标签:
yum install gcc
yum install gcc-c++
yum install make
yum install autoconfautomake libtool cmake
yum install ncurses-devel
yum install openssl-devel
yum install git git-svn git-email git-gui gitk
安装protoc(需用root用户)
1 tar -xvf protobuf-2.5.0.tar.bz2
2 cd protobuf-2.5.0
3 ./configure --prefix=/opt/protoc/
4 make && make install
安装wget
sudo yum -y install wget
groupadd hadoop 添加一个组
useradd hadoop -g hadoop 添加用户
mvn clean package -Pdist,native -DskipTests -Dtar
编译完的hadoop在 /home/hadoop/ocdc/hadoop-2.6.0-src/hadoop-dist/target 路径下
10.1.245.244 master
10.1.245.243 slave1
10.1.245.242 slave2
命令行输入 hostname master
ssh到其他主机 相应输入 hostName xxxx
各节点 免密码登录
ssh-keygen -t rsa
cd /root/.ssh/
ssh-copy-id master
将生成的公钥id_rsa.pub 内容追加到authorized_keys(执行命令:cat id_rsa.pub >> authorized_keys)
时间等效性同步
ssh master date; ssh slave1 date;ssh slave2 date;
Mkdir data
(在data路径下创建目录)
mkdir yarn
mkdir jn
mkdir current
(hadoop路径下)
mkdir name
(jn目录下)
mkdir streamcluster
Tar zxvf zookeeper-3.4.6.tar.gz
Cp zoo_sample.cfg zoo.cfg
修改zoo.cfg文件:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/hadoop/ocdc/zookeeper-3.4.6/data
dataLogDir=/home/hadoop/ocdc/zookeeper-3.4.6/logs
# the port at which the clients will connect
clientPort=2183
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=master:2898:3898
server.2=slave1:2898:3898
server.3=slave2:2898:3898
在zookeeper目录下:
mkdir data
vi myid (写入id为1,)
拷贝zookeeper到各个目录下(将slave1中的myid改为2,slave2中的myid改为3....)
随后在 bin目录下 逐个启动zookeeper
./zkServer.sh start
./zkServer.sh status (查看状态)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs:// streamcluster </value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/ocdc/hadoop-2.6.0/tmp</value>
<description>Abasefor other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.spark.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.spark.groups</name>
<value>*</value>
</property>
</configuration>
<configuration>
<property>
<name>dfs.nameservices</name>
<value>streamcluster</value>
</property>
<property>
<name>dfs.datanode.address</name>
<value>0.0.0.0:50012</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:50077</value>
</property>
<property>
<name>dfs.datanode.ipc.address</name>
<value>0.0.0.0:50022</value>
</property>
<property>
<name>dfs.ha.namenodes.streamcluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/ocdc/hadoop-2.6.0/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/ocdc/hadoop-2.6.0/data</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permission</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.hdfs-blocks-metadata.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.rpc-address.streamcluster.nn1</name>
<value>master:8033</value>
</property>
<property>
<name>dfs.namenode.rpc-address.streamcluster.nn2</name>
<value>slave1:8033</value>
</property>
<property>
<name>dfs.namenode.http-address.streamcluster.nn1</name>
