标签:
HDFS 的备份功能不是给 基于 HBase 等 基于HDFS 的项目做备份的。 如果 HBase 需要备份,那么久需要设置 备份(快照 )功能。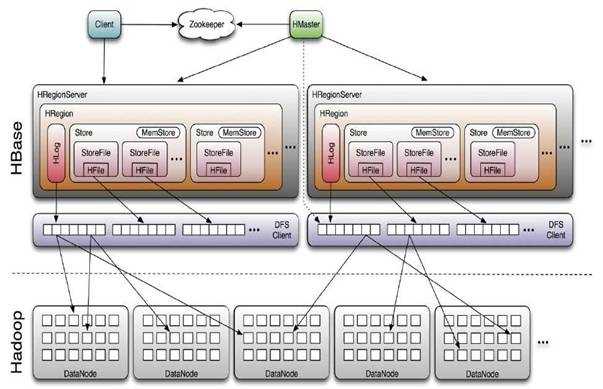
过程写得比较凌乱了,把之前的总结一下吧:
1、做准备工作,实例化变量
2、检查Put和Delete里面的列族是否和Region持有的列族的定义相同。
3、给Row加锁,先计算hash值做key,如果该key没上过锁,就上一把锁,然后计算出来要写的action有多少个,记录到numReadyToWrite。
4、更新时间戳,把该action里面的所有的kv的时间戳更新为最新的时间戳,它这里也会把之前的没运行的也一起更新。
5、给该region加锁,这个时间点之后,就不允许读了,等待时间需要根据numReadyToWrite的数量来计算。
6、上锁之后,下面就是重头戏了,也就是Put、Delete等的重点。给这些写入memstore的数据创建一个批次号。
7、把kv们写入到memstore当中,然后计算出来一个添加数据之后的新的MemStore的大小addedSize。
8、把kv添加到日志当中,标志状态为成功,如果是用户设置了不写入日志的,它就不写入日志了。
9、先异步添加日志。
10、释放之前创建的锁。
11、同步日志。
12、结束该批次的操作。
Final、同步日志没成功的,最后根据批次回滚MemStore中的操作。
Put和Delete操作就没区别吗,那它怎么删除数据的?
返回在第4步更新时间戳的时候,发现了一些猫腻,Delete的情况执行了prepareDeleteTimestamps方法,看看吧。先判断是否是最新的时间戳,只传了rowkey进去的,它就是最新的,Delete的构造函数:凡是在这个时间点之前的所有版本的所有列,我们都要删除。这里干了一个Get操作,,把列族的多个版本的内容取出来,如果数量不符合预期也会有问题
标签:
原文地址:http://www.cnblogs.com/rocky24/p/ff39d2f903ac61c9008998a06a823c6a.html