23 原图l
 图24 图l的检索结果
图24 图l的检索结果
上述用于检索的原图都是我手机里面自己平时拍的,网络上没有的,完全的无标注数据。我们发现检索的结果在语义上还是比较非常相近的,背景也非常相近,百度应该是对图像做了一定程度的语义理解的。
5、利用种子图片
5.1 原理
在2013年的时候有人将深度学习应用在图像检索领域,大致做法是这样的:首先它利用深度卷积神经网络和深度自动编码器提取图片的多层特征,并据此提取图片的visual word,建立倒排索引,产生一种有效而准确的图片搜索方法,再充分利用大量的互联网资源,预先对大量种子图片做语义分析,然后利用相似图片搜索,根据相似种子图片的语义推导出新图片的语义。
5.2 分析
但如果按照上面原理的描述,似乎重点在于对种子图片的判断上,如果种子图片判断对了,那么检索结果自然会很靠谱;反之,若种子图片判断错了,那么检索结果会很糟糕。其实这更像是一种利用互联网多年文本检索的积累,进行的一种文本与图像之间的跨媒体检索。
5.3 测试
 图25 图m的检索结果
图25 图m的检索结果
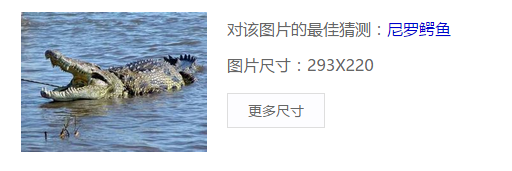 图26 图m的判断
图26 图m的判断
 图27 图m的检索结果
图27 图m的检索结果
上面用来测试的原图是在网上找的,检索给出的描述表明对该图像的文本判断是正确的,但是检索到的结果却并不理想,只有前两张图像是描述的鳄鱼,其他都不是,只是背景相似。因此应该可以得出结论,百度图像检索没有利用其文本检索的信息,纯粹依靠的是输入图像本身的性质。
总结
通过上述分析,对于百度的图像检索可以得到的判断是:
(1) 不可能只采用“信息指纹”、颜色直方图、取阈值分割法其中的某一种来做为判断依据;
(2) 应该是对图像做了语义理解的;
(3) 检索的结果跟输入图像的结构、RGB颜色的空间分布等信息有关系,并且检索不具有旋转不变性;
(4) 没有利用文本检索,即没有建立文本-图像的跨媒体检索;【哈哈哈,好开心,因为现在老板给我定的博士方向就是跨媒体检索~~】
对此,对百度图像检索所采用的原理的一个猜测是,它利用深度学习的方法进行了图像语义的理解,也有可能在某些情况下利用图像结构、RGB分布等信息作为辅助判断依据,并且对输入图像的方向性有要求。
参考资料
1、相似图片搜索的原理;
2、Ren Wu, Shengen Yan, Yi Shan, Qingqing Dang, Gang Sun,Deep Image: Scaling up Image Recognition
举例: 用图片作为输入, 得到结果: http://goo.gl/1K1nH基本原理上就是将搜索引擎的中间数据----正向索引, 进行功能扩展和提供服务
标签:
原文地址:http://www.cnblogs.com/developer-ios/p/5286653.html














