标签:
2011 年,当初选择 Redis 作为主要的内存数据存储,主要吸引我的是它提供多样的基础数据结构可以很方便的实现业务需求。另一方面又比较担心它的性能是否足以支撑,毕竟当时 Redis 还属于比较新的开源产品。但 Redis 官网宣称其是提供多数据结构的高性能存储,我们对其还是抱有幻想的。
要了解 Redis 的性能,我们先看看官方的基准性能测试数据,心里有个底。
测试前提
Redis version 2.4.2
Using the TCP loopback
Payload size = 256 bytes
测试结果
SET: 198412.69/s
GET: 198019.80/s这个数据刚一看觉得有点超出预期了,不过看了测试前提是规避了网络开销的,Client 和 Server 全在本机。而真实的使用场景肯定是需要走网络的,而且使用的客户端库也是不同的。不过这个官方参考数据当时让我们对 Redis 的性能还是抱有很大的期待的。
另外官方文档中也提到,在局域网环境下只要传输的包不超过一个 MTU (以太网下大约 1500 bytes),那么对于 10、100、1000 bytes 不同包大小的处理吞吐能力实际结果差不多。关于吞吐量与数据大小的关系可见下面官方网站提供的示意图。
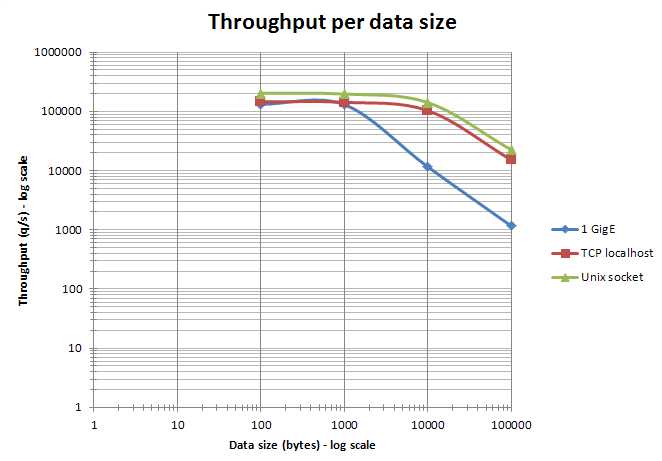
基于我们真实的使用场景,我们搭建了性能验证环境,作了一个验证测试,如下(数据来自同事 @kusix 当年的测试报告,感谢)。
测试前提
Redis version 2.4.1
Jmeter version 2.4
Network 1000Mb
Payload size = 100 bytes
测试结果
SET: 32643.4/s
GET: 32478.8/s在实验环境下得到的测试数据给人的感觉和官方差了蛮多,这里面因为有网络和客户端库综合的影响所以没有实际的横向比较意义。这个实验环境实测数据只对我们真实的生产环境具有指导参考作用。在实验环境的测试,单 Redis 实例运行稳定,单核 CPU 利用率在 70% ~ 80% 之间波动。除了测试 100 bytes 的包,还测了 1k、10k 和 100k 不同大小的包,如下图所示:
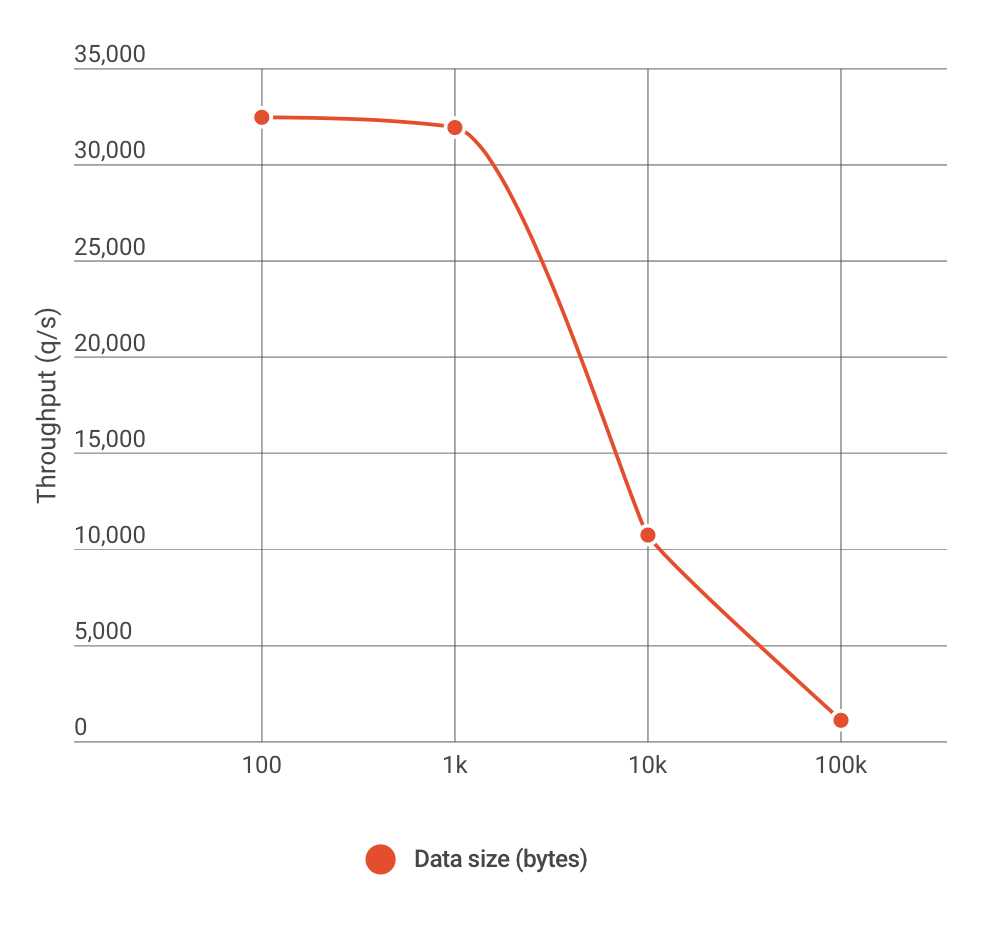
诚然,1k 基本是 Redis 性能的一个拐点,这一点从上图看趋势是和官方图的一致。
基于实验室测试数据和实际业务量,现实中采用了 Redis 分片来承担更大的吞吐量。一个单一 Redis 分片一天的 ops 波动在 20k~30k 之间,单核 CPU 利用率在 40% ~ 80% 之间波动,如下图。
