标签:
我通常也把相关query称为相似query,搜索日志中一个用户在短时间内的一系列搜索词被称为相关query。相关就是两个query间有一定的关系,反映了用户在当时的需求。本文就以应用搜索为背景来介绍相关query。
相关query的作用就很多了:
当用户输入一个query时,后台加入其相关query一起搜索,就可以更好的理解用户,返回更多、更准确的结果,减少搜索次数,提高下载次数,提高转化率。
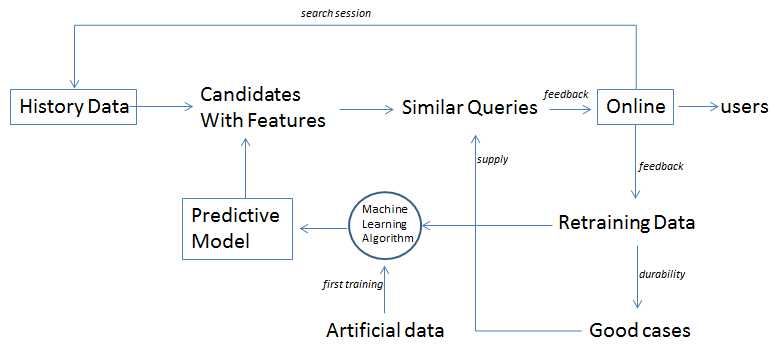
候选数据
分析每天的用户日志,从搜索日志中提取短时间(15分钟或30分钟)内的搜索词组成候选相关query对<a, b>。最后分析的日志天数越多越好,数据越多挖掘出的相关query对越多,结果也越准确。
特征抽取
模型训练
补招漏选数据
最终结果的多少的主要影响因素有用户搜索日志间隔、日志天数。具体实现过程中发现和大query相关的小众query招不回来,因为其本身搜索次数太多。但我们需要大query来为小query导流。
<纪念碑谷(44736次),天空迷宫(200次)>,共现次数是89次,相似度是0.004,相似度太低,导致纪念碑谷无法召回天空迷宫。
<天空迷宫,纪念碑谷>其相似度是0.069,被认为是相关query。
所以我们会反向找一次,对于相关query对<天空迷宫,纪念碑谷>会判断下其反向对<纪念碑谷,天空迷宫>的情况,如果发现纪念碑谷是大query(超过一定次数如1w)且其自身相似度超过一定域值(如0.003),我们也会把<纪念碑谷,天空迷宫>给招回来。
线上反馈
在线系统使用离线数据(相关查询对)进行了线上搜索结果的补充或召回,将相关query对应的应用展示给了用户,用户会选择下载与不下载。我们就获得这些数据来重新训练算法模型。
queryA的下载列表<appIds>
从appIds中找到queryA的相关queryB召回的应用:app应用名与queryB的编辑距离超过一定值,就认为该app是由queryB召回
如果queryB召回的应用下载数超过一定域值,我们就认为这是一个正向case,queryB是queryA的相关query
如果queryB召回的应用没有下载或下载小于一定数目,就认为是一个负向case,queryB不是queryA的相关query
这样我们就可以通过线上展示结果获取一份真实的标注数据,用该数据去重新训练算法,获得一个新模型来重新预测原始数据。
线上反馈的作用就是找到真实标注数据,替换旧样本获得新模型,从而不断提高模型的准确度
持久化good case,避免回退
最初<queryA, queryB>是相关query对,每当用户搜索queryA时,就会出来queryB的结果。时间久了,用户输入queryA后就不会再输入queryB,那就导致可能在某段时间后挖掘不出该相似对,那queryA下就无法显示queryB对应的应用;用户又会渐渐的在输入queryA后再次输入queryB才能获得想要的结果。这样就导致效果起伏,我们需要避免这种情况。
所以对每次线上反馈中的正向case,我们都做持久化,以白名单的形式强制加到最终的相关query中。以此来积累正向case,减少效果回退的情况。
到现在为止,我们就拥有了一个动态、完整、可持续的离线在线相互反馈促进的系统了。
标签:
原文地址:http://www.cnblogs.com/whuqin/p/5330544.html