标签:
此项目的功能是爬取知乎用户信息以及人际拓扑关系,爬虫框架使用scrapy,数据存储使用mongo,下载这些数据感觉也没什么用,就当为大家学习scrapy提供一个例子吧。代码地址:https://github.com/LiuRoy/zhihu_spider,欢迎各位大神指出问题,另外知乎也欢迎大家关注哈 ^_^.
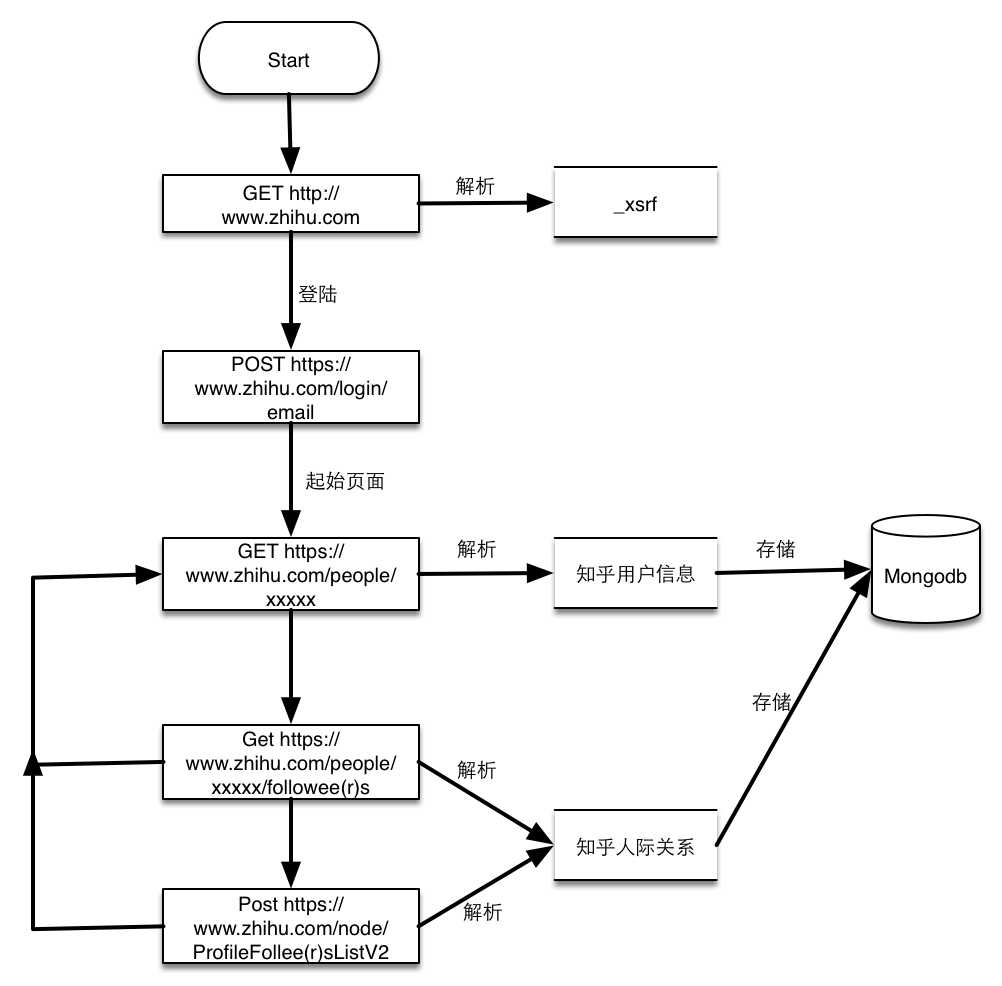
