标签:
---恢复内容开始---
1、为什么引入Backpressure
默认情况下,Spark Streaming通过Receiver以生产者生产数据的速率接收数据,计算过程中会出现batch processing time > batch interval的情况,其中batch processing time 为实际计算一个批次花费时间, batch interval为Streaming应用设置的批处理间隔。这意味着Spark Streaming的数据接收速率高于Spark从队列中移除数据的速率,也就是数据处理能力低,在设置间隔内不能完全处理当前接收速率接收的数据。如果这种情况持续过长的时间,会造成数据在内存中堆积,导致Receiver所在Executor内存溢出等问题(如果设置StorageLevel包含disk, 则内存存放不下的数据会溢写至disk, 加大延迟)。Spark 1.5以前版本,用户如果要限制Receiver的数据接收速率,可以通过设置静态配制参数“spark.streaming.receiver.maxRate”的值来实现,此举虽然可以通过限制接收速率,来适配当前的处理能力,防止内存溢出,但也会引入其它问题。比如:producer数据生产高于maxRate,当前集群处理能力也高于maxRate,这就会造成资源利用率下降等问题。为了更好的协调数据接收速率与资源处理能力,Spark Streaming 从v1.5开始引入反压机制(back-pressure),通过动态控制数据接收速率来适配集群数据处理能力。
2、Backpressure
Spark Streaming Backpressure: 根据JobScheduler反馈作业的执行信息来动态调整Receiver数据接收率。通过属性“spark.streaming.backpressure.enabled”来控制是否启用backpressure机制,默认值false,即不启用。
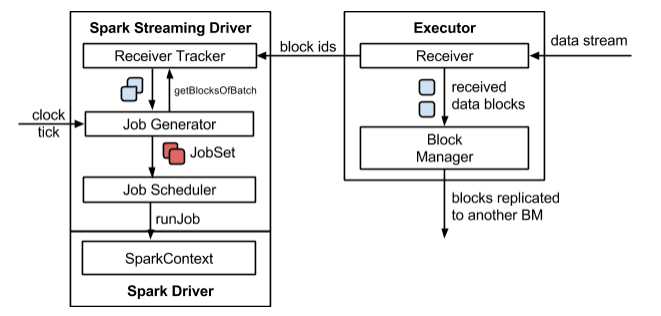
2.1 Streaming架构如下图所示(详见Streaming数据接收过程文档和Streaming 源码解析)
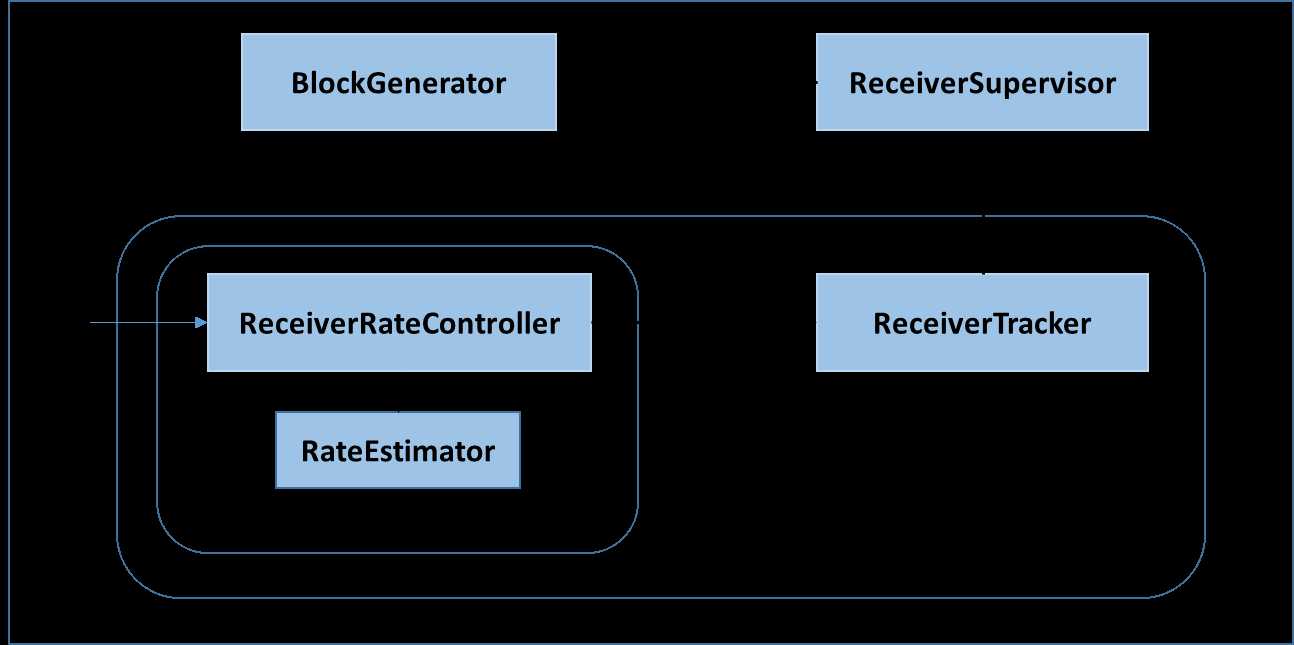
2.2 BackPressure执行过程如下图所示:
在原架构的基础上加上一个新的组件RateController,这个组件负责监听“OnBatchCompleted”事件,然后从中抽取processingDelay 及schedulingDelay信息. Estimator依据这些信息估算出最大处理速度(rate),最后由基于Receiver的Input Stream将rate通过ReceiverTracker与ReceiverSupervisorImpl转发给BlockGenerator(继承自RateLimiter).
