标签:
(学习网易云课堂Hadoop大数据实战笔记)


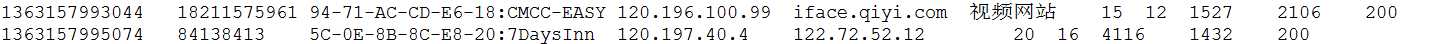
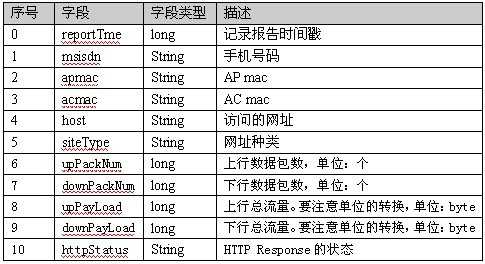
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class TrafficWritable implements Writable {
long upPackNum, downPackNum,upPayLoad,downPayLoad;
public TrafficWritable() { //这个构造函数不能省,否则报错
super();
// TODO Auto-generated constructor stub
}
public TrafficWritable(String upPackNum, String downPackNum, String upPayLoad,
String downPayLoad) {
super();
this.upPackNum = Long.parseLong(upPackNum);
this.downPackNum = Long.parseLong(downPackNum);
this.upPayLoad = Long.parseLong(upPayLoad);
this.downPayLoad = Long.parseLong(downPayLoad);
}
@Override
public void write(DataOutput out) throws IOException { //序列化
// TODO Auto-generated method stub
out.writeLong(upPackNum);
out.writeLong(downPackNum);
out.writeLong(upPayLoad);
out.writeLong(downPayLoad);
}
@Override
public void readFields(DataInput in) throws IOException { //反序列化
// TODO Auto-generated method stub
this.upPackNum=in.readLong();
this.downPackNum=in.readLong();
this.upPayLoad=in.readLong();
this.downPayLoad=in.readLong();
}
@Override
public String toString() { //不加toStirng函数,最后输出内存的地址
return upPackNum + "\t"+ downPackNum + "\t" + upPayLoad + "\t"
+ downPayLoad;
}
}
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class TrafficCount {
/**
* @author nwpulisz
* @date 2016.3.31
*/
static final String INPUT_PATH="hdfs://192.168.255.132:9000/input";
static final String OUTPUT_PATH="hdfs://192.168.255.132:9000/output";
public static void main(String[] args) throws Throwable {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
Path outPut_path= new Path(OUTPUT_PATH);
Job job = new Job(conf, "TrafficCount");
//如果输出路径是存在的,则提前删除输出路径
FileSystem fileSystem = FileSystem.get(new URI(OUTPUT_PATH), conf);
if(fileSystem.exists(outPut_path))
{
fileSystem.delete(outPut_path,true);
}
FileInputFormat.setInputPaths(job, INPUT_PATH);
FileOutputFormat.setOutputPath(job, outPut_path);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(TrafficWritable.class);
job.waitForCompletion(true);
}
static class MyMapper extends Mapper<LongWritable, Text, Text, TrafficWritable>{
protected void map(LongWritable k1, Text v1,
Context context) throws IOException, InterruptedException {
String[] splits = v1.toString().split("\t");
Text k2 = new Text(splits[1]);
TrafficWritable v2 = new TrafficWritable(splits[6], splits[7],
splits[8], splits[9]);
context.write(k2, v2);
}
}
static class MyReducer extends Reducer<Text, TrafficWritable, Text, TrafficWritable>{
protected void reduce(Text k2, Iterable<TrafficWritable> v2s, Context context
) throws IOException, InterruptedException {
long upPackNum=0L, downPackNum=0L,upPayLoad=0L,downPayLoad=0L;
for(TrafficWritable traffic: v2s) {
upPackNum += traffic.upPackNum;
downPackNum += traffic.downPackNum;
upPayLoad += traffic.upPayLoad;
downPayLoad += traffic.downPayLoad;
}
context.write(k2,new TrafficWritable(upPackNum+"",downPackNum+"",upPayLoad+"",
downPayLoad+""));
}
}
}
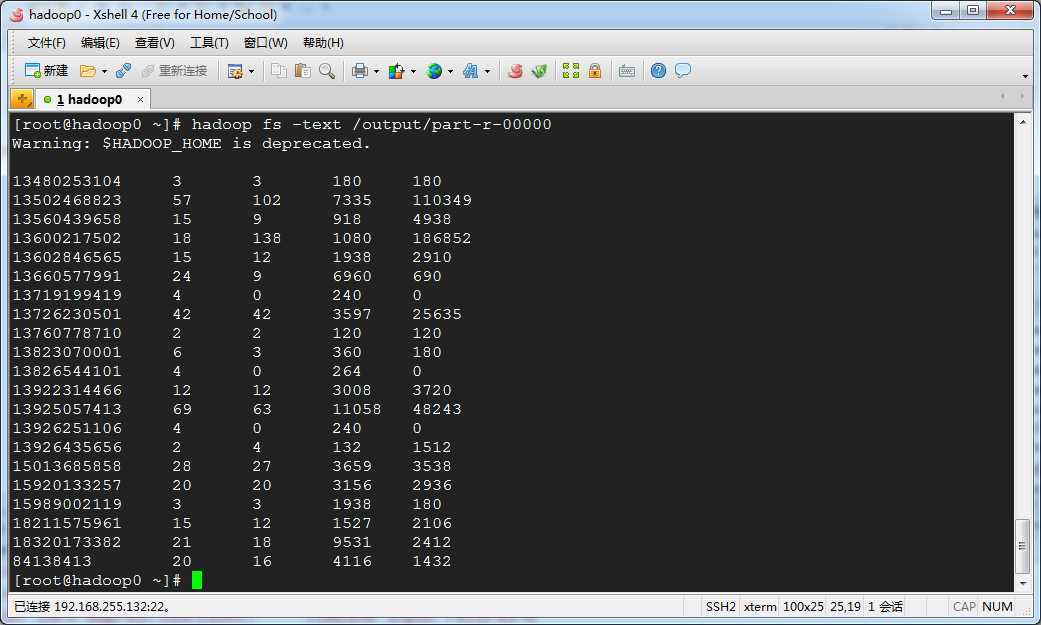
标签:
原文地址:http://www.cnblogs.com/nwpulisz/p/5346127.html