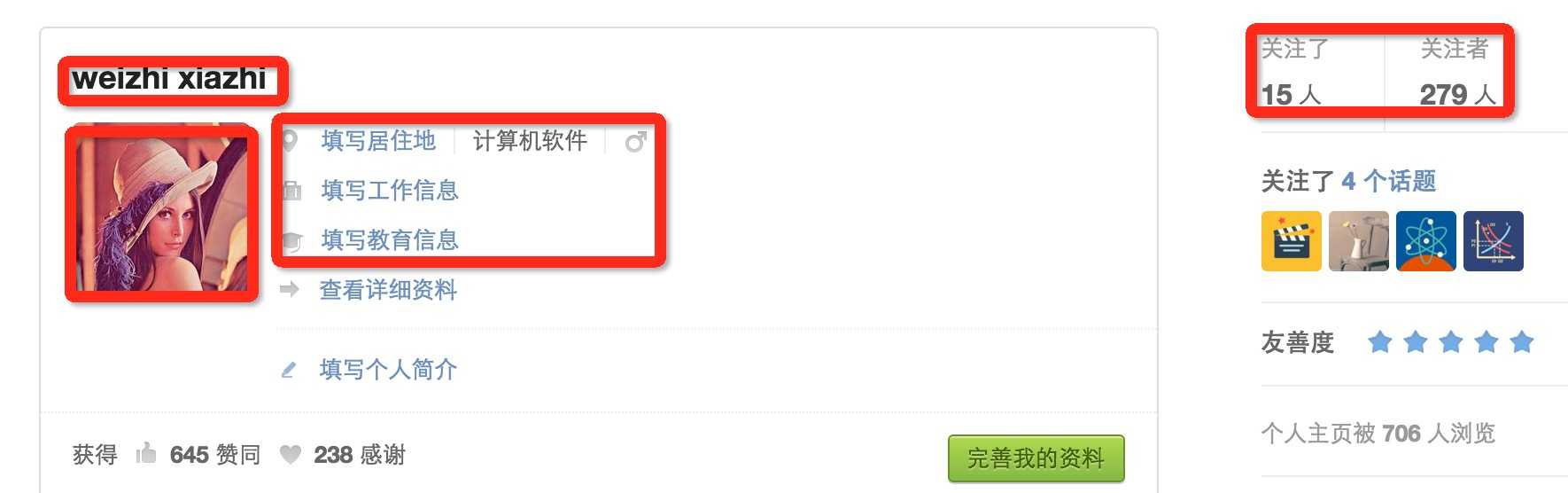
scrapy文档非常详细,在此我就不详细讲解,你所能碰到的任何疑问都可以在文档中找到解答。
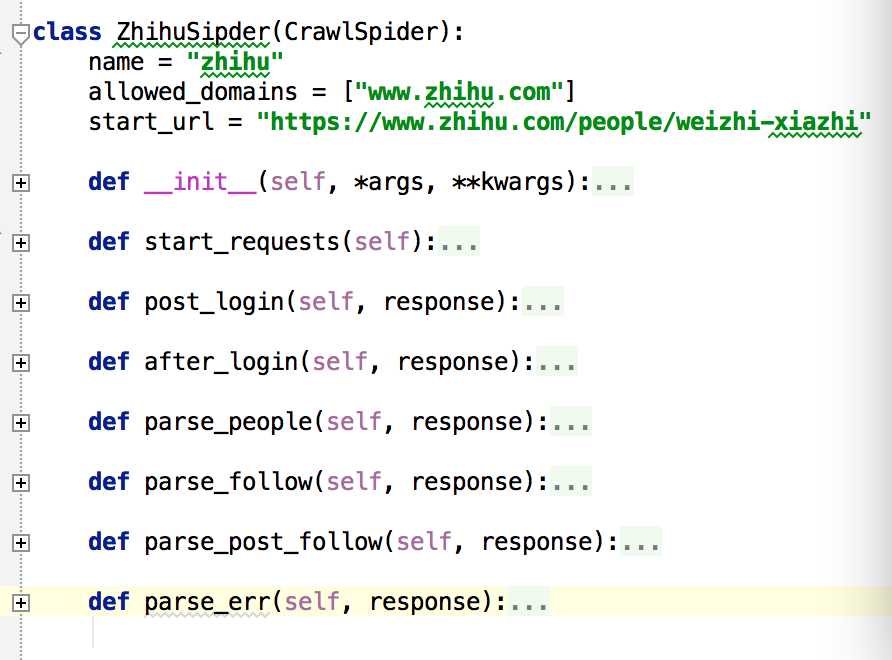
标签:
原文地址:http://www.cnblogs.com/lrysjtu/p/5297386.html