3、BackPressure 源码解析
3.1 RateController类体系
RatenController 继承自StreamingListener. 用于处理BatchCompleted事件。核心代码为:
**
* A StreamingListener that receives batch completion updates, and maintains
* an estimate of the speed at which this stream should ingest messages,
* given an estimate computation from a `RateEstimator`
*/
private[streaming] abstract class RateController(val streamUID: Int, rateEstimator: RateEstimator)
extends StreamingListener with Serializable {
……
…… /**
* Compute the new rate limit and publish it asynchronously.
*/
private def computeAndPublish(time: Long, elems: Long, workDelay: Long, waitDelay: Long): Unit =
Future[Unit] {
val newRate = rateEstimator.compute(time, elems, workDelay, waitDelay)
newRate.foreach { s =>
rateLimit.set(s.toLong)
publish(getLatestRate())
}
}
def getLatestRate(): Long = rateLimit.get()
override def onBatchCompleted(batchCompleted: StreamingListenerBatchCompleted) {
val elements = batchCompleted.batchInfo.streamIdToInputInfo
for {
processingEnd <- batchCompleted.batchInfo.processingEndTime
workDelay <- batchCompleted.batchInfo.processingDelay
waitDelay <- batchCompleted.batchInfo.schedulingDelay
elems <- elements.get(streamUID).map(_.numRecords)
} computeAndPublish(processingEnd, elems, workDelay, waitDelay)
}
}
---恢复内容开始---
1、为什么引入Backpressure
默认情况下,Spark Streaming通过Receiver以生产者生产数据的速率接收数据,计算过程中会出现batch processing time > batch interval的情况,其中batch processing time 为实际计算一个批次花费时间, batch interval为Streaming应用设置的批处理间隔。这意味着Spark Streaming的数据接收速率高于Spark从队列中移除数据的速率,也就是数据处理能力低,在设置间隔内不能完全处理当前接收速率接收的数据。如果这种情况持续过长的时间,会造成数据在内存中堆积,导致Receiver所在Executor内存溢出等问题(如果设置StorageLevel包含disk, 则内存存放不下的数据会溢写至disk, 加大延迟)。Spark 1.5以前版本,用户如果要限制Receiver的数据接收速率,可以通过设置静态配制参数“spark.streaming.receiver.maxRate”的值来实现,此举虽然可以通过限制接收速率,来适配当前的处理能力,防止内存溢出,但也会引入其它问题。比如:producer数据生产高于maxRate,当前集群处理能力也高于maxRate,这就会造成资源利用率下降等问题。为了更好的协调数据接收速率与资源处理能力,Spark Streaming 从v1.5开始引入反压机制(back-pressure),通过动态控制数据接收速率来适配集群数据处理能力。
2、Backpressure
Spark Streaming Backpressure: 根据JobScheduler反馈作业的执行信息来动态调整Receiver数据接收率。通过属性“spark.streaming.backpressure.enabled”来控制是否启用backpressure机制,默认值false,即不启用。
2.1 Streaming架构如下图所示(详见Streaming数据接收过程文档和Streaming 源码解析)
2.2 BackPressure执行过程如下图所示:
在原架构的基础上加上一个新的组件RateController,这个组件负责监听“OnBatchCompleted”事件,然后从中抽取processingDelay 及schedulingDelay信息. Estimator依据这些信息估算出最大处理速度(rate),最后由基于Receiver的Input Stream将rate通过ReceiverTracker与ReceiverSupervisorImpl转发给BlockGenerator(继承自RateLimiter).
3、BackPressure 源码解析
3.1 RateController类体系
RatenController 继承自StreamingListener. 用于处理BatchCompleted事件。核心代码为:
**
* A StreamingListener that receives batch completion updates, and maintains
* an estimate of the speed at which this stream should ingest messages,
* given an estimate computation from a `RateEstimator`
*/
private[streaming] abstract class RateController(val streamUID: Int, rateEstimator: RateEstimator)
extends StreamingListener with Serializable {
……
…… /**
* Compute the new rate limit and publish it asynchronously.
*/
private def computeAndPublish(time: Long, elems: Long, workDelay: Long, waitDelay: Long): Unit =
Future[Unit] {
val newRate = rateEstimator.compute(time, elems, workDelay, waitDelay)
newRate.foreach { s =>
rateLimit.set(s.toLong)
publish(getLatestRate())
}
}
def getLatestRate(): Long = rateLimit.get()
override def onBatchCompleted(batchCompleted: StreamingListenerBatchCompleted) {
val elements = batchCompleted.batchInfo.streamIdToInputInfo
for {
processingEnd <- batchCompleted.batchInfo.processingEndTime
workDelay <- batchCompleted.batchInfo.processingDelay
waitDelay <- batchCompleted.batchInfo.schedulingDelay
elems <- elements.get(streamUID).map(_.numRecords)
} computeAndPublish(processingEnd, elems, workDelay, waitDelay)
}
}
3.2 RateController的注册
JobScheduler启动时会抽取在DStreamGraph中注册的所有InputDstream中的rateController,并向ListenerBus注册监听. 此部分代码如下:
Spark Streaming Backpressure分析
标签:
原文地址:http://www.cnblogs.com/barrenlake/p/5349949.html