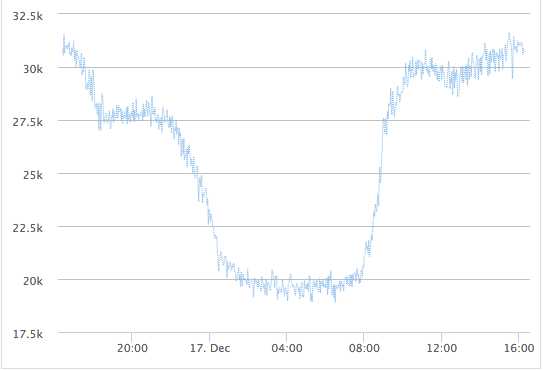
这与当初实验室环境的测试结果接近,而目前生产环境使用的 Redis 版本已升级到 2.8 了。如果业务量峰值继续增高,看起来单个 Redis 分片还有大约 20% 的余量就到单实例极限了。那么可行的办法就是继续增加分片的数量来分摊单个分片的压力,前提是能够很容易的增加分片而不影响业务系统。这才是使用 Redis 面临的真正残酷现实考验。
Redis 是个好东西,提供了很多好用的功能,而且大部分实现的都还既可靠又高效(主从复制除外)。所以一开始我们犯了一个天真的用法错误:把所有不同类型的数据都放在了一组 Redis 集群中。
导致的问题就是当你想扩分片的时候,客户端 Hash 映射就变了,这是要迁移数据的。而所有数据放在一组 Redis 里,要把它们分开就麻烦了,每个 Redis 实例里面都是千万级的 key。
而另外一个问题是单个 Redis 的性能上限带来的瓶颈问题。由于 CPU 的单核频率都发展到了瓶颈,都在往多核发展,一个 PC Server 一般 24或32 核。但 Redis 的单线程设计机制只能利用一个核,导致单核 CPU 的最大处理能力就是 Redis 单实例处理能力的天花板了。
举个具体的案例,新功能上线又有点不放心,于是做了个开关放在 Redis,所有应用可以很方便的共享。通过读取 Redis 中的开关 key 来判断是否启用某个功能,对每个请求做判断。这里的问题是什么?这个 key 只能放在一个实例上,而所有的流量进入都要去这个 Redis GET 一下,导致该分片实例压力山大。而它的极限在我们的环境上不过 4 万 OPS,这个天花板其实并不高。
认识清楚了现实的残酷性,了解了你所在环境 Redis 的真实性能指标,区分清幻想和现实。我们才能真正考虑好如何合理的利用 Redis 的多功能特性,并有效规避的它的弱项,再给出一些 Redis 的使用建议:
-根据数据性质把 Redis 集群分类;我的经验是分三类:cache、buffer 和 db
- cache:临时缓存数据,加分片扩容容易,一般无持久化需要。
- buffer:用作缓冲区,平滑后端数据库的写操作,根据数据重要性可能有持久化需求。
- db:替代数据库的用法,有持久化需求。
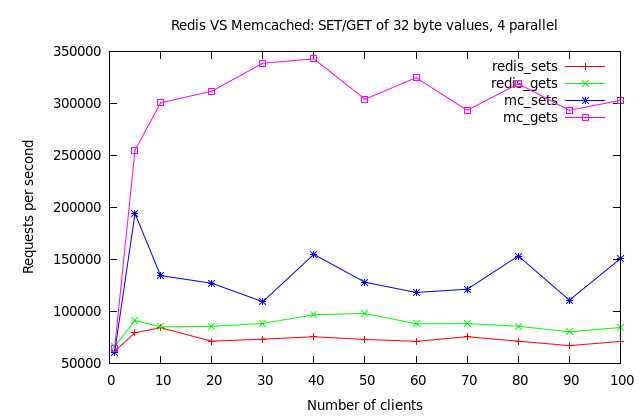
另外,有一种观点认为用作缓存 Memcache 更合适,这里可以独立分析下其中的优劣取舍吧。Memcache 是设计为多线程的,所以在多核机器上单实例对 CPU 的利用更有效,所以它的性能天花板也更高。(见下图)要达到同样的效果,对于一个 32 核机器,你可能需要部署 32 个 Redis 实例,对运维也是一种负担。