<value>master:50083</value>
</property>
<property>
<name>dfs.namenode.http-address.streamcluster.nn2</name>
<value>slave1:50083</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8489;slave1:8489;slave2:8489/streamcluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/ocdc/hadoop-2.6.0/data/jn</value>
</property>
<property>
<name>dfs.journalnode.rpc-address</name>
<value>0.0.0.0:8489</value>
</property>
<property>
<name>dfs.journalnode.http-address</name>
<value>0.0.0.0:8484</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.streamcluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>10000</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property>
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>4096</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>67108864</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>20</value>
</property>
<!--指定zookeeper地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2183,slave1:2183,slave2:2183</value>
</property>
</configuration>
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- Resource Manager Configs -->
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-rm-cluster</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk.state-store.address</name>
<value>master:2183,slave1:2183,slave2:2183</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2183,slave1:2183,slave2:2183</value>
</property>
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>master:23140</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>master:23130</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>master:23188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>master:23125</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>master:23141</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm1</name>
<value>master:23142</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>slave1:23140</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value> slave1:23130</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value> slave1:23188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value> slave1:23125</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value> slave1:23141</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm2</name>
<value> slave1:23142</value>
</property>
<!-- Node Manager Configs -->
<property>
<name>yarn.nodemanager.localizer.address</name>
<value>0.0.0.0:23344</value>
</property>
<property>
<name>yarn.nodemanager.webapp.address</name>
<value>0.0.0.0:23999</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value> /home/hadoop/ocdc/hadoop-2.6.0/data/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value> /home/hadoop/ocdc/hadoop-2.6.0/data/yarn/log</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:12345</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.4</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>16384</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>16384</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>