除此,Redis 还有个 10k 问题,当缓存数据大于 10k(用作静态页面的缓存,就可能超过这个大小)延迟会明显增加,这也是单线程机制带来的问题。如果你的应用业务量离 Redis 的性能天花板还比较远而且也没有 10k 需求,那么用 Redis 作缓存也是合理的,可以让应用减少多依赖一种外部技术栈。最后,搞清楚现阶段你的应用到底需要什么,是多样的数据结构和功能、更好的扩展能力还是更敏感的性能需求,然后再来选择合适的工具吧。别只看到个基准测试的性能数据,就欢呼雀跃起来了。
额外扯点其他的,Redis 的作者 @antirez 对自己的产品和技术那是相当自信。一有人批评 Redis 的问题,他都是要跳出来在自己的 blog 里加以回应和说明的。比如有人说 Redis 功能多容易使用但也容易误用,作者就跑出来解释我设计是针对每种不同场景的,你用的不对怪我咯,怪我咯。有人说缓存场景 Memcache 比 Redis 更合适,作者也专门写了篇文章来说明,大概就是 Memcache 有的 Redis 都有,它没有的我还有。当然最后也承认多线程是没有的,但正在思考为 Redis I/O 增加线程,每个 Client 一个线程独立处理,就像 Memcache 一样,已经等不及要去开发和测试了,封住所以批评者的嘴。
Redis 这些年不断的增加新功能和优化改进,让它变得更灵活场景适应性更多的同时,也让我们在使用时需要更细致的思考,不是它有什么我就用什么,而是你需要什么你就选择什么。
这篇先到这,后面还会再写写关于 Redis 扩展方面的主题。
[1] antirez. Redis Documentation.
[2] antirez. Clarifications about Redis and Memcached.
[3] antirez. Lazy Redis is better Redis.
[4] antirez. On Redis, Memcached, Speed, Benchmarks and The Toilet.
[5] antirez. An update on the Memcached/Redis benchmark.
[6] dormando. Redis VS Memcached (slightly better bench).
[7] Mike Perham. Storing Data with Redis.
[8] 温柔一刀. Redis 常见的性能问题和解决方法.
http://www.cnblogs.com/mindwind/p/5067905.html
标签:
原文地址:http://www.cnblogs.com/softidea/p/5348802.html