$HADOOP_CONF_DIR,
$HADOOP_COMMON_HOME/share/hadoop/common/*,
$HADOOP_COMMON_HOME/share/hadoop/common/lib/*,
$HADOOP_HDFS_HOME/share/hadoop/hdfs/*,
$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*,
$HADOOP_YARN_HOME/share/hadoop/yarn/*,
$HADOOP_YARN_HOME/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
(需要注意的是在yarn-site.xml中
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
如果做HA 备用namenode服务器要修改为rm2)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>16384</value>
</property>
<property>
<name>mapred.output.compression.type</name>
<value>BLOCK</value>
</property>
</configuration>
vi slaves
master1
slave1
slave2
随后将拷贝配置好的hadoop到各个服务器中
启动jounalnode
./hadoop-daemon.sh start journalnode
进行namenode格式化
./hadoop namenode -format
格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,之后通过下面命令,启动namenode进程在namenode2上执行
sbin/hadoop-daemon.sh start namenode
完成主备节点同步信息
./hdfs namenode –bootstrapStandby
格式化ZK(在namenode1上执行即可, 这句命令必须手工打上,否则会报错)
./hdfs zkfc –formatZK
启动HDFS(在namenode1上执行)
./start-dfs.sh
启动YARN(在namenode1和namenode2上执行)
./start-yarn.sh
在namenode1上执行${HADOOP_HOME}/bin/yarn rmadmin -getServiceState rm1查看rm1和rm2分别为active和standby状态
我们在启动hadoop各个节点时,启动namenode和datanode,这个时候如果datanode的storageID不一样,那么会导致如下datanode注册不成功的信息:
这个时候,我们需要修改指定的datanode的current文件中的相应storageID的值,直接把它删除,这个时候,系统会动态新生成一个storageID,这样再次启动时就不会发生错误了。
查看端口是否占用
netstat -tunlp |grep 22
查看所有端口
netstat -anplut
修改spark-env..sh 增加如下参数(路径根据服务器上的路径修改)
HADOOP_CONF_DIR=/home/hadoop/ocdc/hadoop-2.6.0/etc/hadoop/
HADOOP_HOME=/home/hadoop/ocdc/hadoop-2.6.0/
SPARK_HOME=/home/hadoop/ocdc/spark-1.6.1-bin-hadoop2.6/
SPARK_EXECUTOR_INSTANCES=3
SPARK_EXECUTOR_CORES=7
SPARK_EXECUTOR_MEMORY=11G
SPARK_DRIVER_MEMORY=11G
SPARK_YARN_APP_NAME="asiainfo.Spark-1.6.0"
#SPARK_YARN_QUEUE="default"
MASTER=yarn-cluster
修改spark-default.conf文件 (路径根据服务器上的路径修改)
spark.master yarn-client
spark.speculation false
spark.sql.hive.convertMetastoreParquet false
spark.driver.extraClassPath /home/hadoop/ocdc/spark-1.6.1-bin-hadoop2.6/lib/mysql-connector-java-5.1.30-bin.jar:/home/hadoop/ocdc/spark-1.6.1-bin-hadoop2.6/lib/datanucleus-api-jdo-3.2.6.jar:/home/hadoop/ocdc/spark-1.6.1-bin-hadoop2.6/lib
/datanucleus-core-3.2.10.jar:/home/hadoop/ocdc/spark-1.6.1-bin-hadoop2.6/lib/datanucleus-rdbms-3.2.9.jar:/home/hadoop/ocdc/spark-1.6.1-bin-hadoop2.6/lib/ojdbc14-10.2.0.3.jar
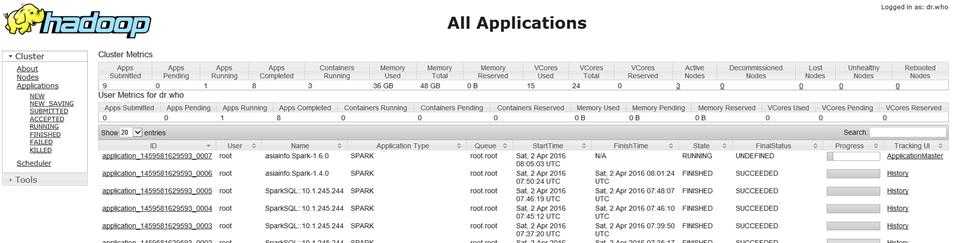
Hadoop监控页面(根据yarn-site.xml的参数yarn.resourcemanager.webapp.address.rm1中配置的端口决定的):
http://10.1.245.244: 23188
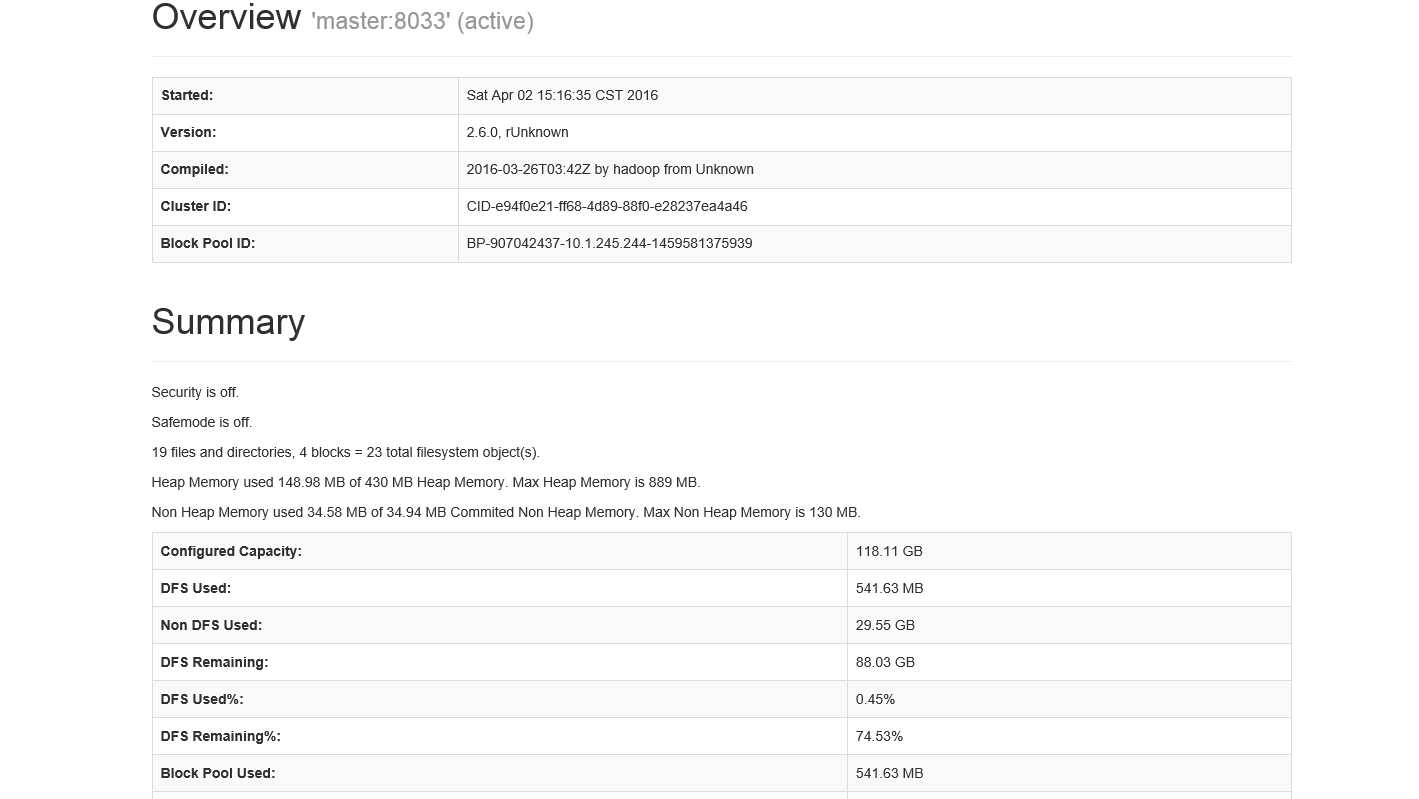
Hadoop namenode监控页面( 根据hdfs-site.xml中配置的参数 dfs.namenode.http-address.streamcluster.nn1中的端口决定):
http://10.1.245.244: 50083
spark thriftserver注册启动:
标签:
原文地址:http://www.cnblogs.com/yangsy0915/p/5347849.html